由于OpenAI创建了允许开发人员使用GPT-3和GPT-4语言模型的api, LangChain等工具也得到了蓬勃发展。它们的附加值是多少?它们提供了简单而通用的抽象,使开发人员能够试验大型语言模型(llm),这些模型不仅来自OpenAI,还来自Cohere、Anthropic等。
这些工具或模块还允许开发人员合并专门的矢量存储,这对于存储单词embedding特别有用。单词的向量化是至关重要的,因为它通过减轻维度的诅咒来促进像GPT这样的语言模型的训练。
在这些工具中,LangChain无疑是最知名和最广泛使用的。我自己也写了很多关于如何使用LangChain的教程。我还写过一些关于LangChain局限性的文章,它的接口可能过于复杂,其抽象在生产环境中的实用性还有待证明。
LangChain的策略
在我看来,LangChain的创造者的策略是通过合作来实现增长。目前,LangChain集成了12个聊天模型,100多个文档加载器,50多个llm(大型语言模型),众多检索器,embedding模型,工具和向量存储。看来,LangChain的目标是成为连接各种解决方案的重要枢纽,以开发利用llm的应用程序。
这种策略很强大,因为它往往会使LangChain变得不可或缺。目标似乎是使LangChain成为基于LLM的应用程序生态系统的本地语言。至少从市场营销的角度来看,这种策略似乎是有效的。从本质上讲,LangChain作为一个API连接器,具有一些通用的抽象,可以有效地利用这些API。
这个策略面临的挑战
这种方法的问题是,作为开发人员,您最终会使用一个笨重的系统来实现一些简单的东西。这就像用锤子打苍蝇一样;您可以轻松地连接到各种API,但在为您的特定用例定制庞大模块的复杂性中,您将失去这些好处。不幸的是,LangChain之于基于llm的应用程序并不像Flask之于Python web开发。
此外,将一个开源模块商业化也是一个挑战。考虑到LangChain最近获得了1000万美元的VC(风险投资)种子基金,他们无疑会受到激励去寻找盈利解决方案。这解释了为什么LangChain推出了LangSmith,以实现对基于llm的应用程序的监控。
另一种选择:
由于所有这些原因,我想在这里提出一个LangChain的替代品:LlamaIndex。
我最欣赏的是LlamaIndex的清晰使命:将大型语言模型(LLM)与数据源连接起来,用于上下文学习或部署检索增强生成(RAG)系统。它是清晰的、集中的,并且可以立即可视化用例。例如,部署一个允许与存储在Notion中的文档进行对话的RAG系统是一个在企业环境中非常有用的用例。
下面来看看LlamaIndex提供了什么:
- 数据连接器:这些连接器从其原生源和格式中摄取现有数据。这些可以是api、pdf、SQL等等。
- 数据索引:这些以中间表示形式结构化数据,便于llm使用。
- 引擎:这些提供对数据的自然语言访问。例如:
- 查询引擎:这些是用于知识增强输出的强大检索接口。
- 聊天引擎:这些是多消息的会话接口,“来回”与您的数据交互。
- 数据代理:这些是llm支持的知识工作者,通过工具增强,从简单的辅助功能到API集成等等。
- 应用程序集成:这些将羊驼指数连接回您的生态系统的其余部分。它可以是LangChain、Flask、Docker、ChatGPT或其他任何东西。
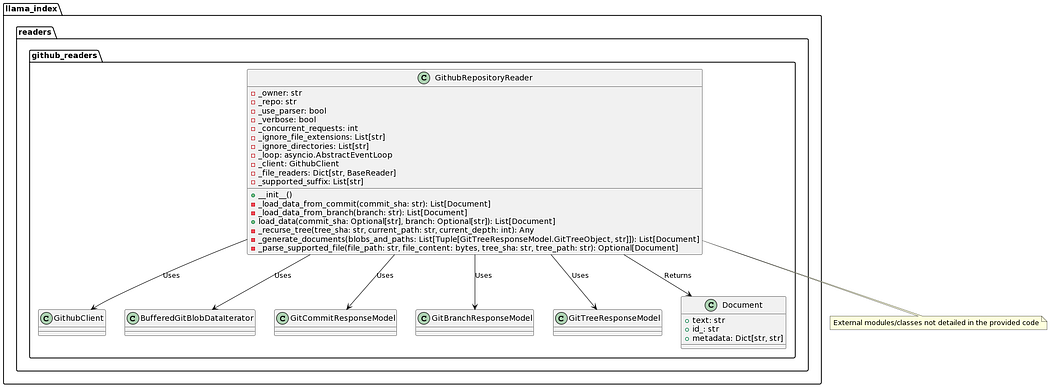
在快速阅读文档后,我很容易识别用例。例如,我遇到了一个允许读取GitHub存储库内容的类。
1 | class llama_index.readers.GithubRepositoryReader(owner: str, repo: str, use_parser: bool = True, verbose: bool = False, github_token: Optional[str] = None, concurrent_requests: int = 5, ignore_file_extensions: Optional[List[str]] = None, ignore_directories: Optional[List[str]] = None) |
多亏了这一点,人们可以开发一个应用程序,通过聊天与GitHub存储库进行交互。
原文:Everyone Talks About LangChain But This Alternative Seduced Me

