# Prompt to generate questions qa_generate_prompt_tmpl = """\ Context information is below. --------------------- {context_str} --------------------- Given the context information and not prior knowledge. generate only questions based on the below query. You are a Professor. Your task is to setup \ {num_questions_per_chunk} questions for an upcoming \ quiz/examination. The questions should be diverse in nature \ across the document. The questions should not contain options, not start with Q1/ Q2. \ Restrict the questions to the context information provided.\ """ llm = Anthropic(api_key=anthropic_api_key) qa_dataset = generate_question_context_pairs( nodes, llm=llm, num_questions_per_chunk=2 )
过滤句子的功能,比如— Here are 2 questions based on provided context
# function to clean the dataset deffilter_qa_dataset(qa_dataset): """ Filters out queries from the qa_dataset that contain certain phrases and the corresponding entries in the relevant_docs, and creates a new EmbeddingQAFinetuneDataset object with the filtered data. :param qa_dataset: An object that has 'queries', 'corpus', and 'relevant_docs' attributes. :return: An EmbeddingQAFinetuneDataset object with the filtered queries, corpus and relevant_docs. """
# Extract keys from queries and relevant_docs that need to be removed queries_relevant_docs_keys_to_remove = { k for k, v in qa_dataset.queries.items() if'Here are 2'in v or'Here are two'in v }
# Filter queries and relevant_docs using dictionary comprehensions filtered_queries = { k: v for k, v in qa_dataset.queries.items() if k notin queries_relevant_docs_keys_to_remove } filtered_relevant_docs = { k: v for k, v in qa_dataset.relevant_docs.items() if k notin queries_relevant_docs_keys_to_remove }
# Create a new instance of EmbeddingQAFinetuneDataset with the filtered data return EmbeddingQAFinetuneDataset( queries=filtered_queries, corpus=qa_dataset.corpus, relevant_docs=filtered_relevant_docs )
# filter out pairs with phrases `Here are 2 questions based on provided context` qa_dataset = filter_qa_dataset(qa_dataset)
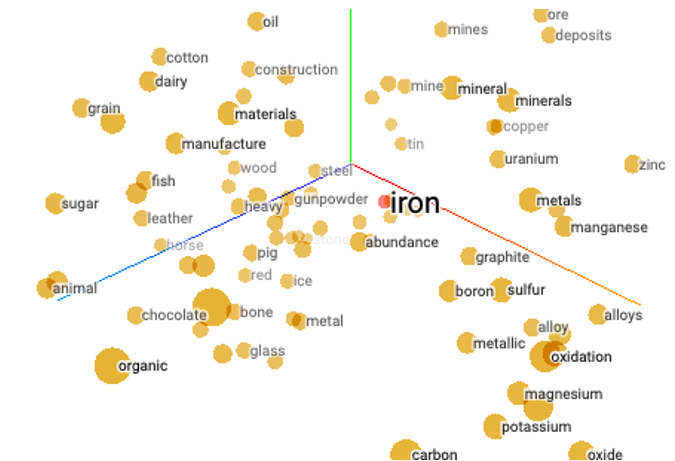
让我们首先描述一下单词Embeddings。2014年,一个突破性的想法Word2Vec(发音为“Word - to - Vector”)在自然语言处理中被提出,它将单词或短语转换或“嵌入”为数字的高维向量,称为单词Embeddings。这些词Embeddings捕捉词之间的语义和上下文关系,使机器能够理解和使用人类语言。图1显示了三维空间中的高维向量。“铁(iron)”这个词与“火药(gunpowder)”、“金属(metals)”和“钢(steel)”等词很接近,但与“有机(organic)”、“糖(sugar)”或“谷物(grain)”等不相关的词相去甚远。例如,猫和狗的概念可能很接近。
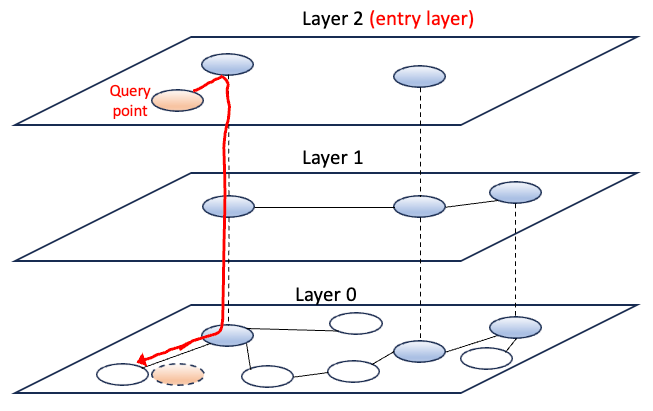
ANN (Approximate Nearest Neighbors)对大数据进行预索引,方便快速搜索。在索引期间,构建数据结构以促进更快的查询。当您想为一个查询点找到近似的最近邻居时,您可以将该查询点提供给ANN算法。人工神经网络算法首先从数据集中识别一组可能接近查询点的候选数据点。使用预构建的数据结构选择候选对象。这一步骤大大减少了需要检查接近性的数据点的数量。在候选点被选中之前,ANN计算每个候选点与查询点之间的实际距离(如欧几里得距离、余弦相似度)。然后根据与查询点的距离/相似度对候选项进行排名。排名靠前的候选人作为近似近邻返回。在某些情况下,还可以设置距离阈值,只返回该阈值内的候选对象。人工神经网络背后的关键思想是,为了显著降低计算成本,它牺牲了找到绝对最近邻的保证。这些算法的目标是在计算效率和准确性之间取得平衡。
‘Rising oil prices are expected to hit China’s growth rate this year.’
‘Developing countries are starting to flex their financial muscles and invest overseas.
‘The Tehran Stock Exchange has performed magnificently, but the market’s list of risks is outsized.’
‘Federal Express raised its earnings forecast, citing strong demand for its international express, ground and less-than-truckload services.’
‘Federal Express raised its earnings forecast, citing strong demand for its international express, ground and less-than-truckload services.’ (Our data have duplications)
INSERT(hnsw, q, M, Mmax, efConstruction, mL) Input: multilayer graph hnsw, new element q, number of established connections M, maximum number of connections for each element per layer Mmax, size of the dynamic candidate list efConstruction, nor- malization factor for level generation mL Output: update hnsw inserting element q 1 W ← ∅ // list for the currently found nearest elements 2 ep ← get enter point for hnsw 3 L ← level of ep // top layer for hnsw 4 l ← ⌊-ln(unif(0..1))∙mL⌋ // new element’s level 5 for lc ← L … l+1 6 W ← SEARCH-LAYER(q, ep, ef=1, lc) 7 ep ← get the nearest element from W to q 8 for lc ← min(L, l) … 0 9 W ← SEARCH-LAYER(q, ep, efConstruction, lc) 10 neighbors ← SELECT-NEIGHBORS(q, W, M, lc) // alg. 3 or alg. 4 11 add bidirectionall connectionts from neighbors to q at layer lc 12 for each e ∈ neighbors // shrink connections if needed 13 eConn ← neighbourhood(e) at layer lc 14 if │eConn│ > Mmax // shrink connections of e // if lc = 0 then Mmax = Mmax0 15 eNewConn ← SELECT-NEIGHBORS(e, eConn, Mmax, lc) // alg. 3 or alg. 4 16 set neighbourhood(e) at layer lc to eNewConn 17 ep ← W 18 if l > L 19 set enter point for hnsw to q
SEARCH-LAYER(q, ep, ef, lc) Input: query element q, enter points ep, number of nearest to q ele- ments to return ef, layer number lc Output: ef closest neighbors to q 1 v ← ep // set of visited elements 2 C ← ep // set of candidates 3 W ← ep // dynamic list of found nearest neighbors 4 while │C│ > 0 5 c ← extract nearest element from C to q 6 f ← get furthest element from W to q 7 if distance(c, q) > distance(f, q) 8 break // all elements in W are evaluated 9 for each e ∈ neighbourhood(c) at layer lc // update C and W 10 if e ∉ v 11 v ← v ⋃ e 12 f ← get furthest element from W to q 13 if distance(e, q) < distance(f, q) or │W│ < ef 14 C ← C ⋃ e 15 W ← W ⋃ e 16 if │W│ > ef 17 remove furthest element from W to q 18 return W
SELECT-NEIGHBORS-SIMPLE(q, C, M) Input: base element q, candidate elements C, number of neighbors to return M Output: M nearest elements to q return M nearest elements from C to q
SELECT-NEIGHBORS-HEURISTIC(q, C, M, lc, extendCandidates, keep- PrunedConnections) Input: base element q, candidate elements C, number of neighbors to return M, layer number lc, flag indicating whether or not to extend candidate list extendCandidates, flag indicating whether or not to add discarded elements keepPrunedConnections Output: M elements selected by the heuristic 1 R ← ∅ 2 W ← C // working queue for the candidates 3 if extendCandidates // extend candidates by their neighbors 4 for each e ∈ C 5 for each eadj ∈ neighbourhood(e) at layer lc 6 if eadj ∉ W 7 W ← W ⋃ eadj 8 Wd ← ∅ // queue for the discarded candidates 9 while │W│ > 0 and │R│< M 10 e ← extract nearest element from W to q 11 if e is closer to q compared to any element from R 12 R ← R ⋃ e 13 else 14 Wd ← Wd ⋃ e 15 if keepPrunedConnections // add some of the discarded // connections from Wd 16 while │Wd│> 0 and │R│< M 17 R ← R ⋃ extract nearest element from Wd to q 18 return R
步骤如下:
初始化三个队列:R用于选择的邻居,W用于工作的候选,Wd用于丢弃的候选。
设置R的大小为0,W的大小为C的大小。
如果extendCandidates被设置(即,true):
对于C中的每个元素e:
对于第lc层e的每一个邻居eadj:
如果eadj不在W中,则在W中添加它。
而W的大小大于0,R的大小小于M:
从W到q中提取最近的元素e。
如果e比R中的任何元素更接近q,把e加到R中。
否则,将e加到Wd。
如果设置了keepPrunedConnections(即true):
而Wd的大小大于0,R的大小小于M:
从Wd到q中提取最近的元素e。
如果e比R中的任何元素更接近q,就把e加到R中。
返回R。
最后,让我们看看算法5。
这个搜索算法与算法1基本相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
Algorithm 5: K-NN-SEARCH()
K-NN-SEARCH(hnsw, q, K, ef) Input: multilayer graph hnsw, query element q, number of nearest neighbors to return K, size of the dynamic candidate list ef Output: K nearest elements to q 1 W ← ∅ // set for the current nearest elements 2 ep ← get enter point for hnsw 3 L ← level of ep // top layer for hnsw 4 for lc ← L … 1 5 W ← SEARCH-LAYER(q, ep, ef=1, lc) 6 ep ← get nearest element from W to q 7 W ← SEARCH-LAYER(q, ep, ef, lc =0) 8 return K nearest elements from W to q
你是精通计算机科学的专家,并且是一位专业翻译人员,请帮我翻译以下英文内容:“With Large Language Models(LLM) such as Chat GPT, machines can interact with humans in ways that weren’t possible before. There’s a growing interest in fine-tuning these pre-trained LLM models to preserve data privacy and cater to domain-specific tasks, thanks to the democratization of open-source Large Language Models. We can find numerous posts discussing model fine-tuning and application of in-context learning (I’ve even written three articles myself.., each delving into a distinct technique). But it’s essential to grasp the fundamentals. When should you opt for fine-tuning, and when is in-context learning the better choice? How do you kickstart the process, and how do these methods fit into the bigger picture? What techniques are readily available for you to implement? In this post, we’re diving into the fine-tuning process for pretrained models, explore different fine-tuning methods, and provide a comparison of the latest state-of-the-art techniques.”
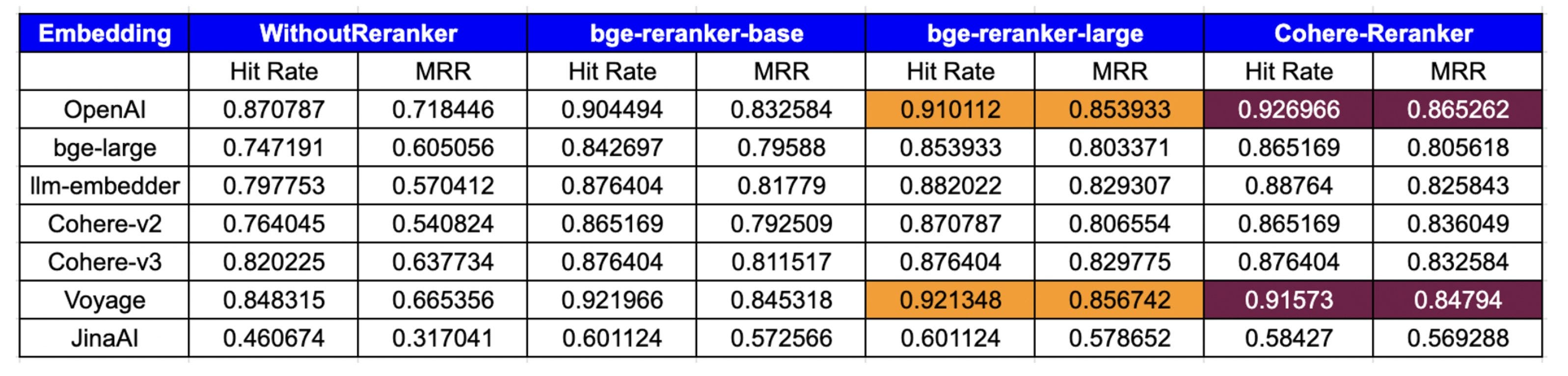
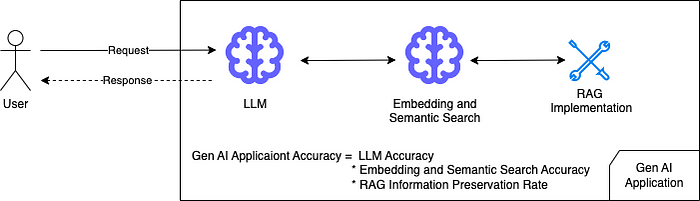
RAG架构使用Embedding模型来生成真实知识和查询的向量。然后使用向量相似度匹配算法来检索最相关的内容。Embedding模型从文本中提取表征向量的能力是非常关键的。除了Embedding模型之外,在RAG开发中还有很多实现细节,这些细节也会严重影响最终的结果。也就是说,RAG输出的准确率等于LLM的准确率 x 语义搜索的准确率 x RAG信息保存率。
自然文本也经常使用显性和隐性语言连接来连接主题。例如,一个故事可能以“in the beginning”开头,然后以“then”、“therefore”、“after that”继续,直到以“finally”、“finally”等结尾。使用分块策略,这种连接不再是完整的。不仅谜题不见了,而且排序顺序也被打乱了。