译者注:
本文为《Enabling conversational interaction on mobile with LLMs》的中文翻译稿,Google发布的这篇文章对大语言模型在应用侧的发展有很积极的意义。LLM目前还是聚焦在文本上,因为是语言模型啊。但是这篇文章在研究的是如何让LLM看懂UI,并可以和文本内容进行转化相互转换:比如,看到UI内容进行提问、理解屏幕展现的主要内容是什么、让大模型看图阅读理解,还有一个就是像人一样去操作(这个我觉得是RPA的增强版)。
英文原文:Enabling conversational interaction on mobile with LLMs
2023年5月12日星期五
由谷歌Research的学生研究员Bryan Wang和研究科学家Yang Li发布
移动设备上的智能助手已经显著提升了基于语言的交互,例如设置定时器、打开手电筒等简单日常任务。尽管取得了进展,但这些助手在支持移动用户界面(UI)中的对话式交互方面仍存在很大局限。例如,无法回答关于屏幕上显示的特定信息的用户问题。助手需要具有图形用户界面(GUI)的计算理解能力,才能实现这种功能。
先前研究调查了几个重要技术构建块,以启用与移动端 UI 的对话式交互,包括为用户总结移动屏幕以快速理解其目的、将语言指令映射到 UI 操作和建模 GUI 使其更适合基于语言进行交互。然而,每个构建块只涉及对话式交互中有限方面,并需要大量精心策划大规模数据集和训练专用模型。此外,在移动 UI 上可能发生各种各样的对话式交互。因此,必须开发一种轻量级、通用化方法来实现对话式交互。
在 CHI 2023 上发布《利用大型语言模型实现与移动 UI 的对话式交互》,我们调查了利用大型语言模型(LLMs)实现与移动 UI 的多样化对话式交互的可行性。最近的预训练LLM(如PaLM)已经展示了自适应各种下游语言任务的能力,只需提供少量目标任务的示例即可。我们提出了一套Prompt技术,使交互设计师和开发人员能够快速原型化和测试与用户的新语言交互,从而节省了在投资专用数据集和模型之前的时间和资源。由于 LLMs 只接受文本token作为输入,因此我们贡献了一种生成移动 UI 文本表示形式的新算法。我们的结果表明,该方法使用每个任务仅两个数据示例即可实现竞争性表现。更广泛地说,我们展示了LLMs从根本上改变未来的“会话交互设计”流程的潜力。
通过UI对LLMs提示
通过prompt,LLMs支持上下文少样本学习——而不是为每个新任务微调或重新训练模型,只需使用目标任务的几个输入和输出数据示例即可提示LLM。对于许多自然语言处理任务(例如问答或翻译),少样本prompt的表现与针对每个任务训练模型(穷举)的基准方法效果是差不多的。但是,语言模型只能接受文本输入,而移动端UI却是多模式的,在其视图层次结构数据中包含文本、图像和结构信息(即包含UI元素详细属性的结构化数据)和截图。此外,将移动端屏幕的视图层次结构数据直接输入到LLMs中并不可行,因为它包含过多信息,如把每个UI元素的详细属性等内容都写出来,那可能超过LLMs输入的token长度限制。
为了解决这些挑战,我们开发了一系列让大语言模型(LLMs)可以“看懂”移动端UI的技术。我们提供了一种算法,使用深度优先搜索遍历将Android UI 的视图层次转换成HTML语法生成移动UI 的文本表示形式。我们还利用思维链提示技术,将一些生成的中间结果合理拼接起来,一并推给LLM以得出最终的推理能力。

我们的快速设计始于一个前言,它说明了prompt的目的。前言后面是多个实例,包括输入、思维链(如果适用)和每个任务的输出。每个实例其实就是一屏(移动端屏幕)的元素转化为HTML的各种语法输入。根据输入,可以提供思维链以引导LLMs进行逻辑推理。由于这一步骤是可选项,所以在上面的动画中没有显示。任务输出是目标任务所需的结果,例如屏幕摘要或用户问题答案等。通过在prompt中包含多个示例,可以实现少量提示功能。在预测过程中,我们将新输入屏幕附加到prompt末尾并将其馈送给模型。
实验
我们进行了四项关键建模任务的全面实验:
- (1)屏幕提问生成
- (2)屏幕摘要
- (3)屏幕问答
- (4)将指令映射到UI操作。
实验结果表明,我们的方法在每个任务只使用两个数据示例的情况下就达到了比较好的性能。
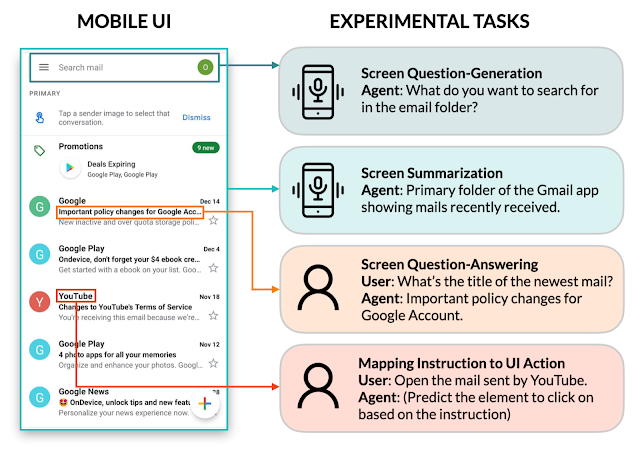
任务一:屏幕提问生成
给定一个移动UI屏幕,屏幕提问生成的目标是综合相关用户输入所需的UI元素,产生连贯、语法正确的自然语言问题。
我们发现LLMs可以利用UI上下文来为相关信息生成问题。相比于启发式方法(基于模板的生成),LLMs在提问的质量方面表现显著优异。

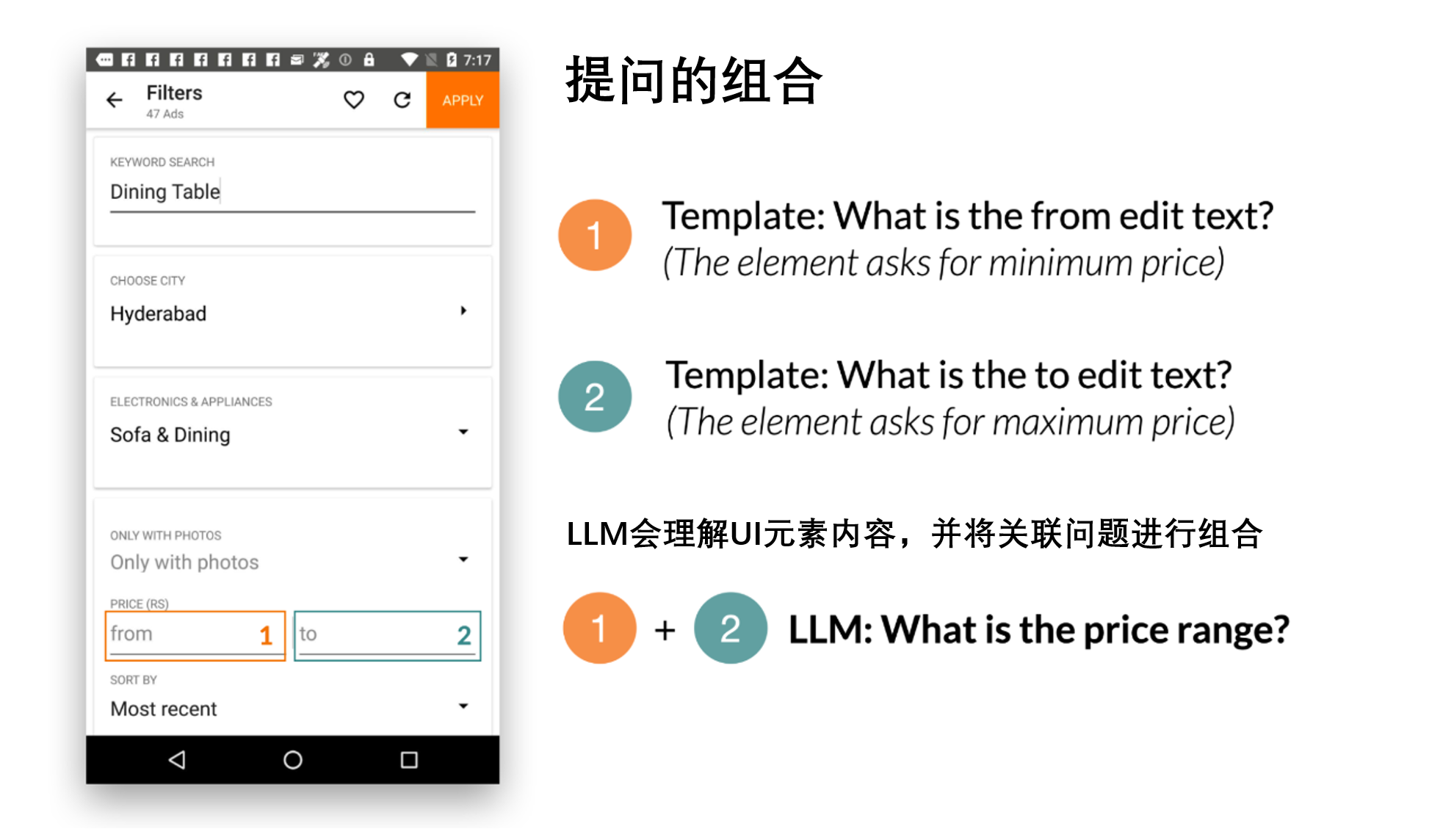
我们还展示了LLMs将相关的输入字段组合成一个问题以实现高效沟通的能力。例如,要求最低和最高价格的筛选器被合并为一个问题:“价格范围是多少?
在一次评估中,我们征求了人类对提问的语法正确性(Grammar)和与其生成所需输入字段相关性(Relevance)的评分。除了人工标注的语言质量外,我们还自动检查了LLMs覆盖生成问题所需所有元素的能力(Coverage F1)。我们发现,由LLM生成的问题几乎完美无缺地符合语法规范(4.98/5),并且高度相关于屏幕上显示的输入字段(92.8%)。此外,LLM在全面涵盖输入字段方面表现出色(95.8%)。
| Template | 2-shot LLM | |
|---|---|---|
| Grammar | 3.6 (out of 5) | 4.98 (out of 5) |
| Relevance | 84.1% | 92.8% |
| Coverage F1 | 100% | 95.8% |
任务2:屏幕摘要
屏幕摘要是自动生成描述性语言概述,涵盖移动屏幕的基本功能。该任务有助于用户快速了解移动端UI的目的,特别是当UI在视觉上不可访问时。
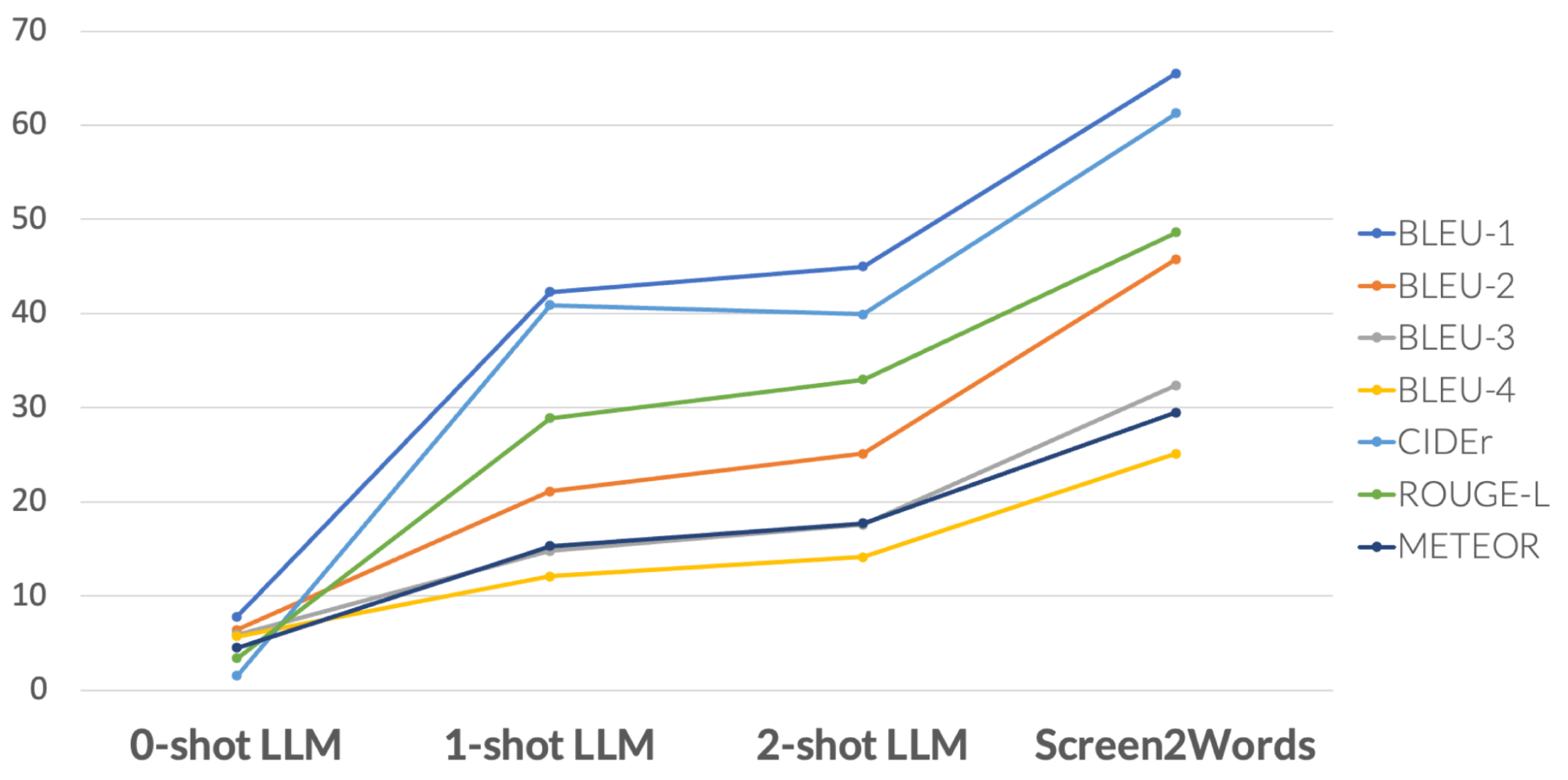
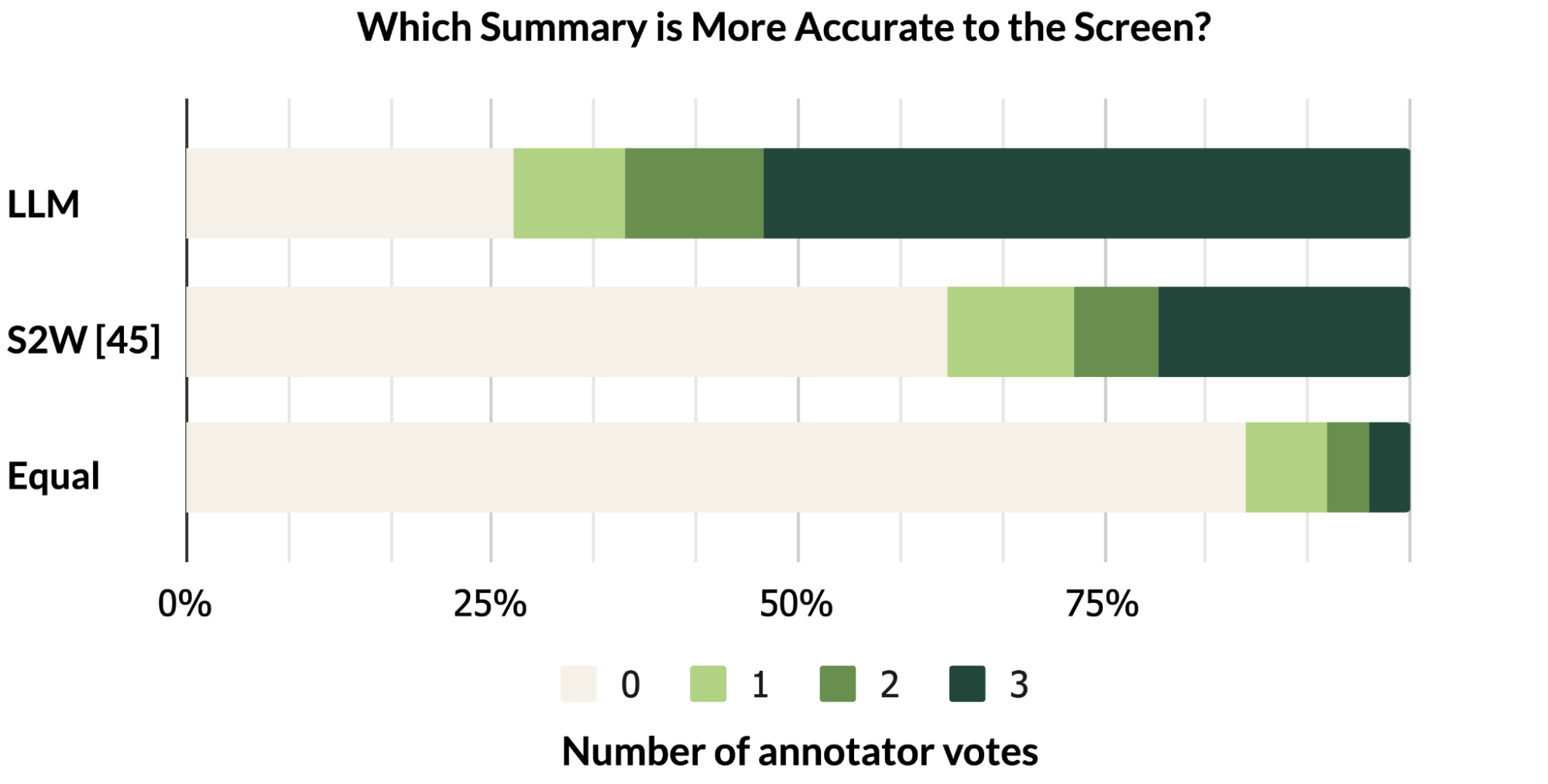
我们的研究结果表明,LLMs可以有效地总结移动端UI的基本功能,它们可以生成比我们之前使用UI特定文本介绍的Screen2Words基准模型更准确的摘要,如下面着色文本和框所示。
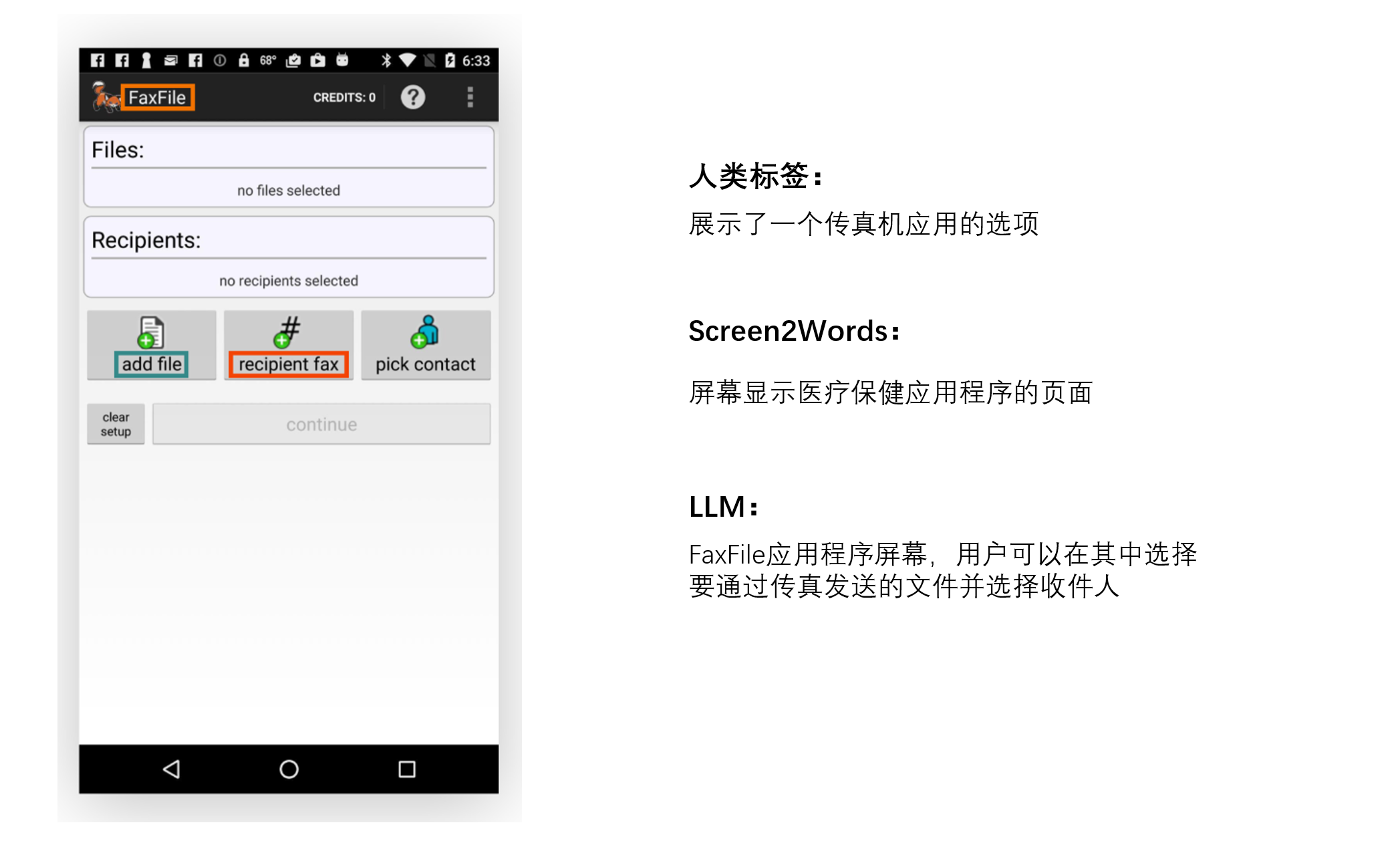
有趣的是,我们观察到LLMs在创建摘要时,利用他们的先前知识来推断未在UI中呈现的信息。
在下面的例子中,LLM推断地铁站属于伦敦地铁系统,而输入UI并不包含此信息。
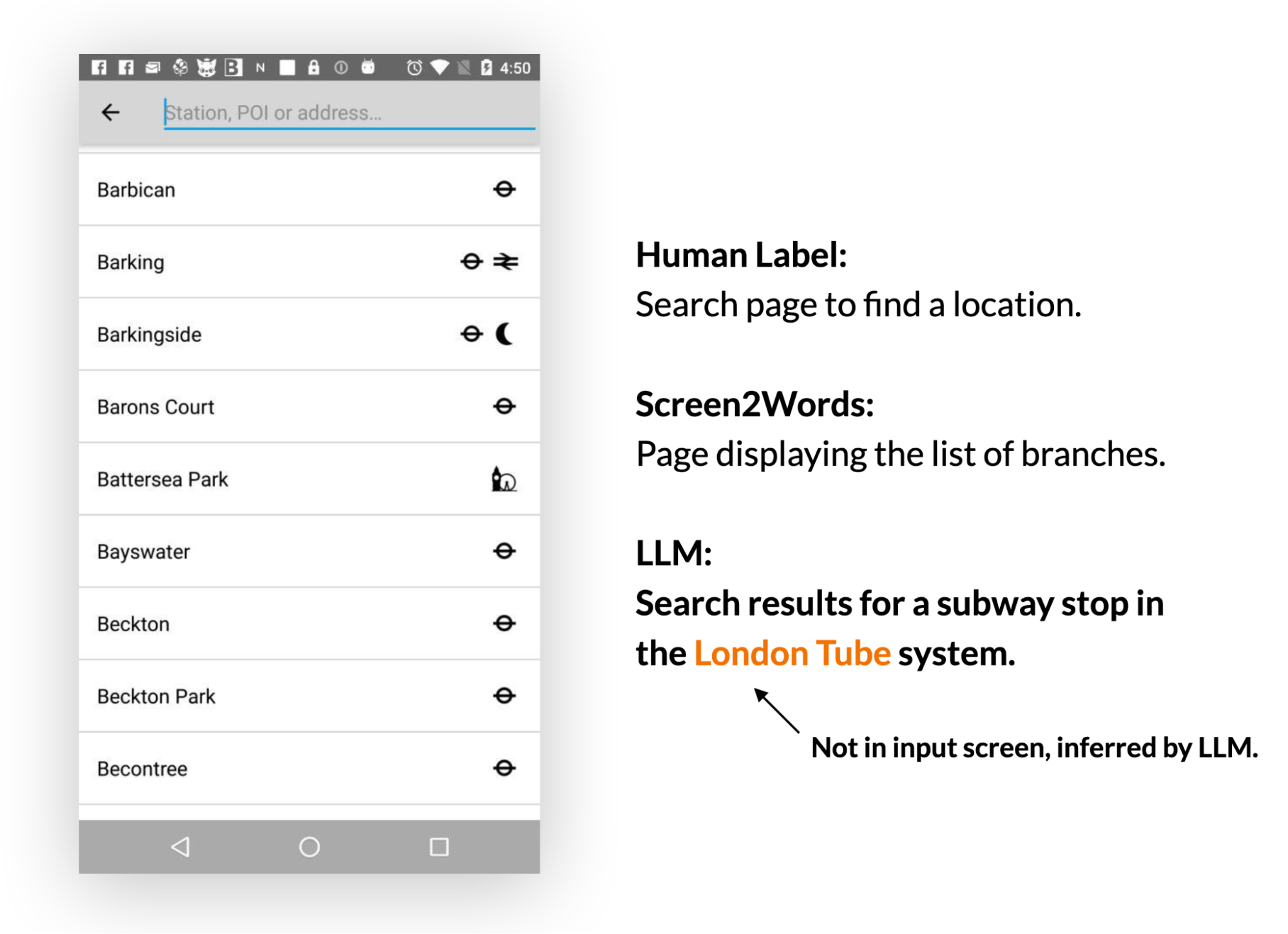
人类评估认为LLM摘要比基准更准确,但它们在BLEU(是一种用于评估机器翻译从一种自然语言到另一种自然语言的文本质量的算法)等指标上得分较低。感知质量和度量分数之间的不匹配反映了最近的研究结果,即尽管自动度量没有反映出来,LLM撰写的摘要更好。
任务三:屏幕问答
给定一个移动端UI和一个开放式问题,要求提供有关UI的信息,模型应该提供正确的答案。我们专注于事实性问题,这些问题需要基于屏幕上呈现的信息来回答。
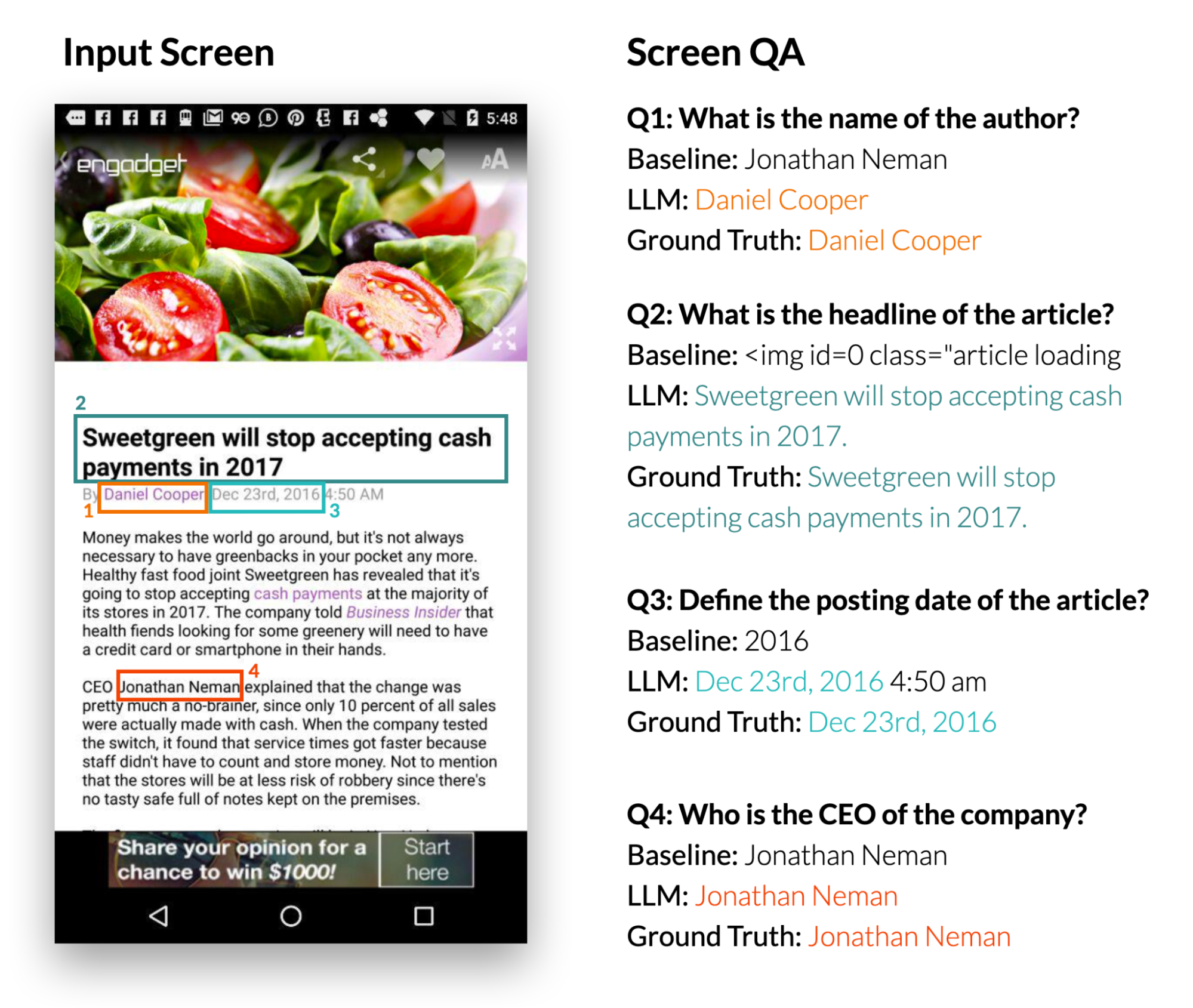
我们使用四个指标来报告性能:完全匹配(预测答案与真实答案完全相同)、包含真实答案(回答完整地包含了真实答案)、子字符串匹配(回答是真实答案的子字符串)以及基于整个数据集中预测和真实答案共享单词的微型F1分数。
我们的结果表明,LLM可以正确回答与用户界面相关的问题,例如“标题是什么?”。 LLM比基线QA模型DistillBERT表现显著更好,达到了66.7%的完全正确率。值得注意的是,0-shot LLM取得了30.7% 的精确匹配分数,这表明该模型具有固有的问答回复能力。
| Models | Exact Matches | Contains GT | Sub-String of GT | Micro-F1 |
|---|---|---|---|---|
| 0-shot LLM | 30.7% | 6.5% | 5.6% | 31.2% |
| 1-shot LLM | 65.8% | 10.0% | 7.8% | 62.9% |
| 2-shot LLM | 66.7% | 12.6% | 5.2% | 64.8% |
| DistillBERT | 36.0% | 8.5% | 9.9% | 37.2% |
任务4:将指令映射到UI操作
给定一个移动端UI屏幕和自然语言控制UI的指令,模型需要预测执行指示动作的对象ID。例如,当使用“打开Gmail”进行指导时,模型应正确识别主屏幕上的Gmail图标。这个任务对于使用语音输入等语言输入来控制移动应用程序非常有用。我们之前介绍过这个基准任务。
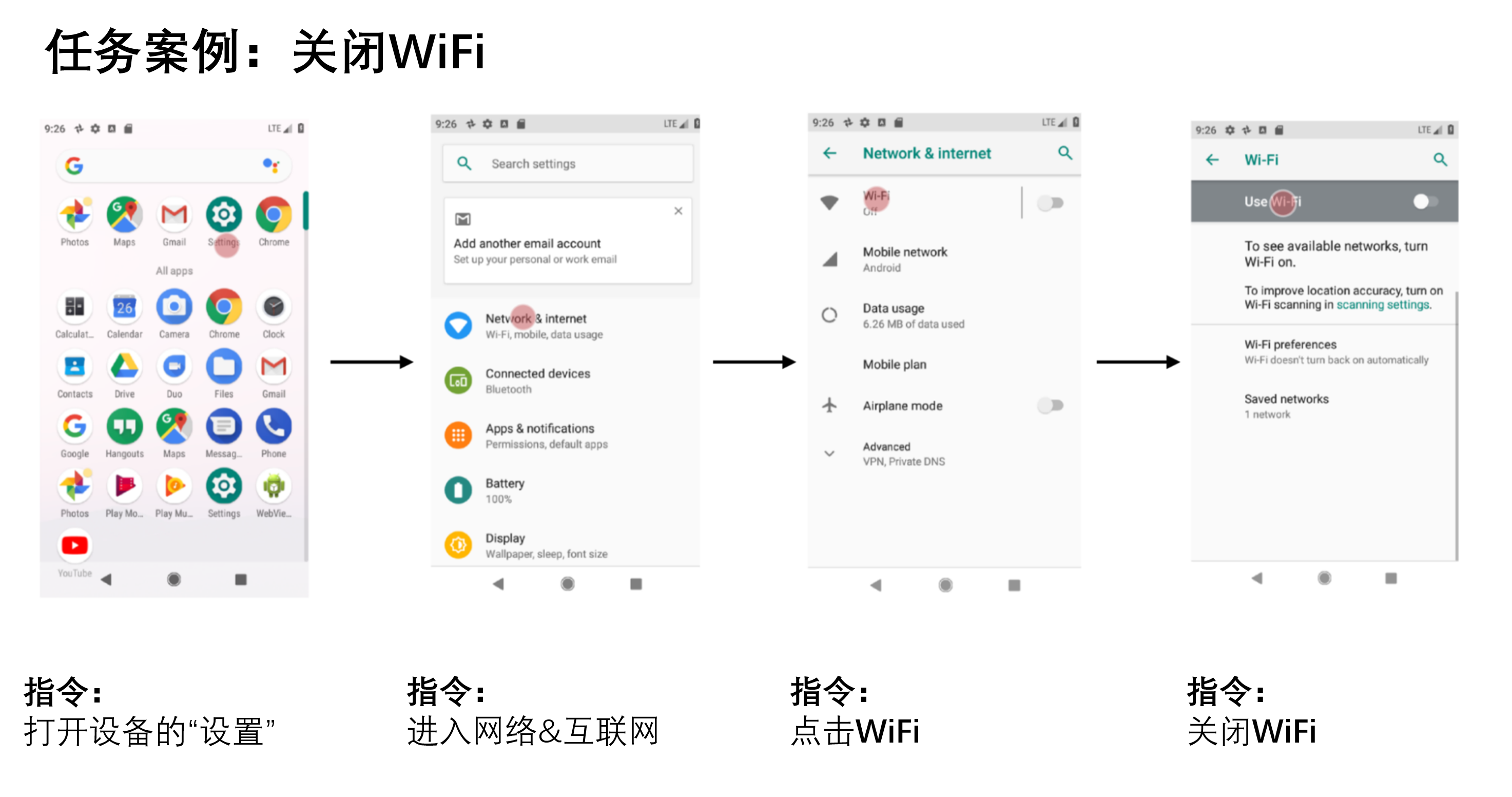
我们使用Seq2Act论文中的Partial和Complete指标评估了我们方法的性能。Partial指正确预测单个步骤的百分比,而Complete则衡量准确预测整个交互跟踪的部分。虽然我们基于LLM的方法没有超过在大规模数据集上训练得到的基准结果,但仅仅使用两个提示数据示例就取得了显着表现。
| Models | Partial | Complete |
|---|---|---|
| 0-shot LLM | 1.29 | 0.00 |
| 1-shot LLM (cross-app) | 74.69 | 31.67 |
| 2-shot LLM (cross-app) | 75.28 | 34.44 |
| 1-shot LLM (in-app) | 78.35 | 40.00 |
| 2-shot LLM (in-app) | 80.36 | 45.00 |
| Seq2Act | 89.21 | 70.59 |
结论与总结
我们的研究表明,在移动端UI上原型设计新语言交互可以像设计数据示例一样容易。因此,交互设计师可以快速创建功能模拟以测试与最终用户的新想法。此外,开发人员和研究人员可以在投入大量精力开发新数据集和模型之前探索目标任务的不同可能性。
我们调查了促使LLMs能够在移动端UI上实现各种对话交互的可行性。我们提出了一套提示技术,用于适应LLMs到移动UIs中。我们进行了广泛的实验来评估我们方法的有效性,并针对四个重要建模任务进行了比较。结果显示,与传统机器学习流水线(包括昂贵的数据收集和模型训练)相比,使用LLMs可以快速实现新颖基于语言的交互,并取得竞争性能。
致谢
感谢本文合著者Gang Li, 以及同事Chin-Yi Cheng、Tao Li、Yu Hsiao、Michael Terry 和 Minsuk Chang 的讨论和反馈意见。特别感谢Muqthar Mohammad 和Ashwin Kakarla 在协调数据收集方面提供宝贵帮助。感谢John Guilyard为博客创建动画和图形。



