from azure.cognitiveservices.vision.computervision import ComputerVisionClient from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes from msrest.authentication import CognitiveServicesCredentials
from array import array import os from PIL import Image
# Call the "GET" API and wait for it to retrieve the results whileTrue: read_result = computervision_client.get_read_result(operation_id) if read_result.status notin ['notStarted', 'running']: break time.sleep(1)
layout = [] if read_result.status == OperationStatusCodes.succeeded: for text_result in read_result.analyze_result.read_results: for line in text_result.lines: layout.append({line.text:line.bounding_box}) print(layout) print("End of Computer Vision.") return layout
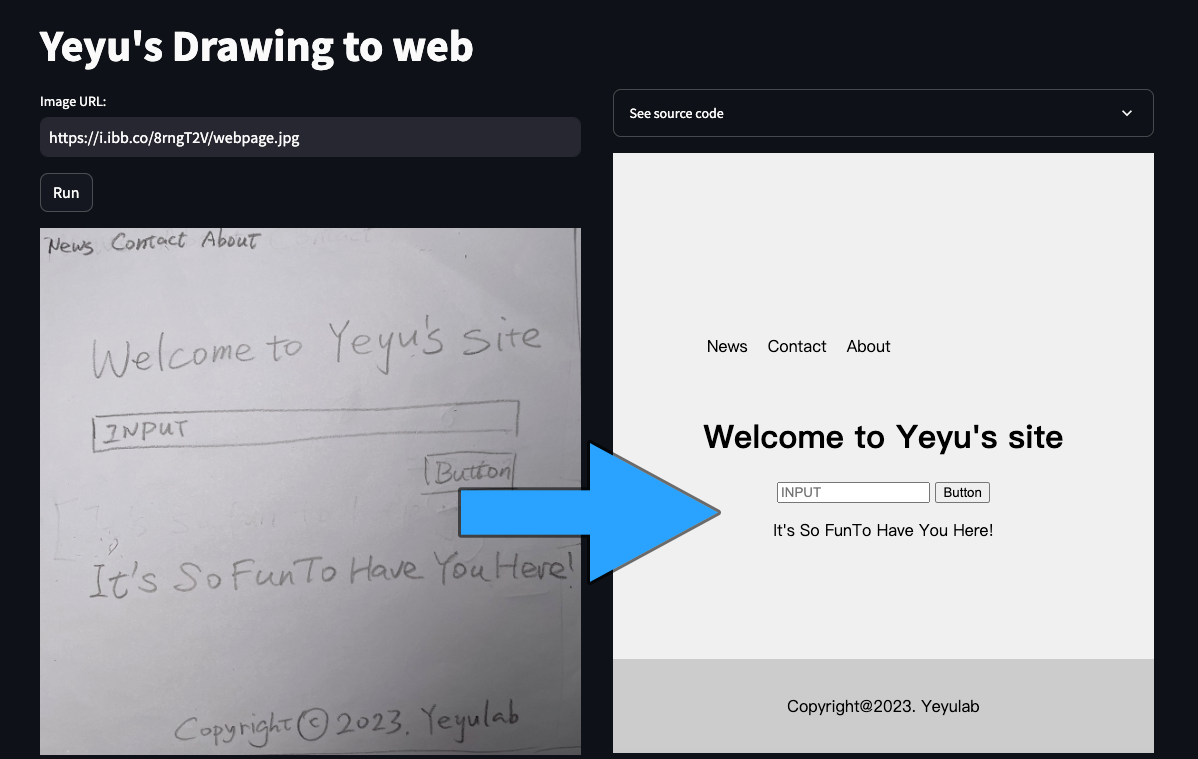
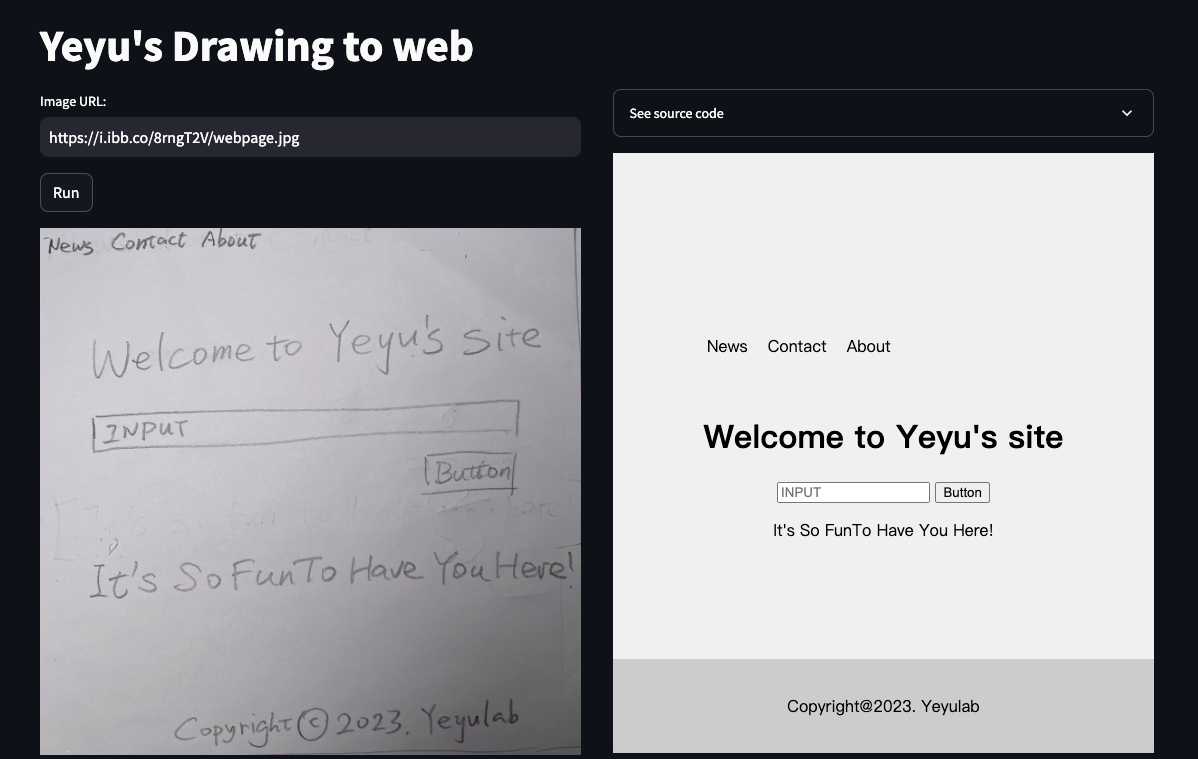
[{'News Contact About':[11.0,32.0,979.0,7.0,982.0,97.0,13.0,123.0]}, {'Welcome to Yeyu's site':[216.0,483.0,2210.0,373.0,2222.0,558.0,227.0,675.0]}, {'INPUT':[262.0,847.0,658.0,824.0,664.0,938.0,264.0,958.0]}, {'Button':[1713.0,1021.0,2084.0,1011.0,2089.0,1127.0,1713.0,1140.0]}, {'It's So FunTo Have You Here!':[217.0,1463.0,2348.0,1420.0,2350.0,1585.0,222.0,1651.0]}, {'Copyright@2023. Yeyulab':[586.0,2146.0,2123.0,2069.0,2129.0,2224.0,591.0,2297.0]}]
defhtml_gen(layout): prompt = PromptTemplate( template="""This is a layout of a handwriting website design, including text and their coordinates of four outer vertices. Make an HTML modern sans-serif website that reflects these elements and decide which CSS can be used to match their relative positions, try to use proper layout tags to match their font size and relative placement based on their coordinates. Use <ul> and <li> if the elements look like as menu list. Smartly use function tags like <button> <input> if their names look like that. Your design should be prior to the coordinates, then you should also use some imagination for the layout and CSS from common web design principle. Remember, don't use absolute coordinates in your HTML source code. Generate only source code file, no description: {layout}.\n""", input_variables=["layout"] ) llm = ChatOpenAI(model="gpt-4-0613",temperature=0) chain = LLMChain(prompt=prompt, llm=llm) output = chain.run(layout=layout) print(output)
return output
最关键的部分是prompt模板,其中包含许多关于每个元素的文本位置的说明,并强调样式。
c) Streamlit
作为最后一步,我们应该使用Streamlit和它的小部件将所有这些功能包装成一个流畅的用户交互。
让我们先安装Streamlit。
1
!pip install streamlit
导入Streamlit包和组件类。
1 2
import streamlit as st import streamlit.components.v1 as components