介绍
如此多有价值的信息被困在PDF和图像文件中。幸运的是,我们拥有强大的大脑,能够处理这些文件以找到特定的信息,这实际上很棒。
但是,我们当中有多少人在内心深处不希望有一个工具可以回答关于给定文档的任何问题?
这就是本文的全部目的。我将逐步解释如何构建一个可以与任何pdf和图像文件聊天的系统。
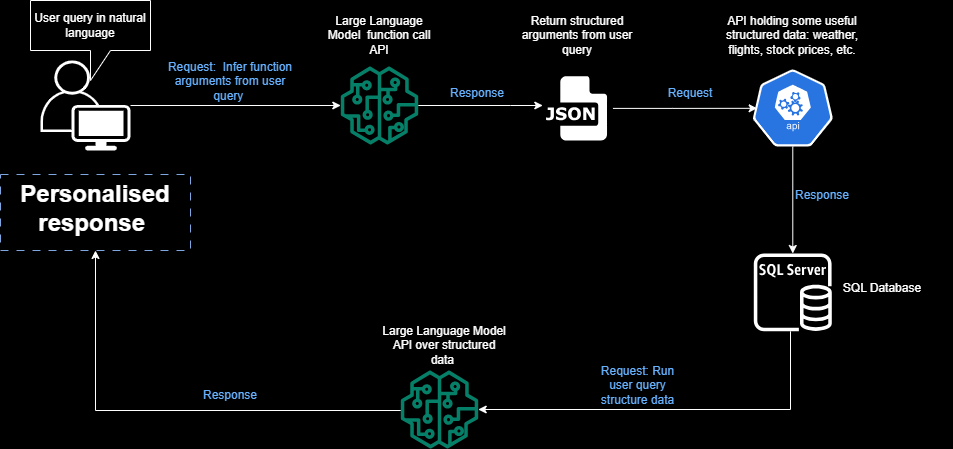
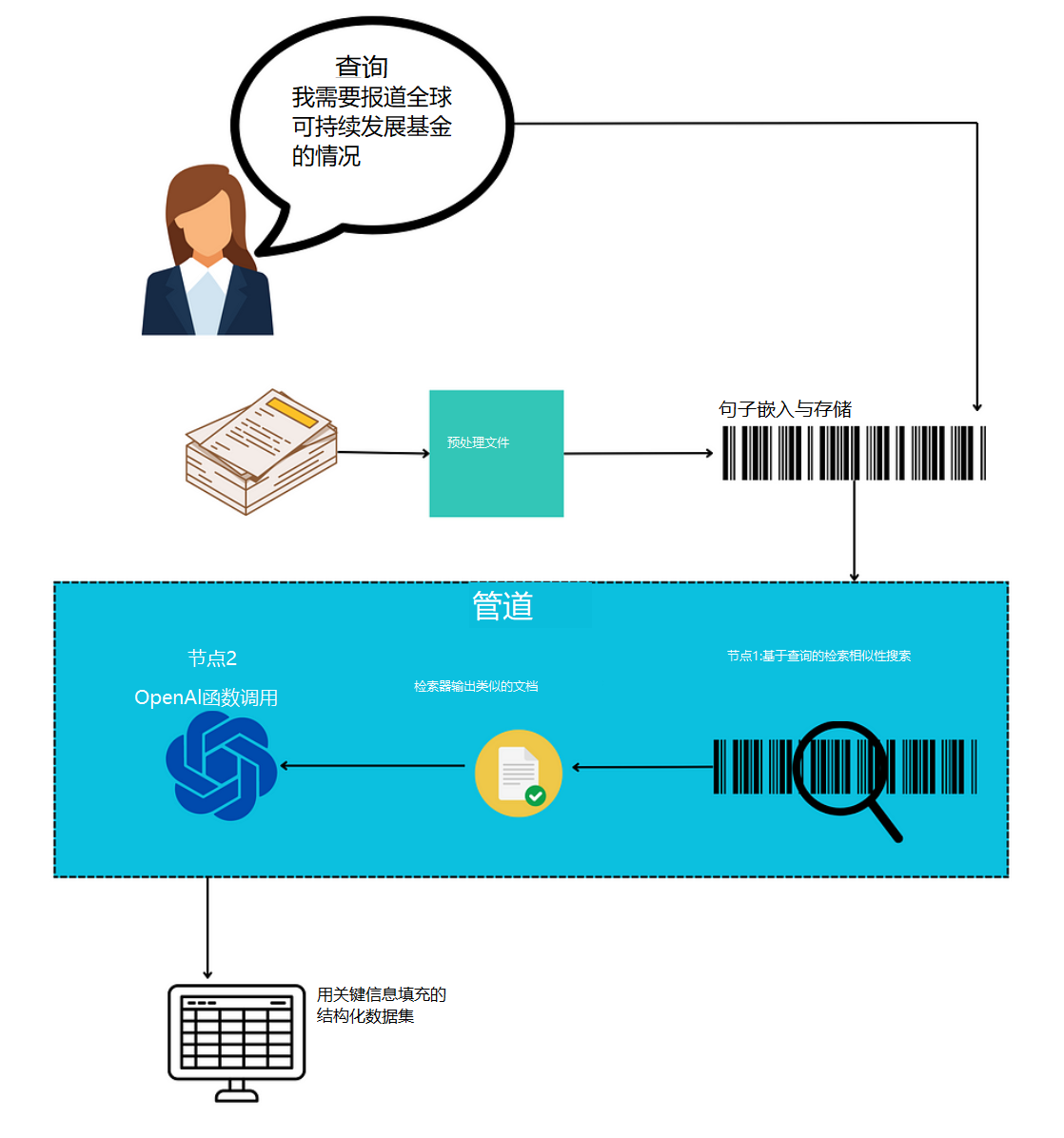
项目的一般工作流程
对正在构建的系统的主要组件有一个清晰的理解总是好的。让我们开始吧。
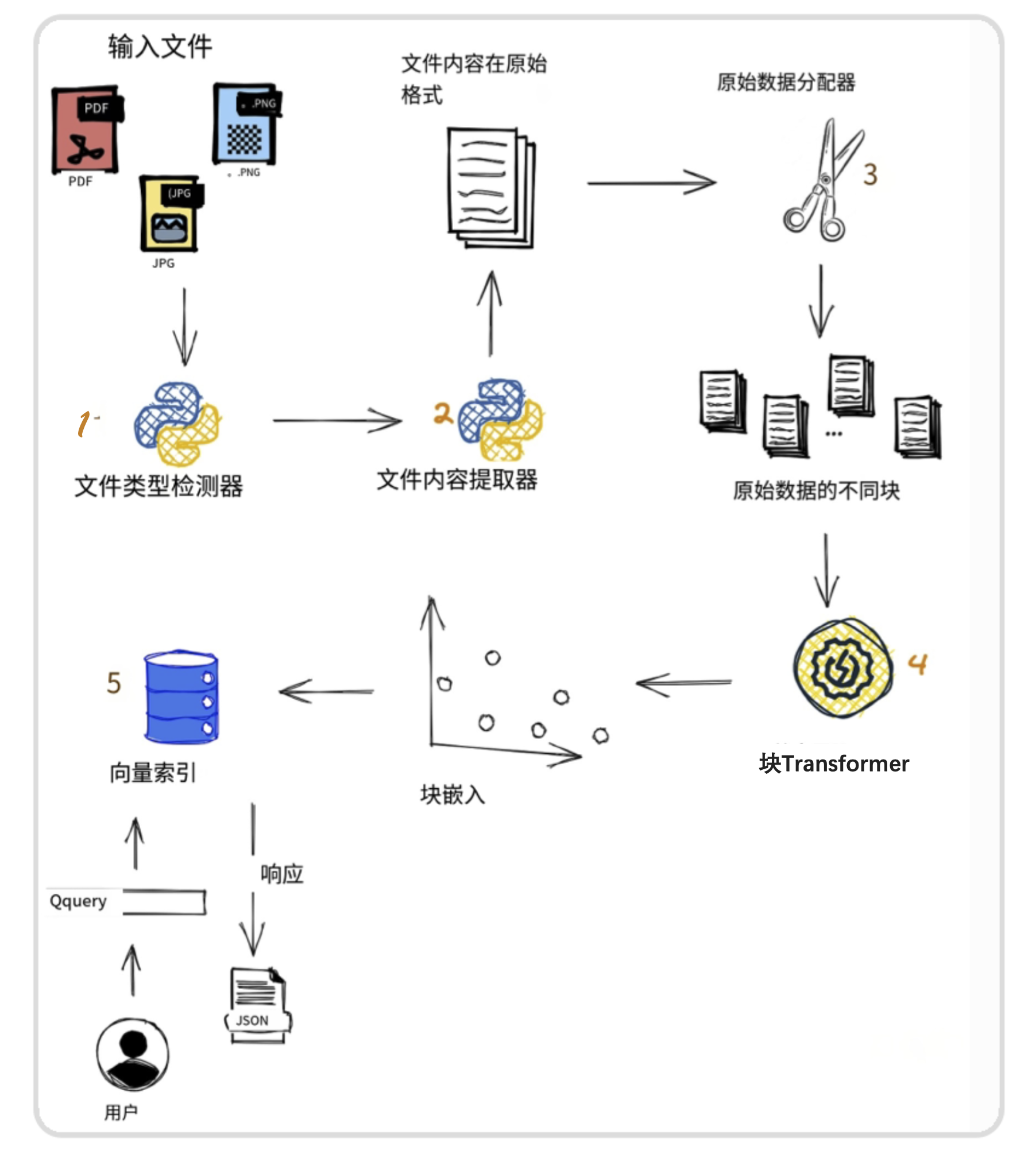
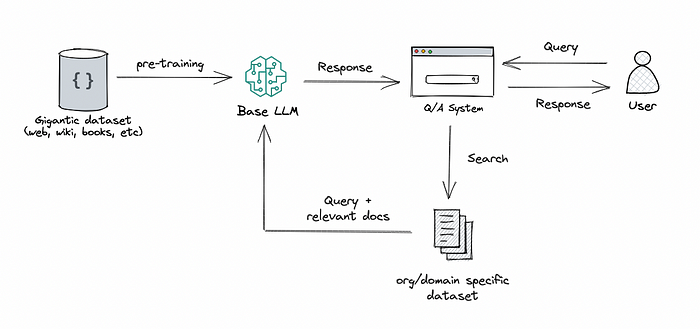
- 首先,用户提交待处理的文档,文档可以是PDF格式,也可以是图像格式。
- 第二个模块用于检测文件的格式,以便应用相关的内容提取功能。
- 然后使用
Data Splitter模块将文档的内容分割成多个块。 - 这些块最终使用
Chunk Transformer转换成Embeddings,然后将它们存储在矢量存储中。 - 在流程结束时,用户的查询用于查找包含该查询答案的相关块,并将结果作为JSON返回给用户。
1. 检测文档类型
对于每个输入文档,将根据其类型(无论是PDF还是image)应用特定的处理。
这可以通过辅助函数detect_document_type 与内置Python模块中的guess 函数相结合来实现。
1 | def detect_document_type(document_path): |
现在我们可以在两种类型的文档上测试这个函数:
transformer_paper.pdf是Transformers研究论文来自Arxiv。zoumana_article_information.png是图像文档,包含有关我在Medium上覆盖的主要主题的信息。
1 | research_paper_path = "./data/transformer_paper.pdf" |
输出:

成功检测到的文件类型(图片按作者)
这两种文件类型都被detect_document_type函数成功检测到。
2. 根据文档类型提取内容
langchain库提供了不同的模块来提取给定类型文档的内容。
UnstructuredImageLoader提取图像内容。UnstructuredFileLoader提取任何pdf和Txt文件的内容。
我们可以将这些模块与上面的detect_document_type 函数结合起来实现文本提取逻辑。
这些模块可用于在extract_file_content函数中实现端到端的文本提取逻辑。
让我们看看他们的行动吧!
1 | from langchain.document_loaders.image import UnstructuredImageLoader |
现在,让我们打印每个文件内容的前400个字符。
1 | research_paper_content = extract_file_content(research_paper_path) |
输出:
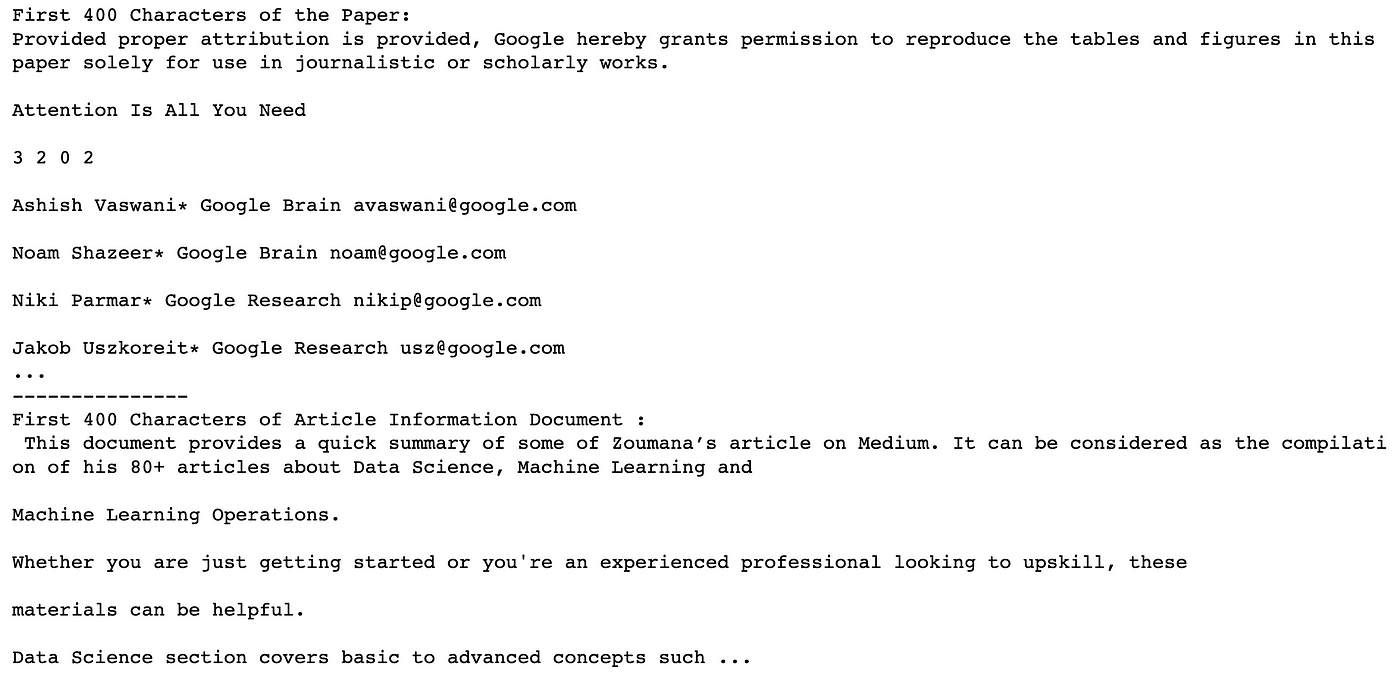
上述文件的前400个字符如下:
- 研究论文内容以
Provided proper attribution is provided开始,以Jacod Uszkoreit* Google research usz@google.com结束。 - 图像文档的内容以
This document provides a quick summary开始,并以Data Science section covers basic to advance concepts结束。
3. Chat实现
输入文档被分割成块,然后在实现问答逻辑之前为每个块创建Embedding。
a. 文档组块
块表示较大文本的较小部分。这个过程对于确保一段内容以尽可能少的噪音表示,使其具有语义相关性至关重要。
可以应用多种分块策略。
例如,我们有NLTKTextSplitter、 SpacyTextSplitter,、RecursiveCharacterTextSplitter, CharacterTextSplitter等等。
每一种策略都有其优缺点。
本文的主要重点是CharacterTextSplitter,它基于\n\n从输入文档中创建块,并通过其字符数测量每个块的长度(length_function)。
1 | text_splitter = CharacterTextSplitter( |
chunk_size告诉我们希望每个块中最多有1000个字符,较小的值将产生更多的块,而较大的值将产生更少的块。
需要注意的是,选择chunk_size的方式会影响整体结果。因此,一个好的方法是尝试不同的值,并选择更适合自己用例的值。
此外,chunk_overlap意味着我们希望在连续块之间最多有200个重叠字符。
例如,假设我们有一个包含文本Chat with your documents using LLMs的文档,并希望使用Chunk Size = 10和Chunk overlap = 5来应用分块。
这个过程如下图所示:
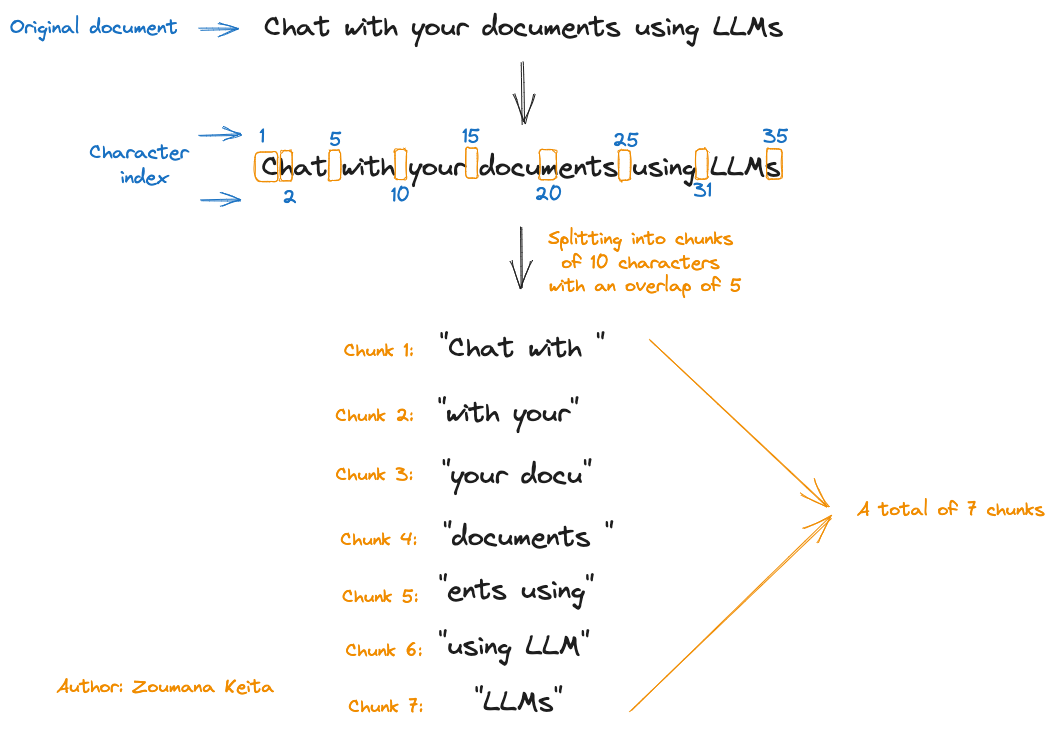
我们可以看到,对于35个字符(包括空格)的输入文档,我们最终得到了总共7个块。
但是,我们为什么要首先使用这些重叠呢?
包括这些重叠, CharacterTextSplitter确保在块之间维护底层上下文,这在处理长段文档时特别有用。
与chunk_size类似,chunk_overlap没有固定值。需要测试不同的值,以选择效果更好的值。
现在,让我们看看它们在我们的场景中的应用:
1 | research_paper_chunks = text_splitter.split_text(research_paper_content) |
输出:

对于像研究论文这样的大型文档,我们有更多的块(51),而一页的文章文档只有2个。
b. 创建块的Embeddings
我们可以使用OpenAIEmbeddings模块,它默认使用text-embedding-ada-002 模型来创建块的Embedding。
而不是使用text-embedding-ada-002可以使用不同的模型(例如:gpt-3.5-turbo-0301),通过改变以下参数:
- model = “
gpt-3.5-turbo-0301“ - deployment = “
<DEPLOYMENT-NAME>“,对应于模型部署期间给出的名称。默认值也是text- embeddings -ada-002
为了简单起见,我们将在本教程中坚持使用默认参数的值。但在此之前,我们需要获得OpenAI凭据,下面的文章提供了所有步骤。
1 | from langchain.embeddings.openai import OpenAIEmbeddings |
c. 创建文档搜索
为了获得给定查询的答案,我们需要创建一个向量存储,用于查找与该查询最接近的匹配块。
这样的矢量存储可以使用FAISS模块中的from_texts函数来创建,该函数有两个主要参数:text_splitter和Embeddings,这两个参数都是前面定义的。
1 | from langchain.vectorstores import FAISS |
通过在研究论文块上运行get_doc_search,我们可以看到结果是vectorstores。如果我们使用article_information_chunks,结果将是相同的。
1 | doc_search_paper = get_doc_search(research_paper_chunks) |
输出:
d. 开始和你的文件聊天
祝贺你走了这么远!
chat_with_file函数用于通过组合上述所有函数以及similarity_search函数来实现聊天的端到端逻辑。
最后一个函数接受两个形参:
- 我们想要聊天的文件,还有
- 用户提供的查询
1 | from langchain.llms import OpenAI |
让我们退一步来正确理解上面代码块中发生的事情。
load_qa_chain提供了一个接口,用于在一组文档上执行问答。在这个特定的情况下,我们使用默认的OpenAI GPT-3大型语言模型。chain_type为map_rerank。通过这样做,load_qa_chain函数根据链给出的置信度分数返回答案。还有其他的chain_type可以使用,比如map_reduce,stuff,refine等等。每个人都有自己的优点和缺点。- 通过设置
return_intermediate_steps=True,我们可以访问元数据,如上述置信度评分。
它的输出是一个包含两个键的字典:查询的答案和信心得分。
我们终于可以和我们的文件聊天了,从图像文档开始:
- 与图像文档聊天
为了与图像文档进行对话,我们提供了文档的路径,以及我们希望模型回答的问题。
1 | query = "What is the document about" |
输出:

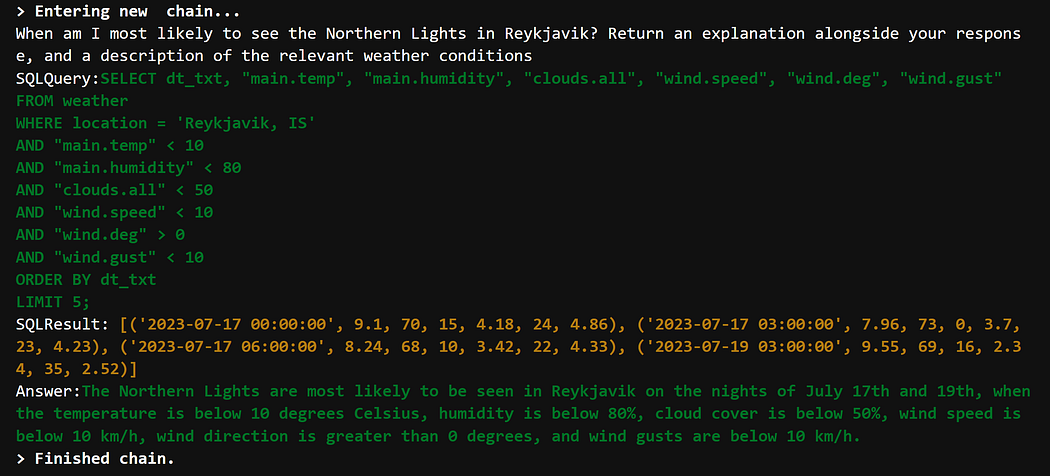
该模型对其响应有100%的信心。通过查看下面原始文档的第一段,我们可以看到模型响应确实是正确的。

最有趣的部分之一是,它提供了文档中涵盖的主要主题的简要摘要(统计、模型评估指标、SQL查询等)。
- 与PDF文件聊天
PDF文件的处理过程与上一节中的过程类似。
1 | query = "Why is the self-attention approach used in this document?" |
输出:
我们再一次从模型中得到了100%的置信度。这个问题的答案看起来非常正确!

在这两种情况下,该模型都能在几秒钟内做出类似人类的反应。让一个人完成同样的过程需要几分钟,甚至几个小时,这取决于文档的长度。
本文的Github地址
原文:How to Chat With Any PDFs and Image Files Using Large Language Models — With Code