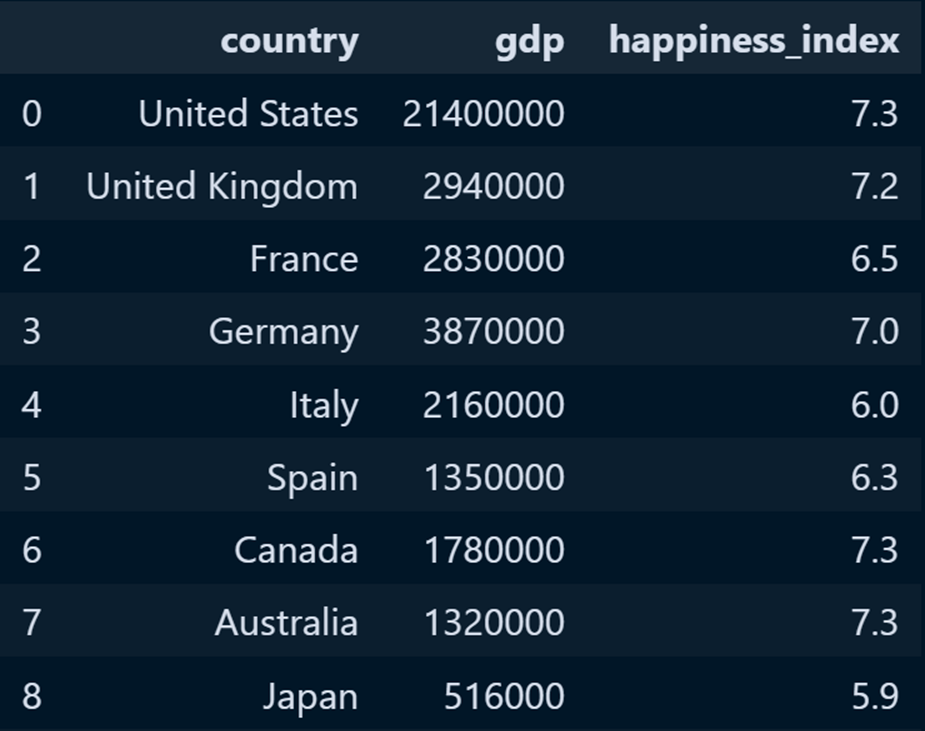
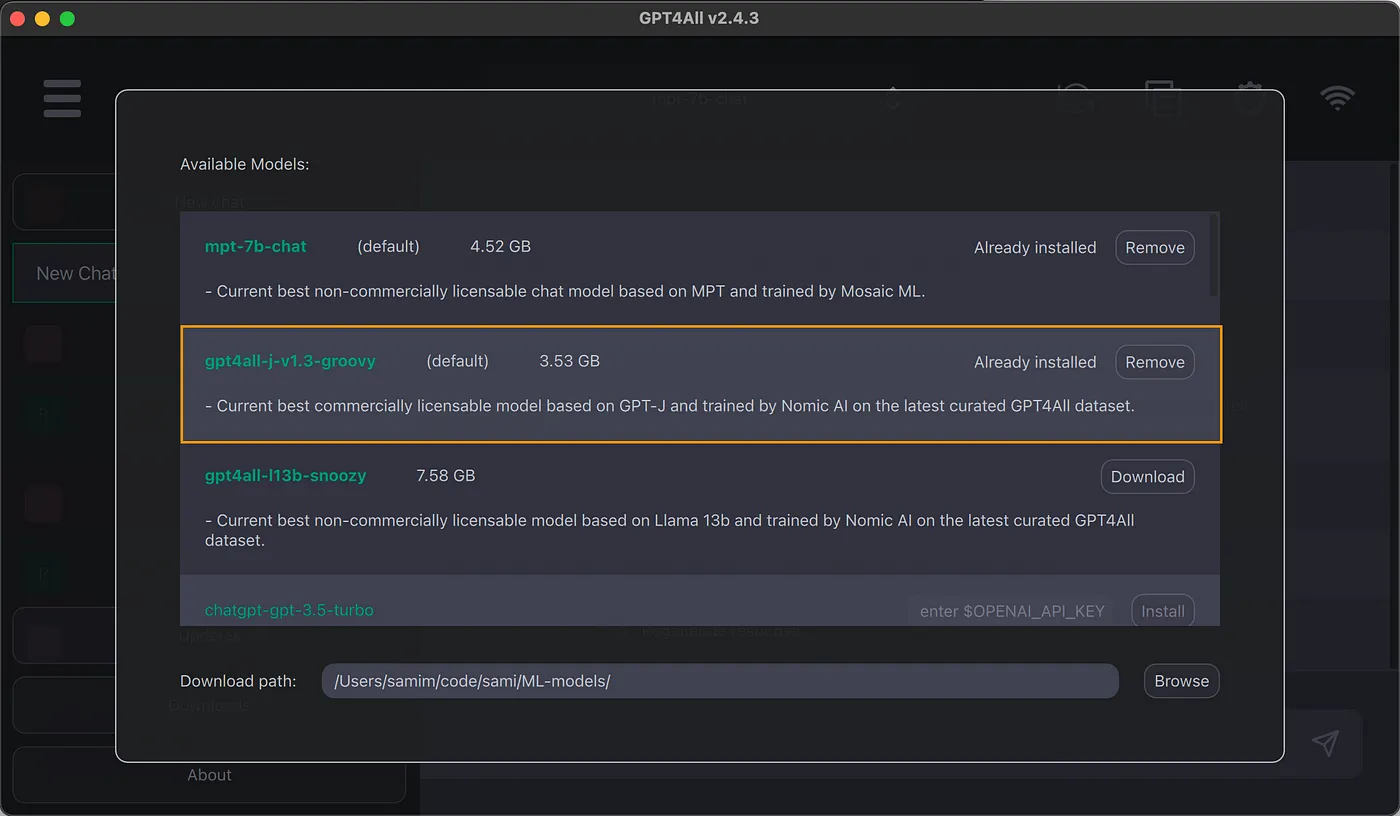
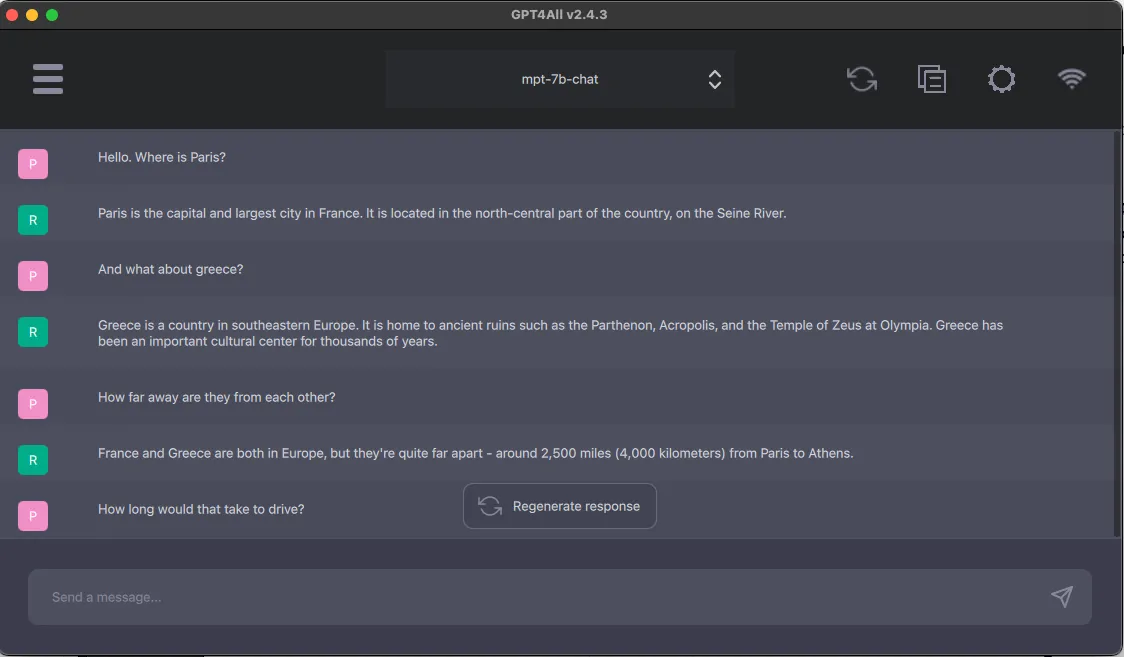
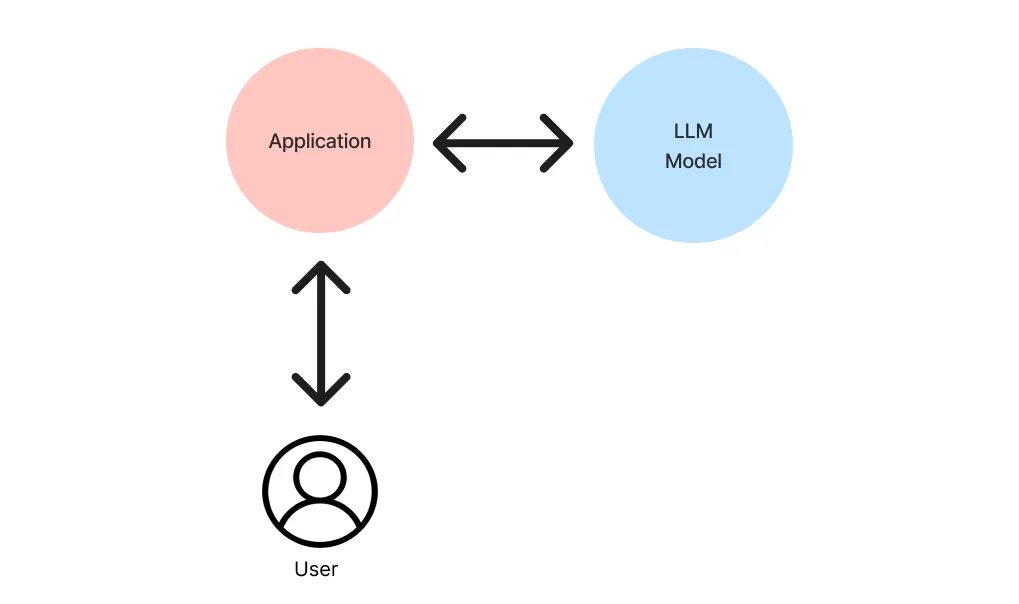
# Accessing the OPENAI KEY import environ env = environ.Env() environ.Env.read_env() API_KEY = env('OPENAI_API_KEY')
# Simple LLM call Using LangChain llm = OpenAI(model_name="text-davinci-003", openai_api_key=API_KEY) question = "Which language is used to create chatgpt ?" print(question, llm(question))
# Accessing the OPENAI KEY import environ env = environ.Env() environ.Env.read_env() API_KEY = env('OPENAI_API_KEY')
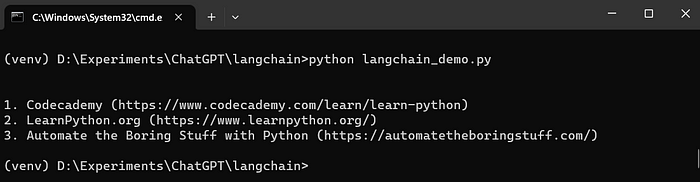
# Creating a prompt template and running the LLM chain from langchain import PromptTemplate, LLMChain template = "What are the top {n} resources to learn {language} programming?" prompt = PromptTemplate(template=template,input_variables=['n','language']) chain = LLMChain(llm=llm,prompt=prompt) input = {'n':3,'language':'Python'} print(chain.run(input))
import environ env = environ.Env() environ.Env.read_env()
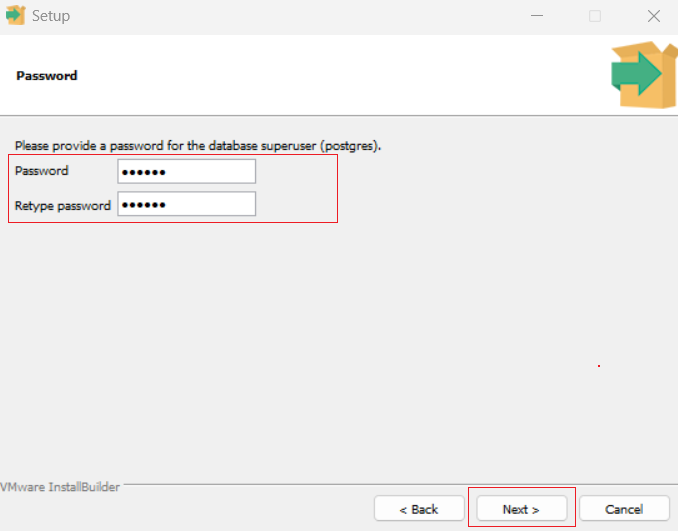
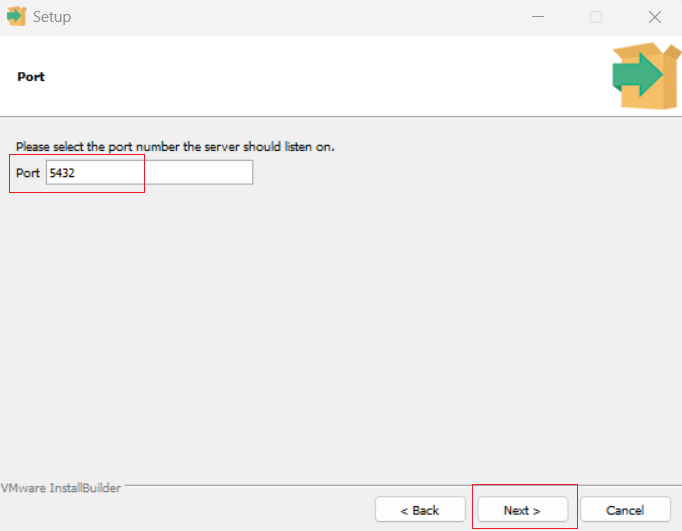
# Establish a connection to the PostgreSQL database conn = psycopg2.connect( host='localhost', port=5432, user='postgres', password=env('DBPASS'), database=env('DATABASE') )
# Create a cursor object to execute SQL commands cursor = conn.cursor()
# Create the tasks table if it doesn't exist cursor.execute('''CREATE TABLE IF NOT EXISTS tasks (id SERIAL PRIMARY KEY, task TEXT NOT NULL, completed BOOLEAN, due_date DATE, completion_date DATE, priority INTEGER)''')
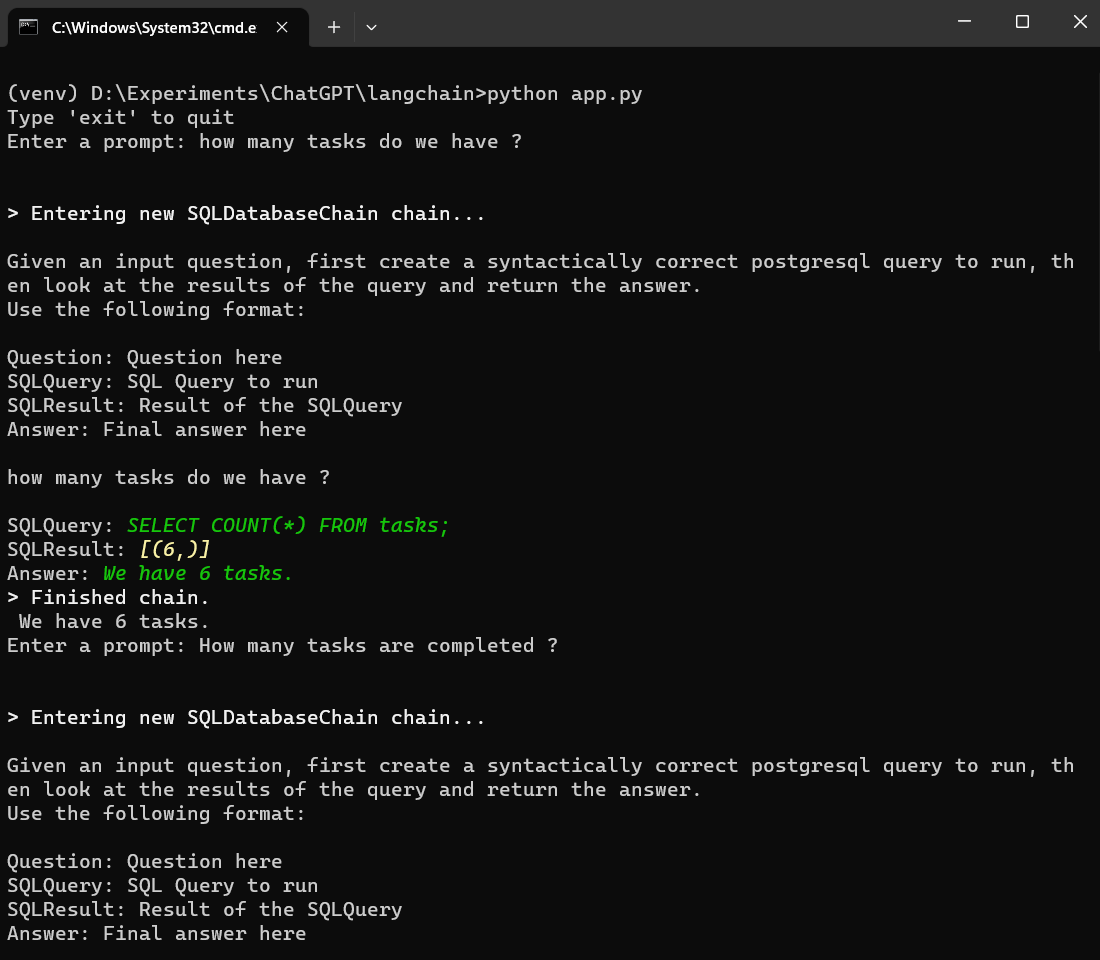
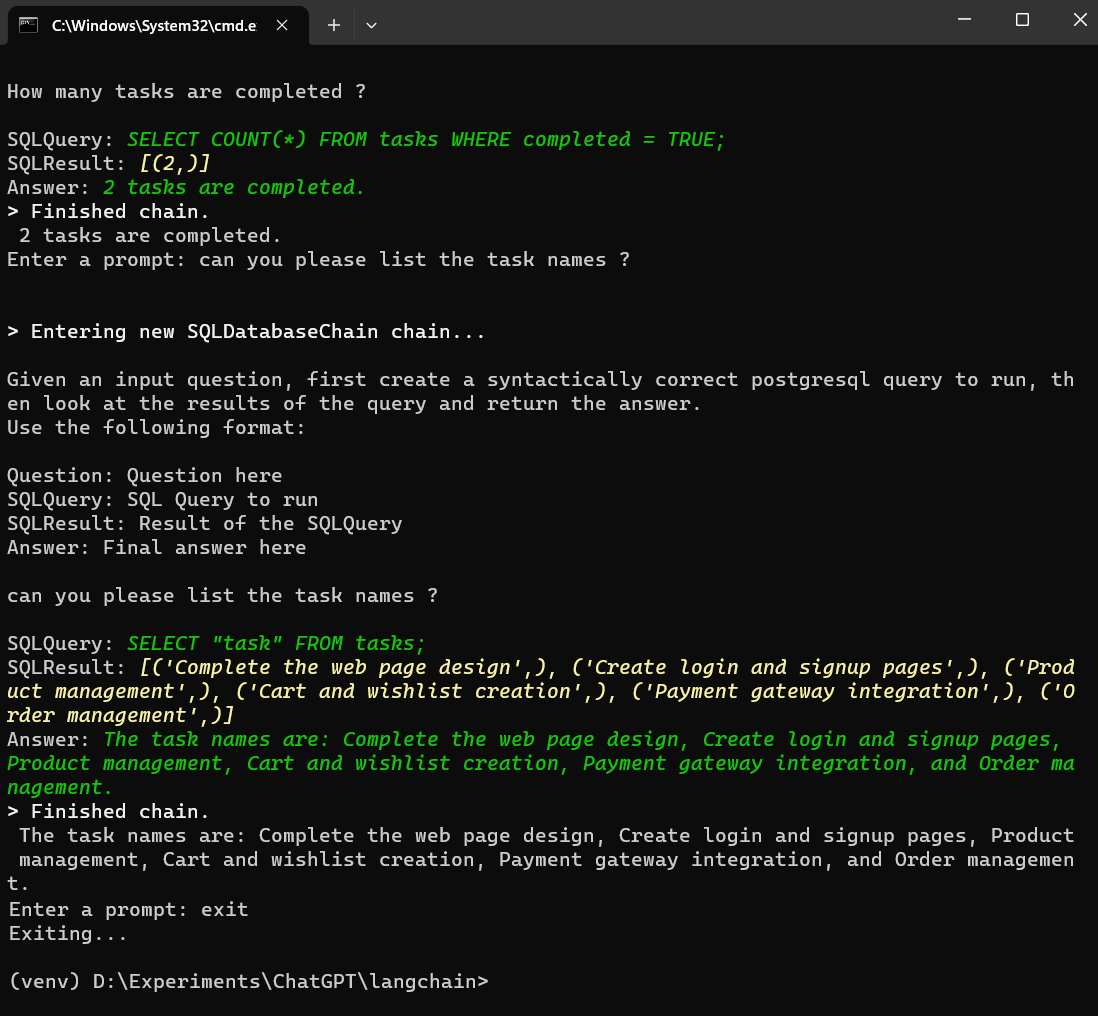
# Create db chain QUERY = """ Given an input question, first create a syntactically correct postgresql query to run, then look at the results of the query and return the answer. Use the following format: Question: Question here SQLQuery: SQL Query to run SQLResult: Result of the SQLQuery Answer: Final answer here {question} """
# Setup the database chain db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
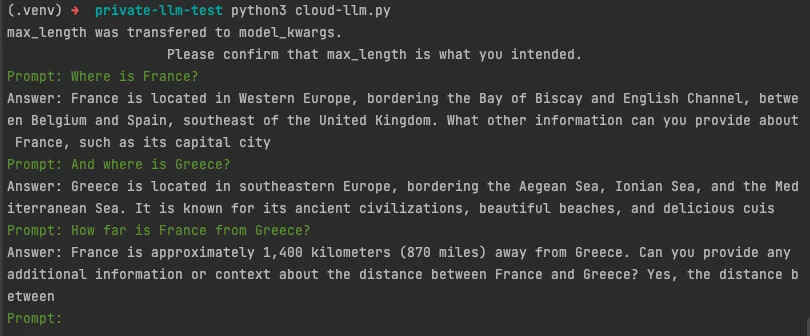
defget_prompt(): print("Type 'exit' to quit")
whileTrue: prompt = input("Enter a prompt: ")
if prompt.lower() == 'exit': print('Exiting...') break else: try: question = QUERY.format(question=prompt) print(db_chain.run(question)) except Exception as e: print(e)
# You are a friendly chatbot assitant. Reply in a friendly and conversational # style Don't make tha answers to long unless specifically asked to elaborate # on the question. ### Human: %1 ### Assistant:
mkdir private-llm cd private-llm touch local-llm.py mkdir models # lets create a virtual environement also to install all packages locally only python3 -m venv .venv . .venv/bin/activate
llm(""" You are a friendly chatbot assistant that responds in a conversational manner to users questions. Keep the answers short, unless specifically asked by the user to elaborate on something.
from langchain import PromptTemplate, LLMChain from langchain.llms import GPT4All from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
template = """ You are a friendly chatbot assistant that responds in a conversational manner to users questions. Keep the answers short, unless specifically asked by the user to elaborate on something. Question: {question} Answer:""" prompt = PromptTemplate(template=template, input_variables=["question"])
import os from langchain import PromptTemplate, LLMChain from langchain.llms import CerebriumAI
os.environ["CEREBRIUMAI_API_KEY"] = "public-"
template = """ You are a friendly chatbot assistant that responds in a conversational manner to users questions. Keep the answers short, unless specifically asked by the user to elaborate on something. Question: {question} Answer:"""
if model_name in ['gpt-3.5-turbo', 'gpt-4']: llm = ChatOpenAI(temperature=0, model_name=model_name) else: raise Exception(f"Model {model_name} is currently not supported")
Assistant can ask the user to use tools to look up information that may be helpful in answering the users original question. The tools the human can use are: {{tools}} {format_instructions} USER'S INPUT - - - - - - - - - - Here is the user's input (remember to respond with a markdown code snippet of a json blob with a single action, and NOTHING else): {{{{input}}}}
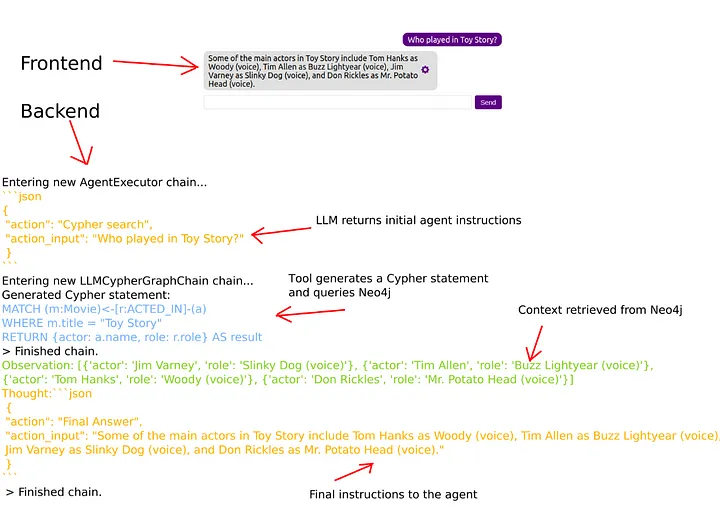
tools = [ Tool( name="Cypher search", func=cypher_tool.run, description=""" Utilize this tool to search within a movie database, specifically designed to answer movie-related questions. This specialized tool offers streamlined search capabilities to help you find the movie information you need with ease. Input should be full question.""", ), Tool( name="Keyword search", func=fulltext_tool.run, description="Utilize this tool when explicitly told to use keyword search.Input should be a list of relevant movies inferred from the question.", ), Tool( name="Vector search", func=vector_tool.run, description="Utilize this tool when explicity told to use vector search.Input should be full question.Do not include agent instructions.", ),
SYSTEM_TEMPLATE=""" You are an assistant with an ability to generate Cypher queries based off example Cypher queries. Example Cypher queries are:\n"""+examples+"""\n Do not response with any explanation or any other information except the Cypher query. You do not ever apologize and strictly generate cypher statements based of the provided Cypher examples. Do not provide any Cypher statements that can't be inferred from Cypher examples. Inform the user when you can't infer the cypher statement due to the lack of context of the conversation and state what is the missing context. """
WITH $embedding AS e MATCH (m:Movie) WHERE m.embedding IS NOT NULL AND size(m.embedding) = 1536 WITH m, gds.similarity.cosine(m.embedding, e) AS similarity ORDER BY similarity DESC LIMIT 5 CALL { WITH m MATCH (m)-[r:!RATED]->(target) RETURN coalesce(m.name, m.title) + " " + type(r) + " " + coalesce(target.name, target.title) AS result UNION WITH m MATCH (m)<-[r:!RATED]-(target) RETURN coalesce(target.name, target.title) + " " + type(r) + " " + coalesce(m.name, m.title) AS result } RETURN result LIMIT 100
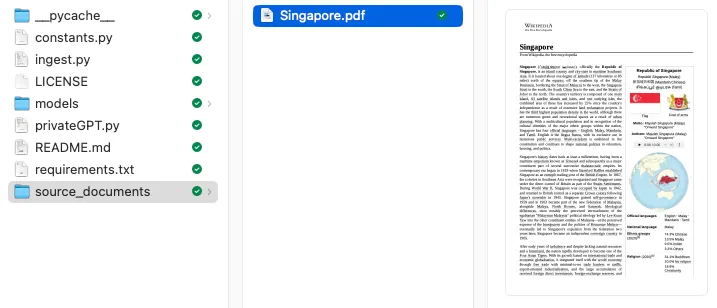
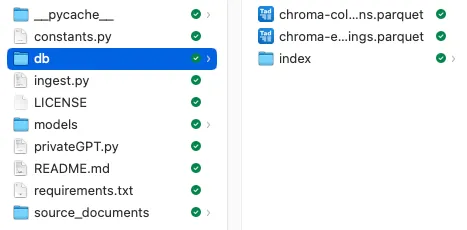
Loading documents from source_documents Loaded 1 documents from source_documents Split into 692 chunks of text (max. 500 characters each) Using embedded DuckDB with persistence: data will be stored in: db
Embedding文件保存在db文件夹中,格式为Chroma db:
Chroma 是一个开源的向量数据库。
开始提问题吧
您现在可以提问了!
在Terminal中输入以下命令:
1
$ python privateGPT.py
加载模型需要一段时间。在此过程中,您将看到以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
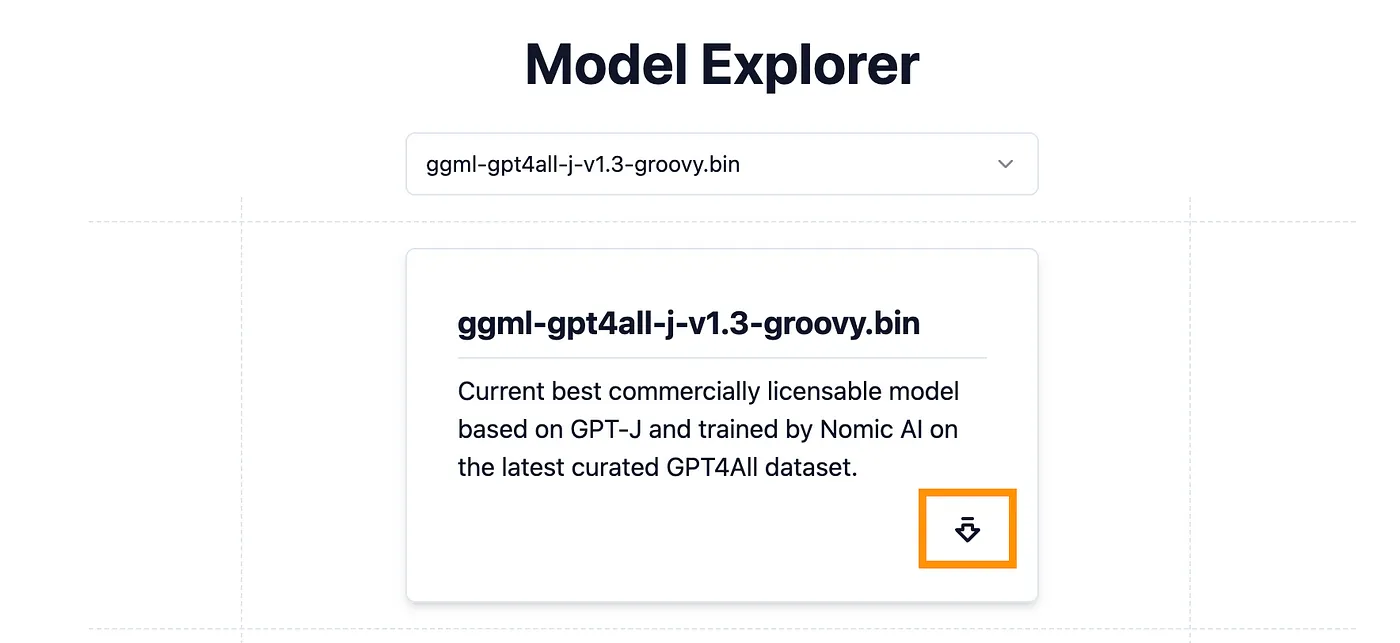
Using embedded DuckDB with persistence: data will be stored in: db gptj_model_load: loading model from 'models/ggml-gpt4all-j-v1.3-groovy.bin' - please wait ... gptj_model_load: n_vocab = 50400 gptj_model_load: n_ctx = 2048 gptj_model_load: n_embd = 4096 gptj_model_load: n_head = 16 gptj_model_load: n_layer = 28 gptj_model_load: n_rot = 64 gptj_model_load: f16 = 2 gptj_model_load: ggml ctx size = 4505.45 MB gptj_model_load: memory_size = 896.00 MB, n_mem = 57344 gptj_model_load: ................................... done gptj_model_load: model size = 3609.38 MB / num tensors = 285
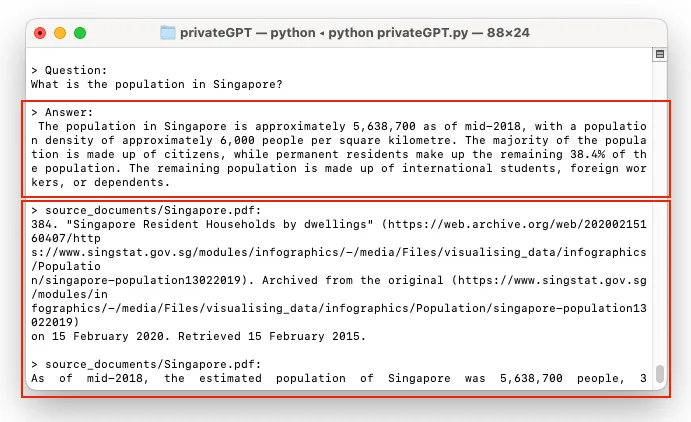
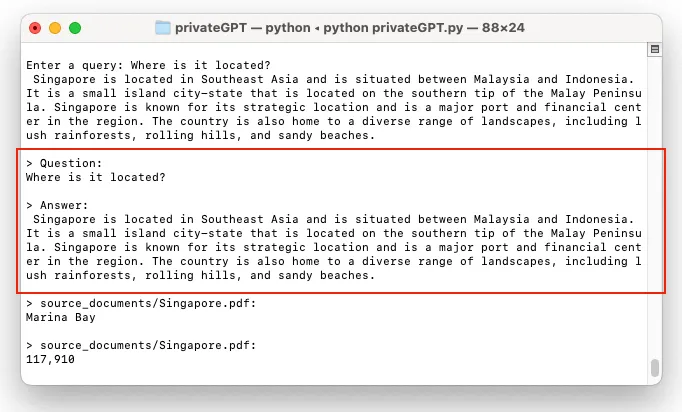
Enter a query:
At the prompt, you can type in your question. I asked: “*What is the population in Singapore?*”. It took privateGPT quite a while to come up with the answer. Once it managed to find an answer, it give you the answer and cited the source for the answer:
在Enter a query:提示符后面,你可以输入你的问题。问:“新加坡的人口是多少?”。privateGPT可能需要花很长时间才想出了答案。一旦它找到了答案,它就会给出答案并引用答案的来源:
segmentation fault python privateGPT.py. /Users/weimenglee/miniforge3/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown. warnings.warn(‘resource_tracker: There appear to be %d ‘
排列的用法(消耗会非常快!!!): /imagine prompt: cinematic shot of astronaut on {horse, turtle} --c {20,80} ...实际会生产四条prompts: -> cinematic shot of astronaut on a horse --c 20 cinematic shot of astronaut on a turtle --c 20 cinematic shot of astronaut on a horse --c 80 cinematic shot of astronaut on a turtle --c 80
Weights(权重): /imagine prompt: hot dog // 热狗(食物) hot:: dog // 热的狗狗(动物) hot::2 dog // 非常热的狗狗(动物),这里容易混淆,这里的比重其实是hot更大,hot的比重是dog的两倍。
Option Commands: /prefer option set [NAME OF OPTION][VALUE]// 设置常用选项 ... e.g: -> /prefer option set mycoolpreset dadaism --c 80// 将 dadaism --c 80 设置为常用选项,名称是mycoolpreset ...now /imagine prompt: an astronaut, --mycoolpreset // 使用 --mycoolpreset ...becomes /imagine prompt: an astronaut, dadaism --c 80// Midjourney会自动将Prompt理解为这样
/prefer option set mycoolpreset ...deletes mycoolpreset! // 删除(清空)默认选项 /prefer option list ... shows presets // 显示所有已经设定的后缀 /prefer option remix ... toggles remix mode // 切换混合模式,混合模式可以使用某一原图的构图来进行作图。 /prefer suffix ... suffix to add to the end of every prompt // 设置后缀 /prefer auto_dm ... automatically send DM when jobs complete // 自动设置将结果发私信