本文主要内容:
- 大语言模型(LLM)在实际应用中存在的问题;
- 什么是RAG——检索增强生成;
- RAG架构解析
- RAG技术架构的细节展示
写在前面
如果你问我现在基于LLM(大语言模型,本文有时候也会讲该名词描述为“大模型”)最火热的应用是什么,那我必须主推检索增强生成(RAG,Retrieval Augmented Generation)。RAG最初是为了解决LLM的各类问题的(后面会提到)产生的,但后面大家发现在现阶段的很多企业痛点上,使用RAG好像是更好的解决方案。就像我之前的文章《关于LLM的一些声音总结》提到的一样,企业发现其实自己要的好像是一个更好地搜索,根本不关心是不是大模型。于是,RAG被越来越多提到,包括开源的ChatPDF,也是RAG的一个经典应用。
但是我相信很多去实践RAG的人已经发现了一个情况,就是RAG入门很简单,但要真正达到企业应用的要求很难。而且RAG组成中的各类组件、流程和AI技术都过于复杂,很多人不知道如何去下手优化。
所以本文我们就来聊聊RAG,以及关于RAG优化的一些看法。
LLM的问题
首先我们还是要承认,RAG不管多厉害,它还是基于LLM的,脱离了LLM,RAG会脱离“人味儿”。
但是在今年年初的那一波大模型潮里面,我们发现如果仅仅依靠LLM,会有很多限制阻碍着我们前进,以下三点是最主要的:
- 幻觉问题:大模型的底层原理是基于概率,所以它有时候会一本正经胡说八道,比如我们问大模型的Chat(问答系统),“XXX博物院下周一开门吗?”我相信这样的问题你不能联系问,因为大模型会有一定的几率告诉你开门。而如果游客真的在下周一去了XXX博物院,那估计就要失望了,如果这个Chat还是博物院官方提供的,那事情最终会演变成一通12345的投诉电话。所以在很多需要非常精确的场景,仅仅依赖GPT的这种生成式回答是很不严谨的,而且看很难消除——目前常见的解决方案是前置一个BERT,或者预置大量prompt做优化。
- 新鲜度问题:规模越大(参数越多、tokens越多),大模型训练的成本越高。类似OpenAI的ChatGPT3.5,目前的数据新鲜度依然保留在2021年,对于之后的事情就不知道了。而且对于一些高时效性的事情,大模型更加无能为力,比如帮我看看今天晚上有什么电影值得去看?这种任务是需要去淘票票、猫眼等网站先去获取最新电影信息的,大模型本身无法完成这个任务。
- 数据安全:OpenAI已经遭到过几次隐私数据的投诉,而对于企业来说,如果把自己的经营数据、合同文件等机密文件和数据上传到互联网上的大模型,那想想都可怕。如果企业人员想提一个类似这样的问题:“帮我看看3月份XX部门的销售环比数据与哪些兄弟部门的增长是密切相关的?”,这需要打穿企业内部的很多数据。既要保证安全,又要借助AI能力,那么最好的方式就是把数据全部放在本地,企业数据的业务计算全部在本地完成。而在线的大模型仅仅完成一个归纳的功能,甚至,LLM都可以完全本地化部署。
其实问题还有很多,包括tokens的限制,虽然这个长期来看不是问题,各LLM供应商的tokens数量限制肯定会越来越大。但是,费用也许就是另外一个需要考虑的问题了。
在解决这些问题的方法上,目前RAG走的比较前面。有些朋友应该已经了解过LangChain,它是架在LLM之上的一个应用框架,帮助人们快速开发基于LLM的应用。它的很多功能其实也属于RAG范畴。
什么是RAG
为RAG铺垫了这么多,下面我们来看看什么是RAG。
从开头的介绍里面大家已经可以看到,RAG——Retrieval Augmented Generation,检索增强生成。它的主要作用是生成(最终的答案),但是它先做了对现有文档的检索,而不是任由LLM来发挥。下面我提供讲一个浅显的例子来说明一下RAG:
假设一个工程师需要从厚厚的《业务操作手册》中找到相关的业务知识来帮助他完成工作,那么他有三种方式可以使用:
- 最原始:他可以去翻阅这么厚厚的《业务操作手册》,或者用去查询这么《业务操作手册》的电子版,然后认真阅读掌握操作方法。当然,如果他碰到的业务知识比较复杂,他就需要自己去综合这么书上面的多个章节的内容,并融会贯通;
- 借助问答机器人:他也可以直接去咨询问答机器人(chatbot),机器人也会把相应的知识吐给你。但是它可能有两个麻烦,一是它类似于FAQ,一问一答,还是需要自己去组合所有的回答内容;二是这个机器人需要前期大量的预训练知识库,需要专业的工程师去一条一条(其实是一个个知识条目,包括答案和多个相似问法),工作量极大,不太适合大面试推广使用;
- RAG:RAG的操作方式就是我们可以直接把这个《业务操作手册》的电子版上传到系统,系统在几分钟之内就可以把这篇“巨著”变成索引,供刚才那位工程师咨询。而且RAG给的答案会去综合正本手册的多个相关知识点,并用“专家”一样的口吻来给你答案:“要解决这个问题,你需要先解决两个前提,有三种方法来解决。下面我们一步步来看怎么做….”。
好了,我们现在知道RAG是个什么玩意儿了。你有没有发现,它其实会把之前的FAQ问答给取代掉,但是它能做的远远不止这些,它还是很多应用的中间件。我们自己的一个面向文博场馆的产品就是基于RAG的,大概占了整个系统的1/3比重。另外,RAG不仅仅面向文本,它还可以面向语音、视频和图像等多模态场景,只要可以embedding的内容就可以,当然这些我们这里就不多介绍了。
RAG架构
下面我们来了解一下RAG,它有非常多的组件,但是我们可以化繁为简。我喜欢把RAG——Retrieval Augmented Generation理解为Retrieval And Generation,也就是检索与生成,在加上一个数据向量和索引的工作,我们对RAG就可以总概方式地理解为“索引、检索和生成”。
以下就是RAG的主要组成,依次是数据提取——embedding(向量化)——创建索引——检索——自动排序(Rerank)——LLM归纳生成。当然这里少了使用环节,我们暂时先忽略用户提问的环节。
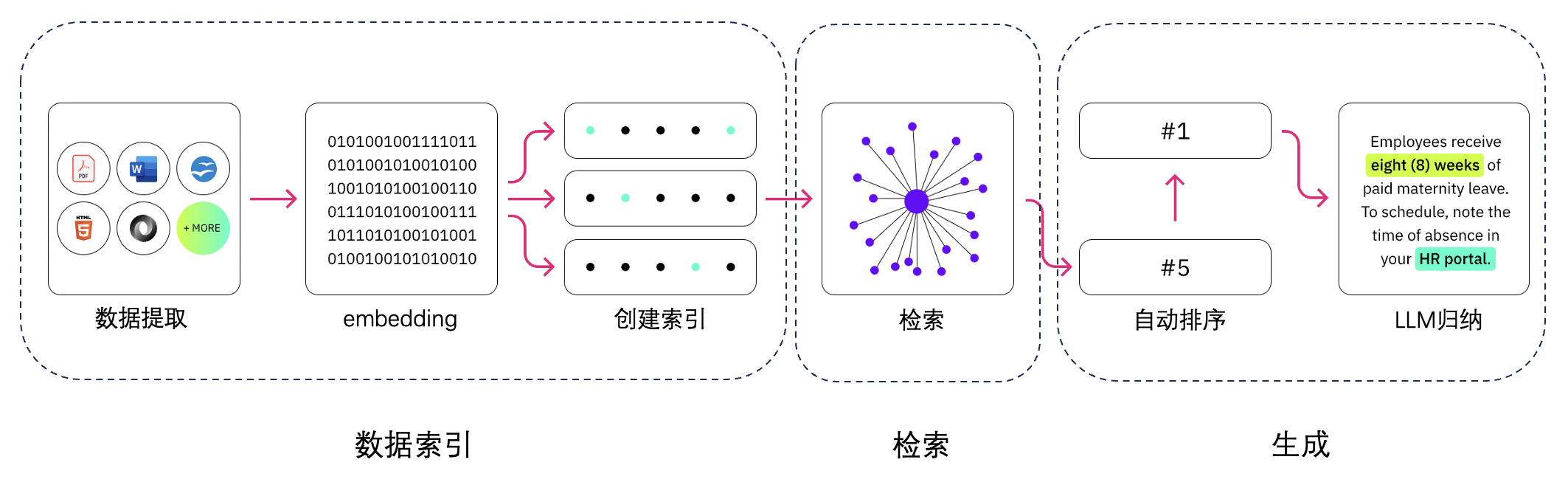
RAG技术细节概览
在技术细节上,我们还可以分成更细的组成。
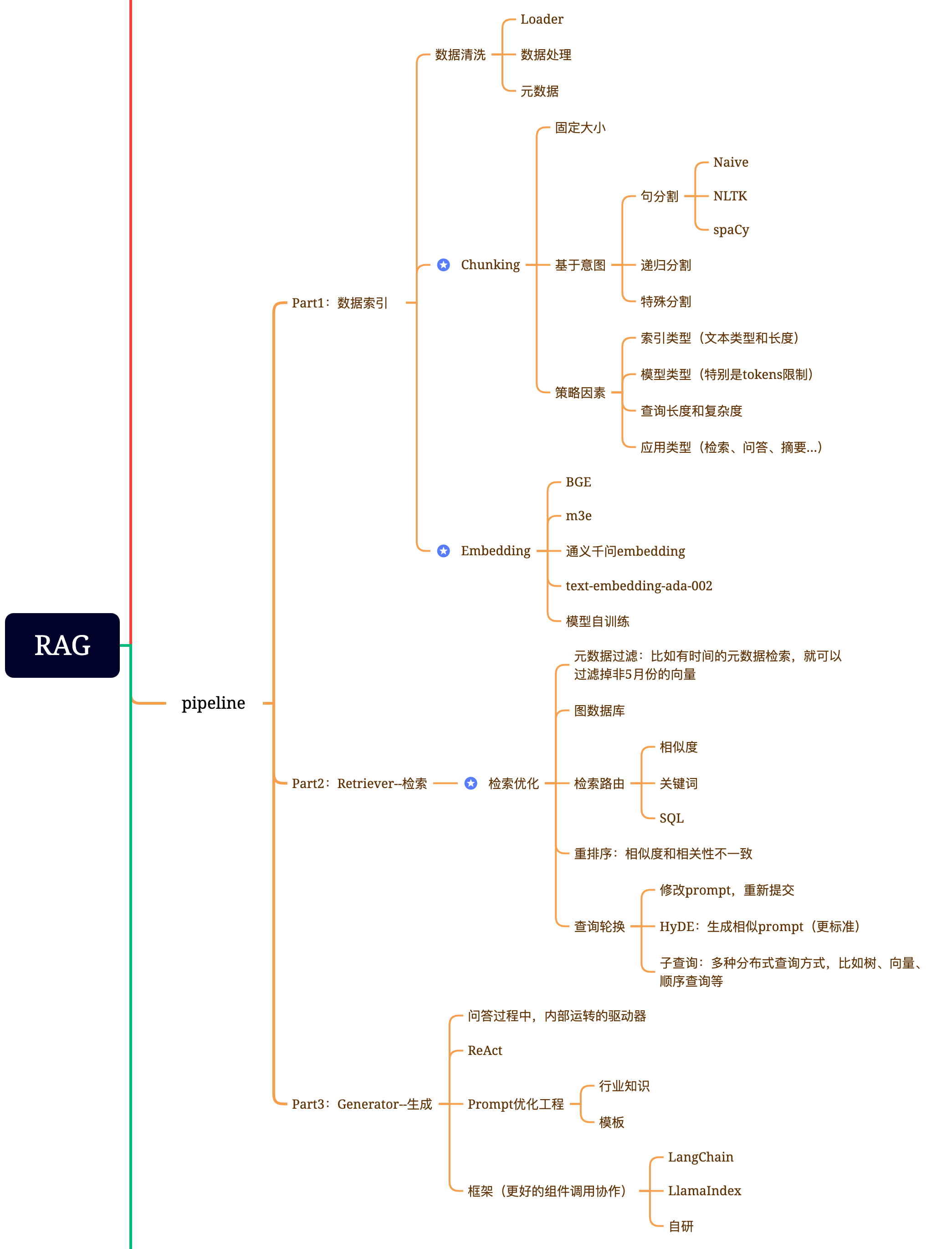
一、数据索引
数据提取
- 数据清洗:包括数据Loader,提取PDF、word、markdown以及数据库和API等;
- 数据处理:包括数据格式处理,不可识别内容的剔除,压缩和格式化等;
- 元数据提取:提取文件名、时间、章节title、图片alt等信息,非常关键。
分块(Chunking)
- 固定大小的分块方式:一般是256/512个tokens,取决于embedding模型的情况。但是这种方式的弊端是会损失很多语义,比如“我们今天晚上应该去吃个大餐庆祝一下”,很有可能就会被分在两个chunk里面——“我们今天晚上应该”、“去吃个大餐庆祝一下”。这样对于检索是非常不友好的,解决方法是增加冗余量,比如512tokens的,实际保存480tokens,一头一尾去保存相邻的chunk头尾的tokens内容;
- 基于意图的分块方式:
- 句分割:最简单的是通过句号和换行来做切分。当然也有通过专业的意图包来切分的,常用的意图包有基于NLP的NLTK和spaCy;
- 递归分割:通过分治的方法,用递归切分到最小单元的一种方式;
- 特殊分割:还有很多不常见的,用于特殊场景,这里就不提了。
- 影响分块策略的因素:
- 取决于你的索引类型,包括文本类型和长度,文章和微博推文的分块方式就会很不同;
- 取决于你的模型类型:你使用什么LLM也会有不同,因为ChatGLM、ChatGPT和Claude.ai等的tokens限制长度不一样,会影响你分块的尺寸;
- 取决于问答的文本的长度和复杂度:最好问答的文本长度和你分块的尺寸差不多,这样会对检索效率更友好;
- 应用类型:你的RAG的应用是检索、问答和摘要等,都会对分块策略有不同的影响。
向量化(embedding):这是将文本、图像、音频和视频等转化为向量矩阵的过程,也就是变成计算机可以理解的格式,embedding模型的好坏会直接影响到后面检索的质量,特别是相关度。关于embedding大家可以看我之前的一篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》,一般我们现在可以选择的embedding模型有这些:
- BGE:这是国人开发的中文embedding模型,在HuggingFace的MTEB(海量文本Embedding基准)上排名前2,实力强劲;
- M3E:也是国人开发的中文embedding模型,我们之前用的就是这个模型,总体来说也算可以,这个还看大家的使用场景,也许你的场景会比我们更加适用;
- 通义千问的embedding模型:因为是1500+维的模型,所以我们在国庆节后准备用用看;
- Text-embedding-ada-002:这是OpenAI的embedding模型,1536维,我感觉上应该是目前最好的模型,但是它在MTEB上排名好像只有第六,但是国内应该也不太能用,所以我们就放弃了;
- 自己训练embedding模型:这是最酷的了,我过几天会专门写一篇如何训练embedding模型的文章,没有关注我的可以先关注,哈。当然,训练是基于一个既有embedding模型的,一般我们有希望让它在原来的基础上提升3%-10%的性能。
二、检索环节(Retriever)
检索环节技术含量依然很高,而且对于我们目前来说,还有一两项工作正在进行中。
检索优化一般分为下面五部分工作:
元数据过滤:当我们把索引分成许多chunks的时候,检索效率会成为问题。这时候,如果可以通过元数据先进行过滤,就会大大提升效率和相关度。比如,我们问“帮我整理一下XX部门今年5月份的所有合同中,包含XX设备采购的合同有哪些?”。这时候,如果有元数据,我们就可以去搜索“XX部门+2023年5月”的相关数据,检索量一下子就可能变成了全局的万分之一;
图关系检索:如果可以将很多实体变成node,把它们之间的关系变成relation,就可以利用知识之间的关系做更准确的回答。特别是针对一些多跳问题,利用图数据索引会让检索的相关度变得更高;
检索技术:前面说的是一些前置的预处理的方法,检索的主要方式还是这几种:
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》种有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等,后面我还会再专门写一篇这方面的文章,可以关注我,yeah;
- 关键词检索:这是很传统的检索方式,但是有时候也很重要。刚才我们说的元数据过滤是一种,还有一种就是先把chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率。据说Claude.ai也是这么做的;
- SQL检索:这就更加传统了,但是对于一些本地化的企业应用来说,SQL查询是必不可少的一步,比如我前面提到的销售数据,就需要先做SQL检索。
- 其他:检索技术还有很多,后面用到再慢慢说吧。
重排序(Rerank):很多时候我们的检索结果并不理想,原因是chunks在系统内数量很多,我们检索的维度不一定是最优的,一次检索的结果可能就会在相关度上面没有那么理想。这时候我们需要有一些策略来对检索的结果做重排序,比如使用planB重排序,或者把组合相关度、匹配度等因素做一些重新调整,得到更符合我们业务场景的排序。因为在这一步之后,我们就会把结果送给LLM进行最终处理了,所以这一部分的结果很重要。这里面还会有一个内部的判断器来评审相关度,触发重排序。
查询轮换:这是查询检索的一种方式,一般会有几种方式:
- 子查询:可以在不同的场景中使用各种查询策略,比如可以使用LlamaIndex等框架提供的查询器,采用树查询(从叶子结点,一步步查询,合并),采用向量查询,或者最原始的顺序查询chunks等;
- HyDE:这是一种抄作业的方式,生成相似的,或者更标准的prompt模板。
三、生成(Gen)
这一部反而是我比较疏忽的,因为有大量的现成框架可以使用,而且,这一步真正发挥巨大作用的是LLM。
这里面我们使用的框架有Langchain和LlamaIndex,而且我们因为有之前的AI产品积累,所以还有一套完整的Java框架可以使用,所以这一块我没有太多研究。唯一非常关注的就是Prompt工程,我们团队内部,这一部分的工作是交给了原来AI产品的知识库运营团队来做的,他们原来做的更多是BERT相关的知识库预训练,应该说工作内容还是比较匹配的。
在Prompt里面其实还是有很多决定因素的,这和大家对所处行业的knowhow有关。比如在文旅行业,你要知道游客或者观众一般会怎么提问,真正需要得到的是什么内容。这些我就不多说了,各行业不太一样,但是大家可以翻看我之前写的关于prompt的文章《一文讲清楚实用Prompt工程》、《高级prompt工程讲解》。
其他的关于ReAct等内容,本文就先不涉及了,后面再专门写一篇文章。
总结
LLM这一波,催生的技术真的很多,每一个环节,要真正做好,符合企业应用,都可以让我们研究好长一段时间,并需要不断去实践,才能打磨出精品。但是如果打磨出精品,你肯定可以摘取新技术带来的果实。技术人员在很多公司地位不高?嗯,大模型这一波,我已经感觉到变化的发生了——了解大模型和不了解大模型的人,在AI的业务上的理解上,有某些角度来看,他们的区别真的就现代人类和史前人类一样巨大。
本文可能还是属于大模型应用——RAG的一个大纲式的技术普及文章,这里面的很多技术细节,我会在后面一篇篇专门来写,欢迎大家关注“土猛的员外”。
Update: 2024-01-26

我们的TorchV Bot产品目前已经开始试用了,详情可以点击:https://www.luxiangdong.com/2024/01/25/lanuch-1
目前只接受企业用户试用,需要您填写一些信息,必要信息如下:
邮箱: 用来接收地址和账号
如何称呼您:
所服务的公司:
您的职位:
当然,如果您可以告诉我们您的使用场景,我们将更加感激!
对了,可以发送到yuanwai@mengjia.net
另外,也可以直接加我微信(lxdhdgss)联系我。

