上周算是我正式离职创业的第一周,拜访客户、行业交流、选办公场地、置办办公设备等等,很多时间不在电脑面前,所以上周没更新任何文章。嗯,那就这周补上,发两篇!

今天这篇是上周本来就想写的,就是OpenAI DevDay(开发者大会)之后,基于大模型及相关的创业项目前景如何。

OpenAI的DevDay发布会很“苹果”,展现力非常不错,给出了六大能力:
- 128K的长文本
- 使用JSON等格式进行输出格式控制
- 更广更新的知识数据,再也不能说它的知识停留在2021年了
- 多模态,结合作图的DALL·E-3,特别是目前最好的TTS
- 定制化Fine-Tuning和类RAG
- 费率和速度。
特别是128K长文本和定制化这两块,我的第一感觉是对RAG相关的创业公司影响非常大,第二感觉依然是这样,凝重ing。
相信上周大家也看到很多观点,有兴奋到不行的,有悲观到考虑关停创业项目的,当然还有很多人“置身事外”一身轻松看热闹。对于国内的AI创业者来说,希望也好,失望也罢,还是要做到“理性分析,激情实践”,我们需要先去找问题:OpenAI(或大模型巨头,本文后面就用OpenAI来指代了)在哪些方面是做不好的?
OpenAI在哪些方面做不好?
一、我们认为OpenAI做不到的
01 不可能适配任何行业?
做技术的同学都知道分布式系统里面的CAP理论,也就是Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性)三者不可能同时成立,好像很多人就是拿CAP理论说法(怼)自己老板的既要、也要、更要想法是不切实际的。
确实,OpenAI就算再厉害,也不可能对所有行业都懂啊,所有“不可能适配任何行业”貌似是对的。我们需要开发外卖APP来服务外卖企业或用户,我们需要开发税务软件来帮助财务人员梳理和计算税务。各个行业是有自己的独特性的,一个产品不太可能适配所有。
但是,这波AI浪潮也以前是不一样的——因为交互发生了变化:我们现在不是靠专业的UI/UE来做人机交互,而是使用对话(Prompt),这就极大降低了使用的学习成本。至少绝大多数行业的人都可以使用它来帮助自己工作。
所以,不可能适配任何行业这一条,是不成立的,我们不要抱着这样的幻想。
02 时效性和输入内容长度?
以前我们经常讲到LLM的两个劣势:时效性和输入长度,然后引出RAG的优势。但是,现在128K的输入长度,以及可以个性化定制的GPTs,一下子把这两个劣势弥补了,对于RAG创业者来说,确实是当头一棒,包括我们。
所以,时效性和输入长度也不是OpenAI做不了的。
03 OpenAI新功能华而不实?
在公众号《夕小瑶科技说》11.11那篇文章里面提到了一些国外大佬对GPT-4的评测情况,说实话不是太理想,我这里只发布结论,详细文章大家可以点击《GPT4 Turbo的128K上下文是鸡肋?推特大佬斥巨资评测,斯坦福论文力证结论》。
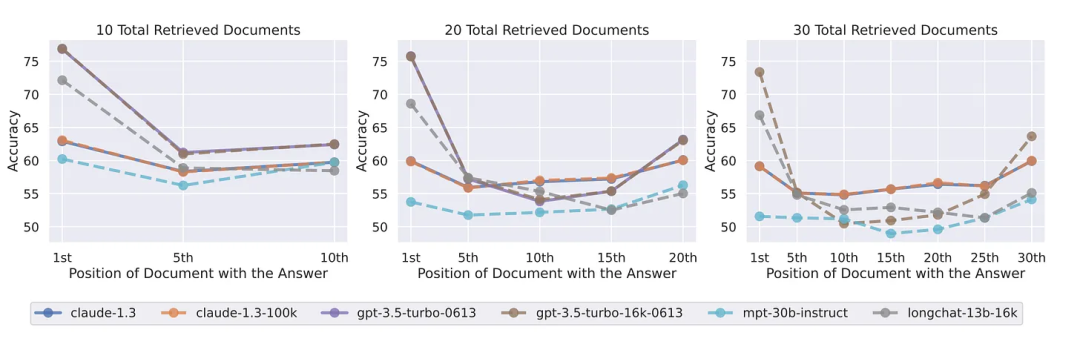
国外某科技大V Greg Kamradt对GPT-4 Turbo进行了压测,结论是:
- 只要问题的答案不是包含在开头,那么 GPT-4 Turbo 并不能保证总能找到答案;
- 更少的上下文长度=更高的准确性,减少向 GPT-4 Turbo 的输入,总会提升其表现(73K后性能下降很快);
- GPT-4 Turbo 还是偏好于在文档的开头与结尾寻找答案。
还有另外一个国外网友Louis Knight-Webb,他的实验结论是:相比 GPT-4,GPT-4 Turbo 的能力有巨大的提升,在上下文长度为 32k 的条件下,GPT-4 Turbo 的平均检索正确 2.4 个人名、城市名与动物名,而 GPT-4 仅为 1.1 个。但是,和 Kamradt 一样,Louis 同样发现,即使是 GPT-4 Turbo,在更大的上下文大小上仍然表现不佳。
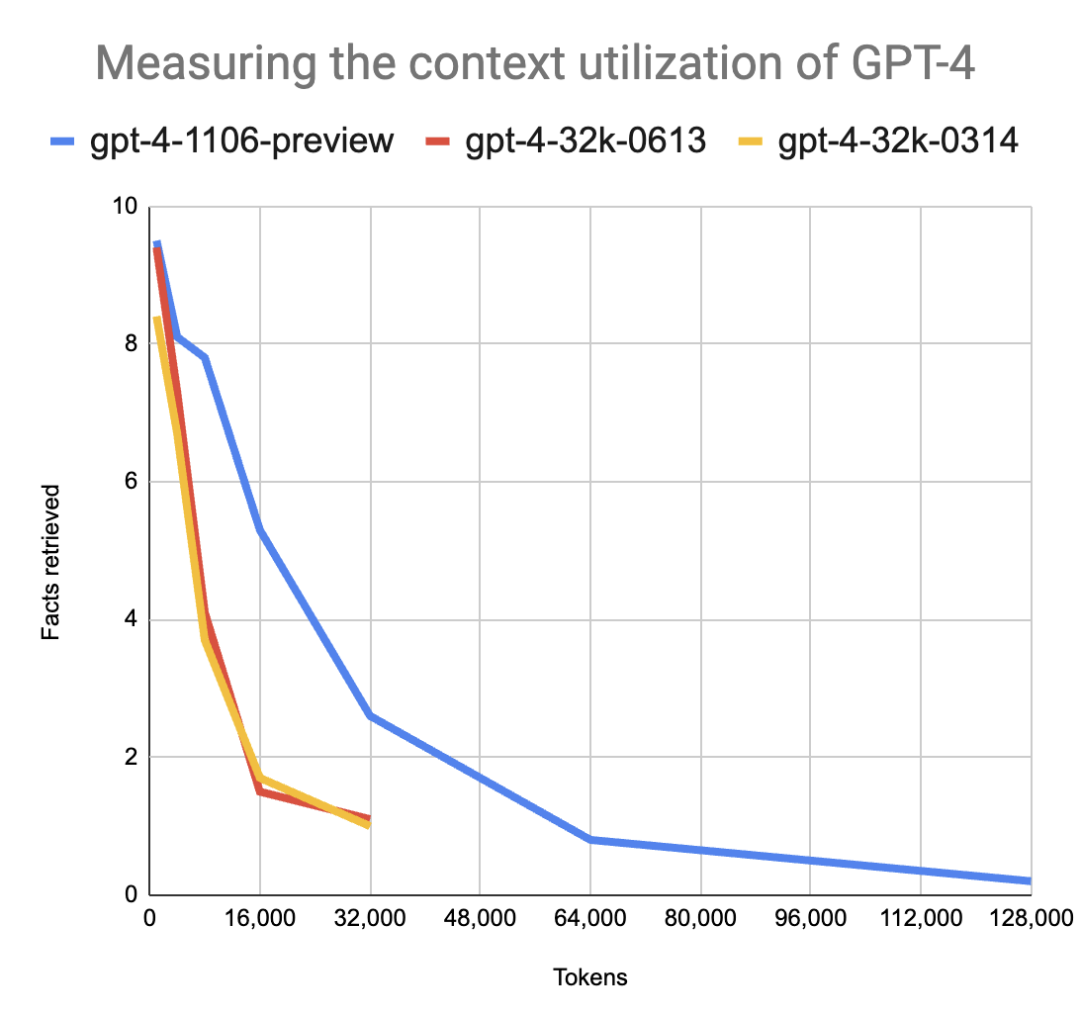
而且斯坦福大学在今年7月份就做了一些列测试并发布了论文《Lost in the Middle: How Language Models Use Long Contexts》,发现几乎所有大模型都出现了“Lost in the Middle”的现象,随着Tokens的长度越来越大,会在中间出现性能(推理速度、准确率等)坍塌。
嗯,以上这些问题,确实是真实存在的问题,但我认为这些都会随着时间慢慢被修复,这不属于核心级别的问题。所以,说OpenAI新推的这些功能金玉其外败絮其中,并没有太多意义,这依然不属于OpenAI真正做不到的事情。
二、我认为OpenAI可能真做不到的
那么,什么是OpenAI或其他大型LLM做不到的呢?我觉得可能有这么几件:
- 对敏感业务的AI赋能(本地化)
- 输入-处理-输出的稳定性
- 让用户使用更便捷
01 对敏感业务的AI赋能
OpenAI是全球性的产品平台,它不是不能而是不想为各个企业客户做本地化,但企业数据安全又是一个严肃的话题。所以,对于一些企业的生产核心机密(如云南白药和片仔癀的配方数据)和财务数据,我们不能完全保证这些数据上传到OpenAI之后,100%不会被拿来训练,一年内不会,那么十年后会不会呢?或者他们又换了一个新的CEO,哈哈。企业要保证绝对安全,那就是绝对不以任何形式将敏感数据外泄,严控源头。
所以对于敏感数据的AI能力接入,创业者在服务客户的时候,会比OpenAI有优势,我们可以针对自己的客户做本地化部署,这是特有优势。
02 稳定性
OpenAI这次推出JSON输出格式,主要就是为了帮助开发者更加严格地控制输出格式。但是LLM的稳定性不止输出这一环,还包括输入(识别)、推理和输出等多个环节,你在使用过程中肯定还遇到过其他的问题。比如你问ChatGPT同一个问题30遍,看看是否每次的答案都是正确的?我相信会有那么几次是错误的,特别是一些逻辑推理问题,但这对于企业应用来说可能就是致命的。这似乎是LLM的原生问题了,也就是我们一直说的“幻觉”。后面我可以再写一篇文章说明LLM为什么很难做到完全稳定的底层原因。
既然企业应用对稳定性非常考究,那么我们应该怎么做呢?
我们做了三大“胶水组件”,其目的之一就有对抗“幻觉”:
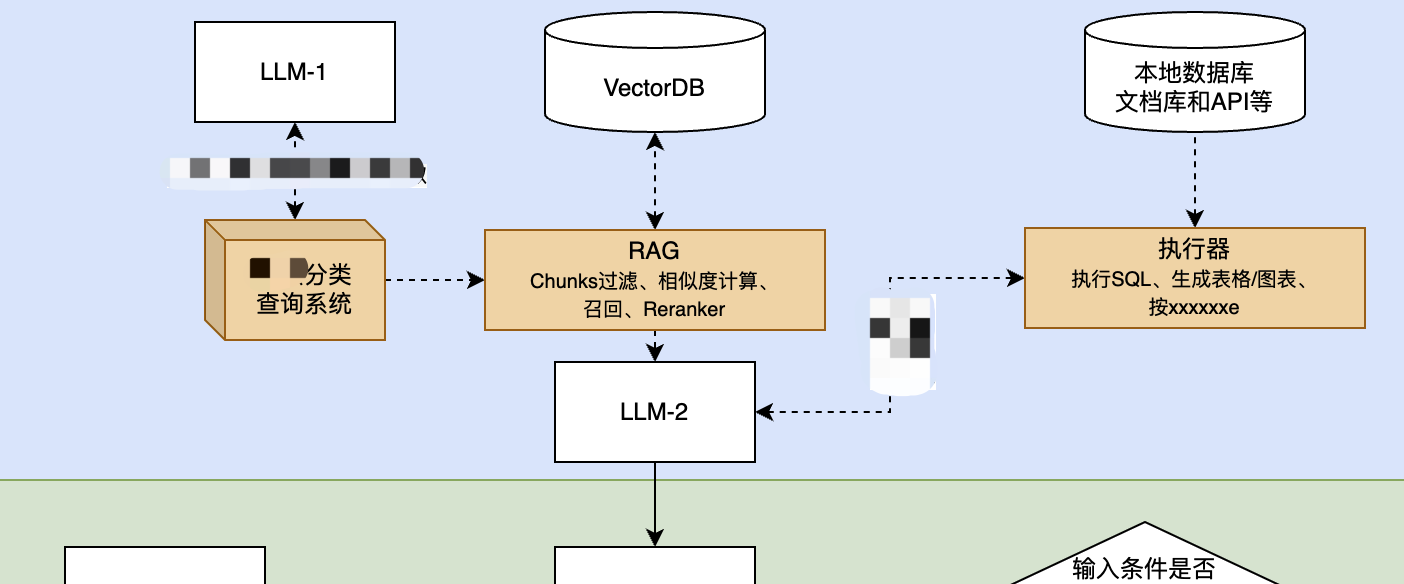
为了获得稳定性,我们最重要的是做了“XX分类查询系统”,帮助LLM更加准确地理解业务。在输入环节(针对大模型来说是输入)利用一些“幂等”系统来保证整个流程的(识别)稳定性,其实说起来就是如果影响最终结果稳定性的因素有5个,那么,我们先帮助LLM解决掉其中的3个。
分类器:处理元数据、实体识别等,尽量把信息识别做到幂等;
RAG:这套技术可以说非常复杂(或者说从易到难跨度很大),我们相信它依然非常有生命力,因为看到了它在企业应用中的重要价值,甚至可以说它是LLM这一波带出来的最得民心的明星之一。
执行器:不是必须的,我们把它列为我们的三大“胶水组件”套装是因为需要有自己的端到端生成风格,包括HTML5、APP,以及API(对接机器人、数字人等),另外就是对于输出格式的稳定性做了一些要求。
好了,本文我就只谈概念,不过多讲我们的产品细节了,期待新产品和大家见面!。
03 易于使用
我前面在说行业适配的时候说过,类似OpenAI的GPT-4 Turbo这样的产品现在已经可以轻松跨行业了。一是因为多模态让输入更加轻松,二是对话方式的输入让人机交互变得无障碍。
但是问题就在这第二点,Chat(对话)方式的交互是好,却很难把控。
如果你是老司机(不开玩笑的),相信你已经达到人车合一了,你的双手和脚已经和你的大脑形成了“天衣无缝”的配合。好,这时候,要求你不能用手和脚,只能用嘴巴来交流:“左、左、右,再右一点…慢一点…可以再快一点…停停停!快刹车!”。好了,估计你已经体会到Chat方式并不是万能的了,至少现阶段肯定不是。当然,如果未来你只需要说去某某地方,然后车子就自己带你去了(我说的难道是特斯拉自动驾驶?),那Chat的交互形式倒也是不错的。
对于易于使用,上面这段话里面我至少说了两个信息:
- 现阶段,甚至很长一段时间还是需要创造更适合行业用户使用的应用,而不是全靠对话。这也是我们接下来的主要工作:为商业注入AI力量;
- 另外,会有那么一天,我们只要说出起点——终点,其他的事情由AI全权代理完成。当然你应该不喜欢它代替你吃饭、睡觉、玩游戏、谈恋爱。
同样的,我们可以思考:现阶段我们其实做的是**+AI(即:现有任务+AI),以后可能做的就是AI+**(新的任务)。
最后
好了,OpenAI、微软和谷歌这些AI巨头肯定会不断往前进,本文主要说的是基于LLM的创业者还是要看清楚自己在哪些方面是具备不可替代性的。思考这个问题的时候,我们不妨先提出一个问题,比如OpenAI不会做哪些事情,那也就是我们可以做的方向:我认为是私有化、稳定性、让用户更易于使用。
PS:今天最大的新闻应该是Sam和Greg加入了微软,后面微软会不会挥起镰刀?Sam和Ilya之争会不会让创业者获得更多机会?不好说,且看,且思考,且实践。
本周会写两篇补上周的,后一篇是分析“LLM、LoRA和梯度下降”相关的文章,我希望用大部分朋友都能看懂的语言把这个主题写出来,也解释为什么稳定性在LLM里面本来就是“不正确”的思考方式。

