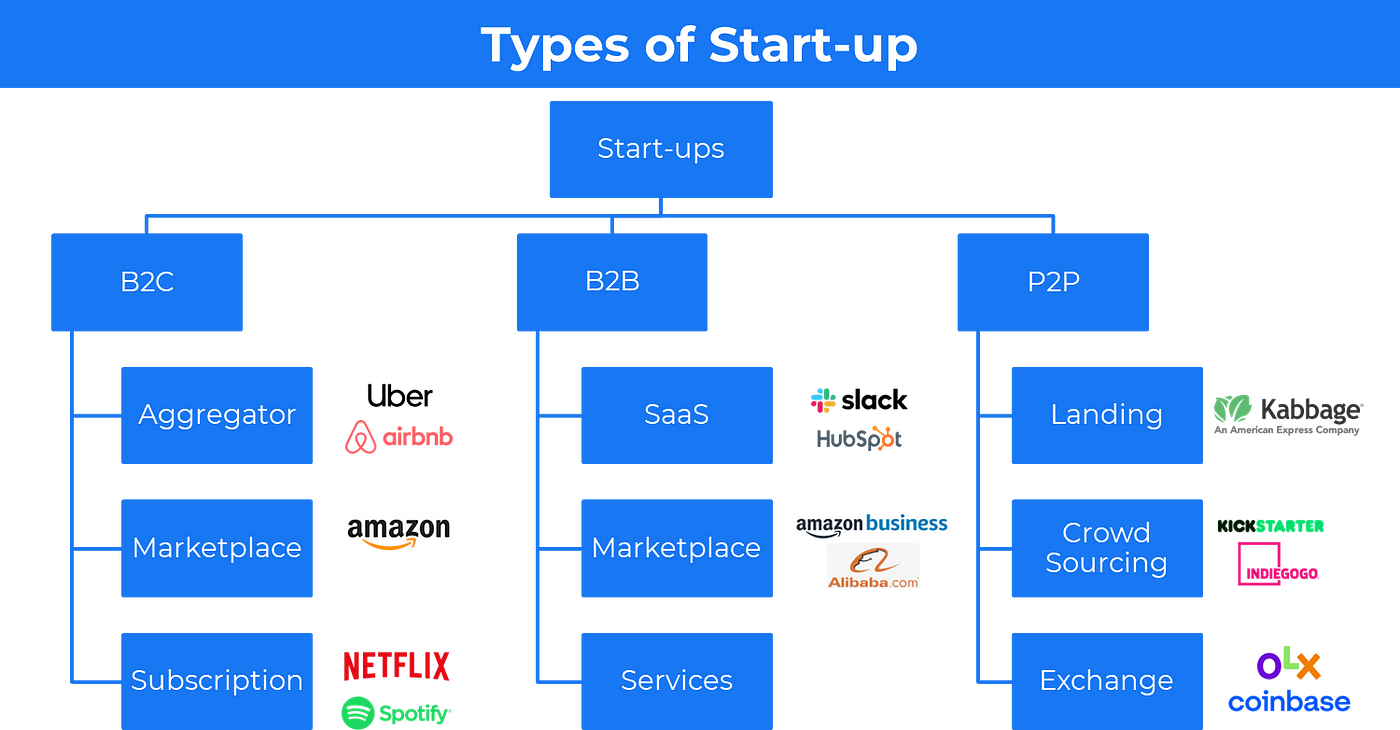
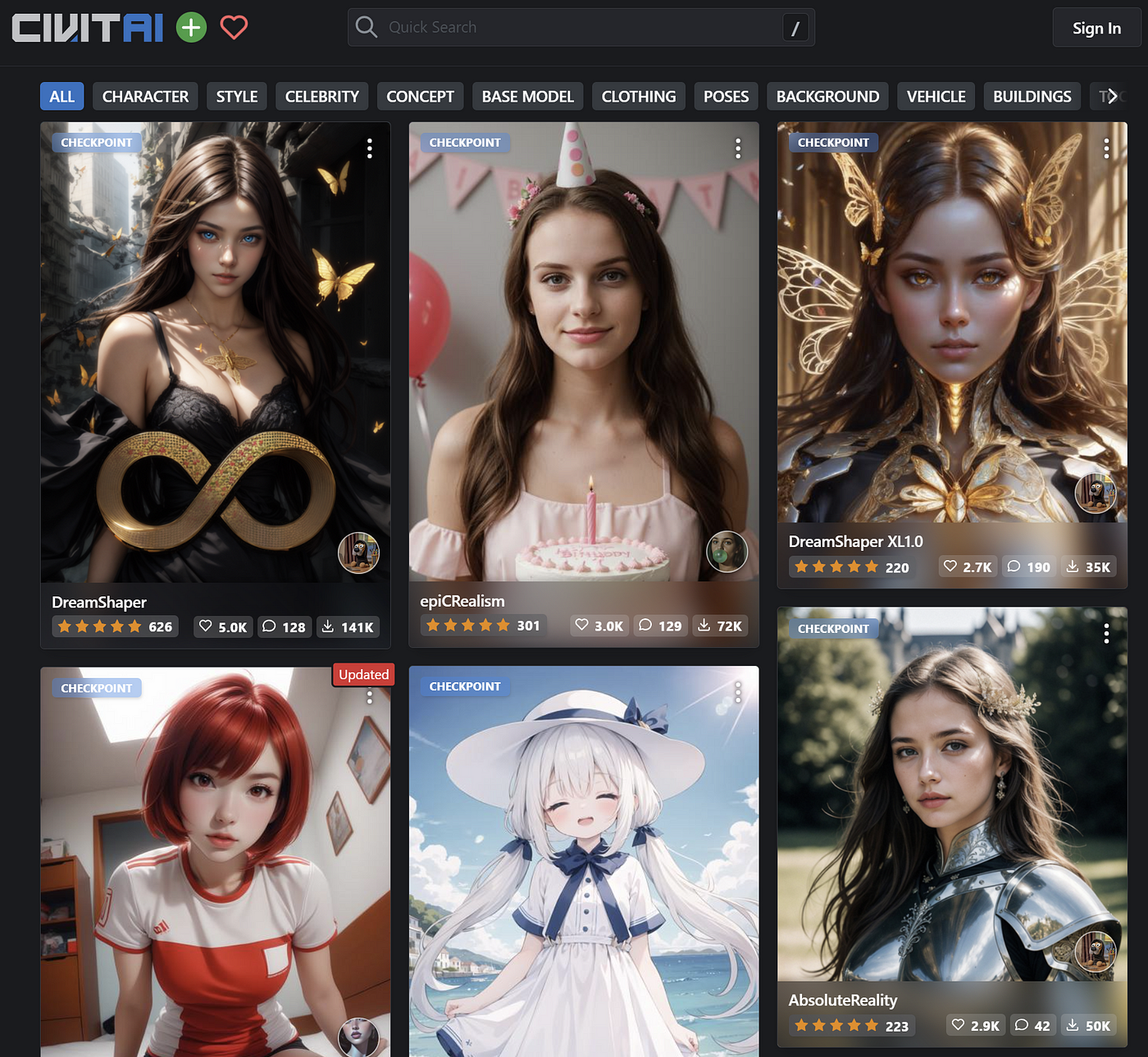
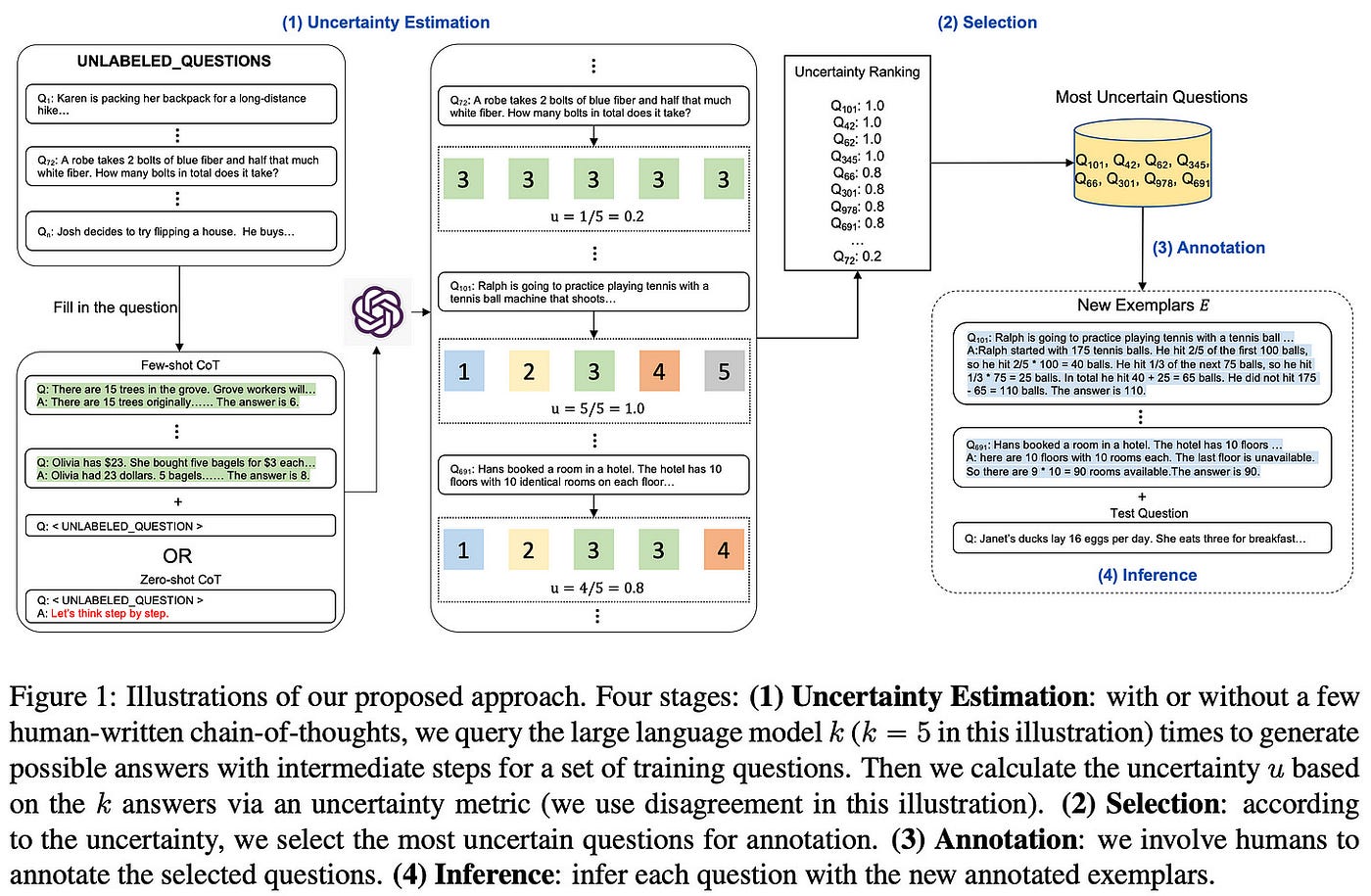
2023年Mac上的MySQL GUI客户端TOP15
- dbForge Studio for MySQL
- MySQL Workbench
- SQLPro
- Sequel Pro
- Valentina Studio
- DBeaver
- Querious
- TablePlus
- RazorSQL
- Navicat
- DataGrip
- Beekeeper Studio
- DbVisualizer
- Azure Data Studio
- DbGate
dbForge Studio for MySQL
dbForge Studio for MySQL 是一个一体化的集成开发环境,旨在简化数据库开发人员和管理员的日常工作。虽然dbForge Studio是作为经典的Windows应用程序设计的,但它目前可以通过一种名为CrossOver的特殊兼容性解决方案在macOS和Linux上使用。
优点
- 丰富的SQL开发功能,包括代码完成、格式化、重构和调试
- 如果你喜欢无编码的数据库开发和管理,你有像查询生成器和数据库设计器这样的工具,使你的工作更方便的可视化图表
- 其余的特性太长,无法在这里列出,尽管我们应该提到数据库备份、恢复、同步、迁移、正向和反向工程、用户管理以及几乎所有任务的cli自动化
- 用户界面是如此干净和直观,即使是初学者也不会迷失在众多的功能
- 多通道支持和大量额外的材料(包括文章和视频教程)
- 全面的文档,包括一个详细的指南,显示如何安装dbForge Studio for MySQL在macOS上
- 免费试用30天-足够熟悉这个IDE的巨大功能,看看它是否真的是你需要的
- 或者,您可以使用dbForge Studio的免费Express Edition,它提供基本功能
缺点
- 在没有安装CrossOver之前,你将无法使用dbForge Studio。但是一旦壮了CrossOver,安装和配置过程还是相当简单
- 高级功能仅在付费版本中可用
- dbForge Studio for MySQL只支持MySQL和MariaDB;然而,你可以分别获得类似的SQL Server, Oracle和PostgreSQL数据库的Studios。

MySQL Workbench
MySQL Workbench可能是MySQL数据库开发人员、架构师和分析师的默认(如果不是最终的)GUI客户端。与macOS、Windows和Linux兼容,它包含了一个很好的数据库设计和管理工具选择,这肯定会简化您的日常工作。
优势
- 与之前的客户端类似,您可以获得帮助您可视化地构建查询和使用任何复杂的ER图设计数据库的工具
- 智能代码补全
- 高级数据建模工具
- 所有的管理基础都牢固到位,包括用户管理,服务器配置和监控,数据库备份和恢复,以及数据迁移
- 这是一个免费的,非常受欢迎的产品,有一个大的社区
缺点
- UI比普通用户想要的更复杂;因此,即使是简单的任务,如数据传输过程,也可能变得相当复杂
- 资源消耗过多
SQLPro
SQLPro是一个免费的(但有几个付费选项)macOS的MySQL管理器,它可以快速访问表和视图,提供类似intellisense的自动完成,格式化和语法高亮显示,支持多个结果集和基于选择的查询执行,以及包括一个表设计器,可以轻松修改列,索引,外键和触发器。
优势
- 原生应用程序
- 美观,直观的界面
- 易于管理多个结果集
缺点
- 总的来说,功能是相当有限的,但是如果您不需要一个包罗万象的工具包,您可以考虑这个选项
- 没有文档
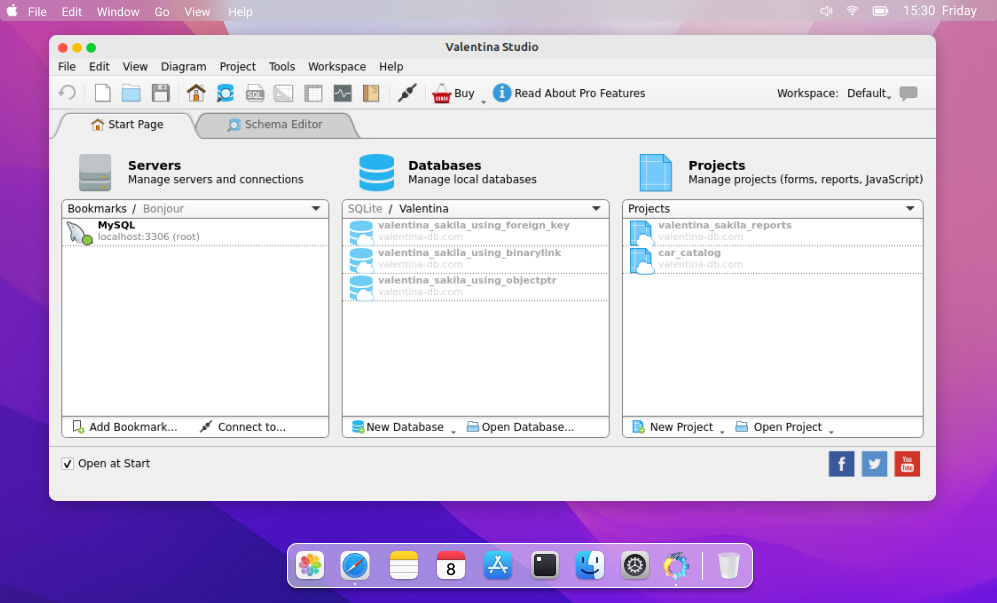
Valentina Studio
Valentina Studio是一个多平台GUI工具,用于轻松管理MySQL, MariaDB, SQL Server, SQLite, PostgreSQL和(他们自己的)Valentina DB数据库。最需要的功能包括可视化查询构建和数据库建模、简单但有用的数据编辑器、报表设计器、源表和目标表之间的快速数据传输、模式比较和基本的数据库管理。
优势
- 易于处理多个数据库管理系统
- 方便的导航和快速的数据搜索
- 强大的报表设计器与丰富的功能
- Valentina Studio的免费版已经相当有能力了,3个付费版本在此基础上进一步改进
缺点
- 无技术支持
- 相当不发达的文档
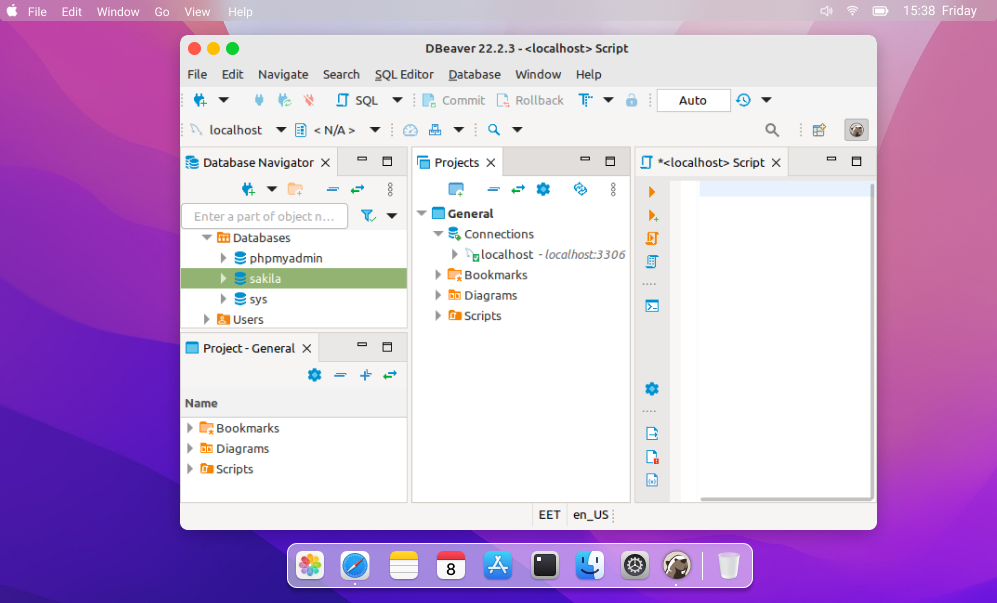
DBeaver
现在让我们回到更熟悉的标题。DBeaver是一个支持多个数据库管理系统的多平台IDE。它功能强大,用户友好,并且它的社区版是免费的。DBeaver最流行的特性是SQL查询编辑器、可视化查询生成器、数据库比较工具、测试数据生成器和ER图。dbeaver还有更多的东西要做——它的团队帮助它积极地发展。如果您是一个要求苛刻的用户,您绝对应该探索这个选项。
优势
- 多用户环境,灵活的访问管理
- 高级数据编辑器
- 可视化查询生成器是一个经过验证的解决方案,适合那些喜欢处理图表查询的人
- 可定制的结果集管理
- 灵活的比较数据库对象与不同的结果表示
- 生成虚拟数据
- 完整的文件
缺点
- 免费版中没有支持服务
- 弱数据可视化功能
- 数据导入导出流程复杂
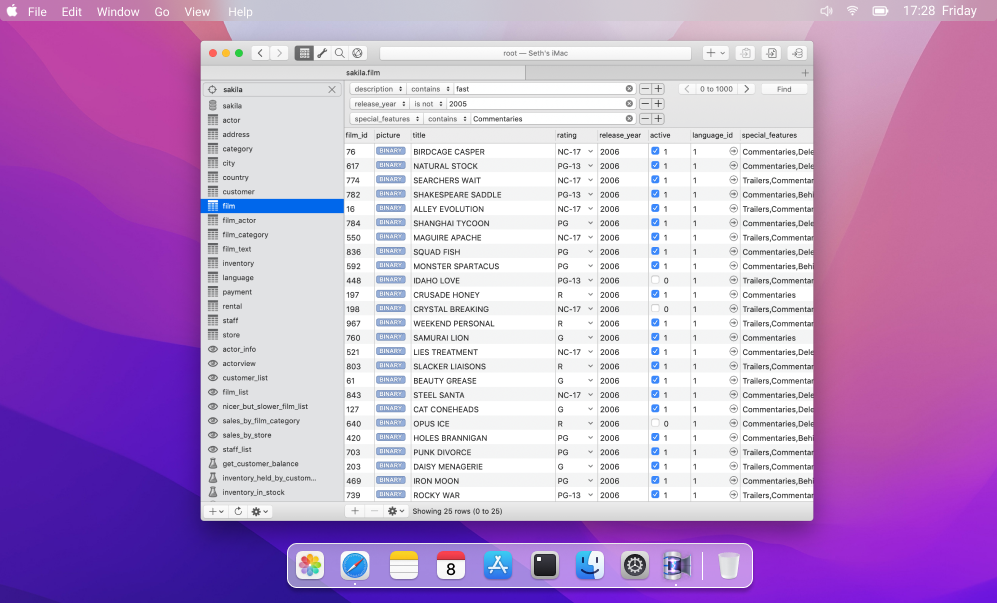
Querious
Querious是一个仅限MacOS的商业CUI客户端,用于MySQL和兼容数据库。在一个干净的界面下,您将找到一个具有中等强大查询功能的解决方案,以及用于数据库对象编辑、服务器管理和易于配置的数据库结构比较的精选工具。
优势
- 原生的macOS体验确实非常不错,性能也非常稳定
- 使您的查询变得方便的基础—例如自动补全、格式化和语法高亮—您在这里已经具备了
- 所有类型数据库对象的编辑器
- 丰富的数据库管理和服务器管理工具
- 支援服务
- 这是一个非常实惠的解决方案,免费试用30天
缺点
- 就像上面描述的几个情况一样,这是一个中等能力的解决方案,但不是一个一体化的解决方案;好消息是,在购买之前,你有很多时间去探索它
- 没有文档
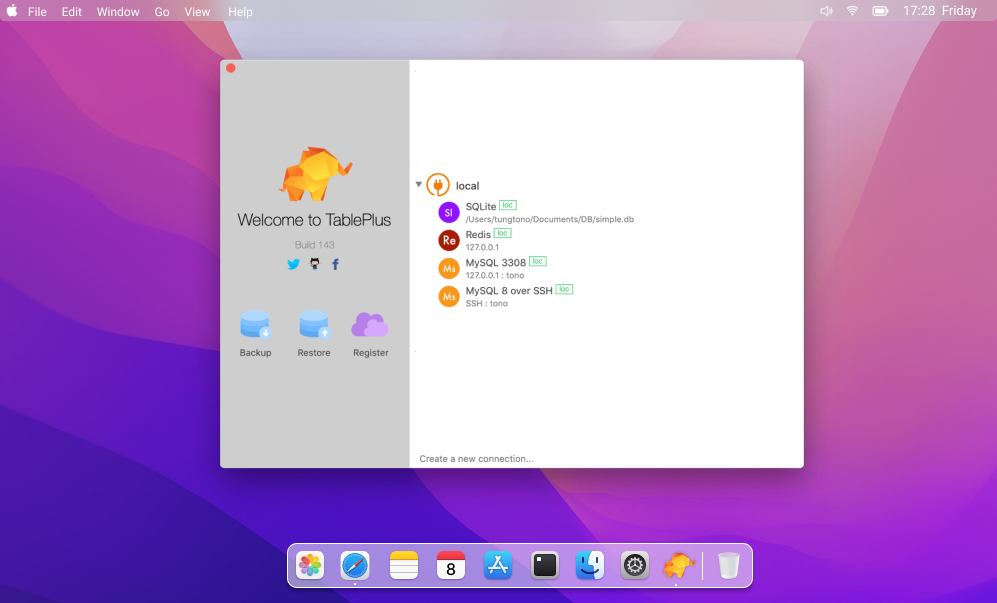
TablePlus
TablePlus是一个美观的多平台GUI工具,可以帮助您处理众多数据库系统中的数据。然而,请注意TablePlus的主要杀手级功能是它的智能查询编辑器,它具有语法高亮显示、即时自动补全、SQL格式化和数据编辑功能。剩下的就取决于它是否是你关注的焦点。
优势
- 干净和简单的用户界面
- 每个平台上流畅的原生体验
- 良好的文档
- 如果免费版的TablePlus对你来说还不够,那么付费的许可证还是相当实惠的
缺点
- TablePlus的功能与SQL查询和数据编辑很好地对齐,但在所有其他方面相当有限;如果您主要需要浏览、编辑和查询数据,请查看它
RazorSQL
RazorSQL是一个易于使用的SQL查询工具,已经在40多个数据库管理系统上进行了测试,包括MySQL。它的主要特性包括方便的数据库浏览器、可视化数据库工具、SQL查询构建器、SQL编辑器以及数据导入、导出和比较功能。
优势
- 列表中功能更全面的条目之一
- 庞大的数据库系统覆盖
- 精心设计的用户界面
- 帮助创建、修改、描述、执行和删除数据库对象的可视化工具
- 查询的多表格显示,具有过滤、排序、搜索和其他操作的功能
- CLI支持
- 详细的文件
- 免费试用30天
缺点
- 虽然RazorSQL提供了相当多的功能,但您必须仔细检查每个功能是否足够高级,以满足您的需求和要求。
Navicat
Navicat是一个通用的数据库开发和管理解决方案,支持大多数流行的数据库管理系统和云平台。有了它的帮助,您可以轻松地设计和管理整个数据库和特定的数据库对象、迁移数据、比较和同步数据库、构建查询以及执行逆向工程。
优势
- 设计良好的GUI
- 方便的数据库对象设计器
- 优秀的SQL编辑器
- 可视化数据库设计和建模
- 强大的数据库比较功能
- 方便的任务自动化功能(仅可与dbForge Studio for MySQL相比)
缺点
- 这是一个相当昂贵的解决方案
- 14天的试用期对于IDE来说相当短
- 文档需要一些扩展
DataGrip
DataGrip是一个智能的基于订阅的IDE,用于许多数据库任务。它为数据库开发人员、管理员和分析人员提供了大量集成工具,帮助您处理查询并提供灵活的数据库对象管理。
优势
- 广泛支持的数据库管理系统
- 智能建议和重构
- 版本控制集成
- 高效导航
- 集成数据连接器
- 广泛的文档与教程
- 免费试用30天
缺点
- 复杂的学习曲线
- 资源占用过多
Beekeeper Studio
现在让我们继续一些更直接,但有趣的事情。Beekeeper Studio是一个免费开源的基于gui的数据库管理器和SQL代码编辑器,适用于MySQL、PostgreSQL、SQLite和SQL Server数据库。该工作室的创建者专注于使其尽可能用户友好和简单。如果您的主要工作涉及查询,并且不会超出查询范围,则可以查看它。
优势
- 简单的用户界面
- 良好的SQL编辑器功能,包括自动补全和语法高亮显示
- 可查询的查询历史
- SSL连接加密
缺点
- 有限的功能(不是一个缺点,因为它是一个编辑器,而不是高级用户的IDE,你应该这样对待它)
- 无支持服务
- 没有文档
DbVisualizer
DbVisualizer是一款智能且重点突出的SQL编辑器和数据库管理器,作为在G2上拥有最高客户满意度评级的数据库客户端进行营销。它确实是一个非常有用的解决方案,使您能够使用SQL代码,访问和探索数据库以及操作数据。DbVisualizer有免费版和专业版,后者是用许可密钥激活的。
优势
- 美观的用户界面
- 庞大的数据库系统覆盖
- 高级SQL编辑器,自动格式化和建议
- 注重安全(支持SSH数据加密和安全访问)
- 良好的定制
- CLI支持
缺点
- 有时很难跟随潮流或找到正确的选择,这使得它不是初学者的最佳解决方案
- 有时会很慢
- 对于它提供的功能集来说,它也有点贵
Azure Data Studio
我们榜单上最后一个真正的大牌是微软的Azure Data Studio。它是一个跨平台工具,适用于在Windows、macOS和Linux上使用本地和云数据平台的数据专业人员。虽然SQL Server是Azure Data Studio的关键DBMS,你也可以使用一个特殊的扩展连接到MySQL数据库。Studio提供了一个现代的编辑器体验,包括IntelliSense补全、代码片段、源代码控制集成、集成终端、内置查询结果集图表和可定制的仪表板。
优势
- 干净和直观的界面,从微软Visual Studio的提示
- 相当强大的一套功能的免费产品
- 与Azure数据服务无缝集成
- 有扩展,给访问新的功能和额外的服务
- 优秀的文档、支持服务和大型社区
缺点
- 虽然Azure Data Studio是一款高级产品,但也有一些ide可以更深入地实现可视化数据库设计和查询构建、表设计、服务器管理和数据库管理
DbGate
最后,让我们来概述一下DbGate——一个免费的、跨平台的、跨数据库的GUI客户端,涵盖基于sql和NoSQL的系统。它允许连接到多个数据库,浏览和编辑表模式和实际数据,编写带有自动完成功能的SQL查询,可视化地构建查询,以及基于数据创建ER图表、图表和地图。把它当作一个没有野心的数据库管理器,以满足macOS用户的基本需求。
优势
- 一个很好的一组功能的免费工具
- 支持多种数据库(包括NoSQL)
- 可用的导入/导出格式可以扩展自定义插件
缺点
- 没有一个可用的功能可以与这个列表中更高级的条目竞争,但我们猜这是不言而喻的;然而,这可能正是你正在寻找的
总结
还不确定哪个客户最适合你?没关系。至少现在你可以更精确地勾勒出你的需求和要求,并记下可以决定你最终选择的优点和缺点指标。无论您是MySQL新手还是经验丰富的专家,让我们重申全面的文档、活跃的社区、可靠的技术支持以及可用的额外材料的重要性,这些都将教会您如何最有效地处理基本任务。