我的学习笔记
土猛的员外
RAG的2024—随需而变,从狂热到理性
转眼到了2024年尾,和小伙伴一起创立TorchV也接近一年。虽然这一年做了很多事情,但从技术层面上来说,RAG肯定是不得不提的,所以今天分享一下作为大模型应用创业者所感知的这一年,RAG技术和市场环境的变化。
首先申明,本文更多来自于本人主观感受,且内容更多是回顾性的结论,不建议作为其他文章的引用材料。
主要内容包括:
- RAG技术变化
- 主要架构变化
- 技术细节变化
- 市场需求变化
- 上半年:AI无所不能,大而全;
- 下半年:回归理性,小而难;
- 明年预测:应用才是王道;
- 从业者变化。
其中技术部分放在上篇,市场需求变化放在下篇。
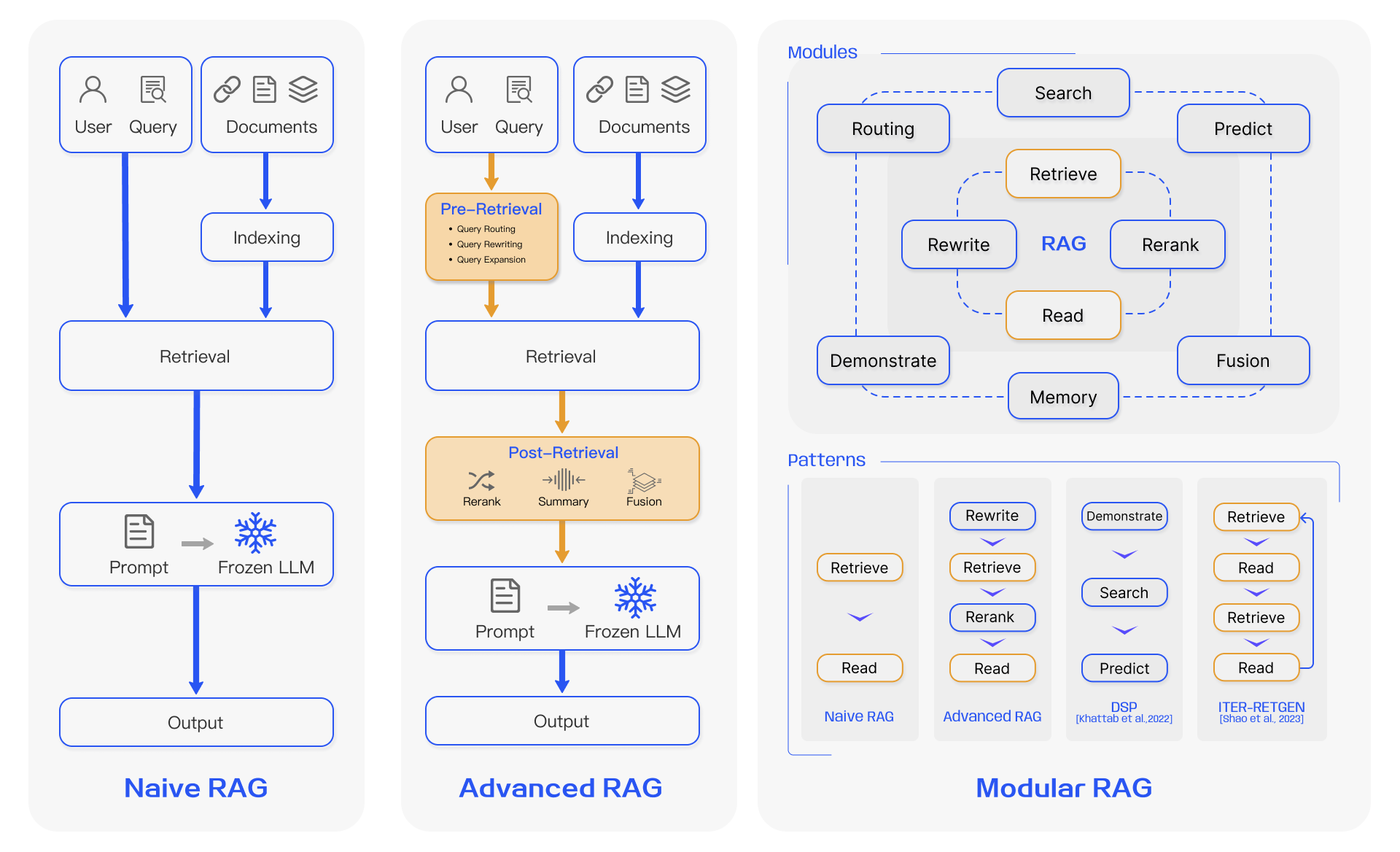
一、RAG技术变化
RAG(检索增强生成)其实是由两部分组成的,分别是检索和大模型生成。当然,既然有检索就必然会先有索引,包括chunking、embedding等动作都是为了建立更好的索引。因为我们之前从零开始创建并运营了一个千万级用户的智能问答类产品,所以在2021年左右其实就已经采用Java技术栈在使用RAG里面“RA”的大部分技术了。在2023年年中,RAG这个词突然火了起来,于是我们就立马就扑进去了,而且相信RAG在企业应用领域比纯粹使用大模型会更具实用性,至少在三年之内是这样的(随着最近传闻Scaling Law遇到瓶颈,好像这个时间还有可能被推后)。短短几个月,RAG开始的火爆程度甚至有超过LLM的趋势,在2024年1月我甚至还参加了“共识粉碎机”的EP15讨论会,主要话题就是“2024年是否会成为RAG元年?”。
【翻译】RRF — 如何在 RAG 中对多种检索方法的结果进行评分
原作者:Deval Shah
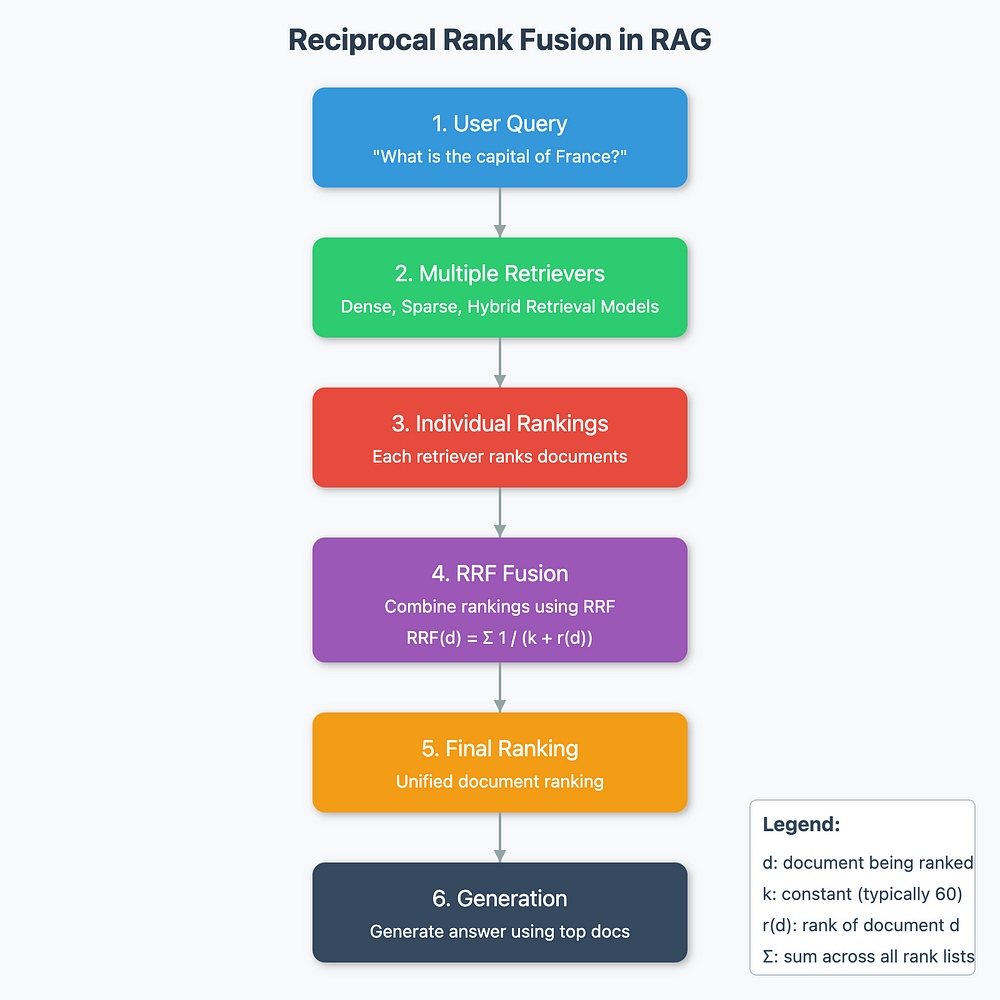
图:RAG 中的倒数秩融合(图片由作者提供)
检索增强生成 (RAG) 是自然语言处理中的一种强大技术,结合了基于检索的模型和生成模型的优势。
检索阶段可以成就或破坏您的 RAG 管道。
如果检索器未能从检索器中获取相关文档,则精度较低,幻觉的可能性会增加。
有些查询适合基于关键字的检索技术,如 BM25,而有些查询在密集检索方法中可能表现得更好,其中我们从语言模型嵌入了 embedding。有混合技术可以解决这两种检索方法的缺点。
在这篇博文中,我们将深入探讨 RRF、它的机制、数学直觉和在 RAG 系统中的应用。
什么是倒数秩融合?
聊个5分钟的企业AI应用需求变化趋势


介绍TorchV AI的两款应用,做简洁却重要的事情
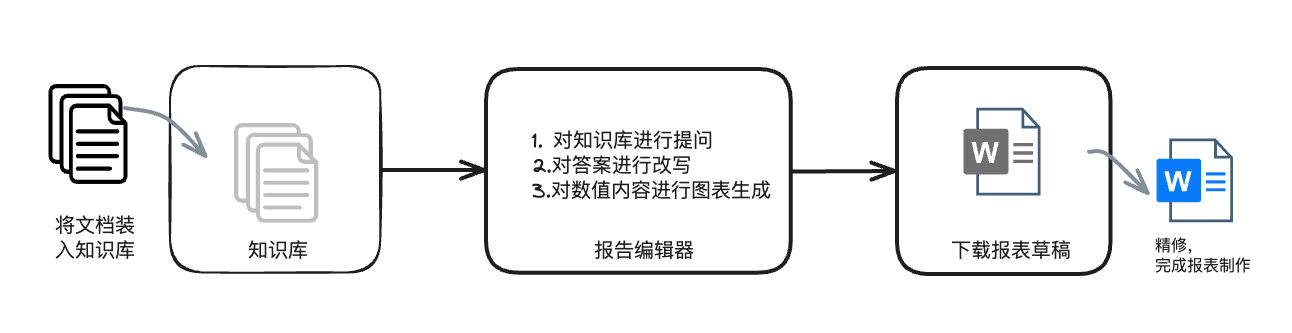
写在前面
在我的产品研发生涯中,出品的产品已经超过十个了,有 toG、toB也有toC,有复杂的,也有非常简单的。回顾这十多个产品,也发现一个有意思的想象,但凡现在依然还被很多客户在使用的,往往都是目的很纯粹的产品,至少从产品初衷来说,都是仅为了解决一个核心问题的。而那些单个产品就带有很多功能的toG系统,现在基本上都已经被扔进垃圾桶了……
所以在我和八一菜刀自己出来创业之后,就“立志”要做简单但强大的产品。
- 简单:也就是上面说的产品的初衷非常单纯,就是去解决一个问题;
- 强大:这可能有多个解释,如对客户非常有效,有很高的使用价值;产品使用体验非常好,上手很快,能被广泛使用;产品性能好,性能稳定,可解释性(可控)强。
稀土掘金分享——RAG在企业应用中落地的难点与创新(文字稿)

0629讲稿
以下是我在2024年6月29日上午在北京富力万丽酒店举行的稀土掘金开发者大会RAG专场的分享内容,包括文字稿,一并分享给大家!

朋友们,上午好!
我叫卢向东,来自杭州,今天为大家分享的是我们在大模型应用的企业落地时碰到的一些关于RAG的难点和创新。

可能很多朋友认识我是因为公众号“土猛的员外”,从去年6、7月份开始持续分享了关于RAG和大模型的一些文章和观点。现正在和几个伙伴一起创业,担任杭州萌嘉网络科技(也就是TorchV)的CEO。
今天在这里想和大家分享的主要内容,是关于我们在大模型应用的企业落地场景中遇到的一些问题,以及一些落地的产品案例。我一共会分享四个难点,三个应用案例,然后把一些个人对这一领域的思考放在最后面。希望能从不同视角给大家带来一些大模型应用在企业落地实践中的内容。
OK,那现在我们就进入第一Part,来讲讲我们在实践中遇到的问题。
TorchV AI用户手册0609
title: 用户手册-快速入门
slug: /getting-started
displayed_sidebar: mainSidebar
版本历史
| 版本 | 作者 | 日期 | 备注 |
|---|---|---|---|
| beta v1.0.0 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net) | 2024/02/28 | 初始化 |
| beta v1.6.0 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net) | 2024/03/31 | 正式版本v1.0 |
| beta v1.7.0 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net)、厉杭波(lihangbo@mengjia.net) | 2024/04/11 | 正式版本v1.1 |
| beta v1.7.3 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net)、厉杭波(lihangbo@mengjia.net) | 2024/05/07 | 正式版本v1.2 |
| beta v1.7.5 | 卢向东(yuanwai@mengjia.net)、肖玉民(xiaoymin@mengjia.net)、厉杭波(lihangbo@mengjia.net) | 2024/06/07 | 正式版本v1.3 |
1.引言
1.1 编写目的
本手册旨在介绍TorchV AI用户端的业务及操作流程,以便用户能更有效地进行业务处理和操作。
主要内容

1.2 读者对象
使用TorchV AI产品的运营人员及技术人员
1.3 环境要求
浏览器:Chrome 100+/火狐(FireFox)/Microsoft Edge
1.4 产品架构说明
本文不展示具体产品架构,如您需要查看TorchV产品架构,请点击TorchV产品架构查看。
2.快速开始
LLM企业应用落地场景中的问题一览 |LLM |RAG |Agent |TorchV
最近两个多月写文章的频率明显低了很多,不是因为懒了,而是忙着做LLM应用的客户场景落地去了。今天把客户场景落地中的一些心得总结分享一下,希望对广大期望LLM应用落地的企业有一些帮助。
前述
与很多企业客户的深度接触之后,发现绝大多数企业在LLM应用落地中存在三个显著问题,这些企业包括世界500强企业、央企、著名品牌公司,也包括和我们一样但非AI行业的创业公司,所以从样本上来说应该有一定的参考下。然后再分享一下我们在落地过程中碰到的各种难点和需要客户一起决策的点。
三个问题
- AI思维:就像以前大家常说的“互联网思维”一样,AI思维接下来肯定会被越来越多提及。其实所谓的“XX思维”没这么玄乎,说到点子上,其实就是想了解更多已经在开展的案例,然后结合自身情况来做“复制”或创新;
- 快速工具:企业工作人员使用LLM很简单,一个浏览器就可以。但是要把LLM的能力结合到自身的业务应用和系统中就没那么容易。需要对接LLM的API、控制幻觉、管理知识库、让RAG的准确度、相关性达到企业应用水平,还需要和自己的应用相结合等。绝大多数企业更希望将自有的研发人员(AI研发人员稀缺是普遍现象)投入到应用开发上,希望基于一个开箱即用、稳定和高质量的LLM应用开发平台来提升他们的业务水平;
- POC验证:这是大部分企业开始都没有提出来的,但却是最影响签约的环节。企业客户需要一套有说服力的POC评测方案,在评测结果上得到满意效果之后,企业内部决策(购买)才会变得更加顺畅。
【翻译】AI Agents Are All You Need
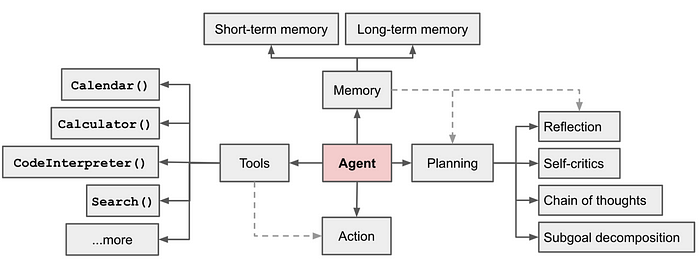
大语言模型(LLM) 已经存在了几年,它们正在迅速向 AI Agents和Agents Workflow发展。不要误解我的意思,大语言模型(LLM)是很棒的,但他们在自动化方面仍然不够有效。大语言模型与其他工具相结合是利用大语言模型(LLM)所拥有的通用智能的一种非常有效的方式,通过消耗大量的Tokens。大语言模型最大的问题是他们有迷失的倾向(幻觉和自我一致性),我们永远不知道大语言模型(LLM)或代理(Agents)什么时候会失败。在这些失败的周围几乎没有护栏,但我们还远远没有结束利用大语言模型(LLM)通用智能的全部能力。
因此,在今天的博客中,我们将深入探讨:
- 大语言模型(LLM)的未来是什么样子;
- 我们如何从RAG管道转向Agents;
- 以及创建一个可行的基于LLM的AI Agent(工具使用、Memory和规划)有哪些挑战?;
- 最后,我们研究不同类型的Agents,以及AI Agents和RAG的未来是什么样子.
探讨实现AI Agents的三种方式,不同的方式带来不同的客群和场景 |LLM |Agent |RAG
昨天去参加在上海举办的NVIDIA创业者会议,感受了AI创业的热情,还听了Dify CEO张路宇的分享。加上吴恩达在红杉分享会上对AI Agents的推动,带动了国内大量自媒体对AI Agents的狂轰滥炸。所以也想从我自己的角度来分享一些思考。
先贴一下吴恩达分享的四种AI Agents设计模式:
- 自我反思(Reflection):可以自我修正;
- 使用工具(Tool Use):链接其他系统去做一些事情,比如把我电脑里面的未归档文件做好归档;
- 规划(Planning):类似于思维链,分解复杂任务,找到路径;
- 协作(Multiagent Collaboration):不同类型的助理(agent),可以通过协作组成一个团队或一家公司,嗯,不过目前这一步应该还需要一些时间。

本质上AI Agents是一个依赖于大语言模型(LLM)的业务组件,是LLM在企业场景落地中的手段,而且不仅一种手段。我觉得目前由三种主流的AI Agents的采用方式,纯个人观点,不代表任何官方意见。