ChatGLM3-6B来了
上周又新出来一个新的国产大语言模型——ChatGLM3-6B,据说这次他们还另外上线了3B和1.5B两个模型,但是没有选择开源。这类小体量的模型如果能力OK的话,应用前景是非常广的,可以作为桌面应用,甚至在手机上就可以部署。
好,不说这么多,今天我们先来看看ChatGLM3-6B的能力相比之前的ChatGLM2-6B是否有较大提升。
周末的时候我下载了ChatGLM3-6B的模型文件,这次的文件大小和ChatGLM2-6B几乎是差不多的。甚至我开始都觉得可能是同一份model文件,但是使用ll命令看详细字节数,每个文件的大小是不同的,所以我还是重新下载了一份。
说实话,对于ChatGLM2-6B我还是比较失望的,从年初的惊艳,到后面的泯然众人,ChatGLM2-6B在我们RAG应用中已经完全不适用了,连基本的归纳都做不好,我们本来是把离线大模型的希望都寄托给它的。后续在一些应用中,我们使用在线大模型是智谱(ChatGLM所属公司)的Lite版和Pro版,这两个能力上还行。
但是离线需求肯定是一个刚需,特别是对于企业客户,他们不希望自己的机密数据文件被上传到在线大模型,所以后面Baichuan2-13B出来之后,离线的大模型,我们就开始转向了百川。但是百川的13B也有个问题,就是对GPU要求很高,非负载状态下需要18GB的显存,也就是需要至少4090的显卡(24GB),而目前市面上数量较多的3090显卡(16GB)则无法胜任。所以对于此次ChatGLM3-6B的公布,我很激动,希望可以为后面的RAG应用做一个相对性价比较高的配置方案。
测试方法
首先我必须说,我不去做科学的对比测试,如果你需要看官方评测,我也可以贴一个ChatGLM官方给出的2和3的比较:
| Model | GSM8K | MATH | BBH | MMLU | C-Eval | CMMLU | MBPP | AGIEval |
|---|---|---|---|---|---|---|---|---|
| ChatGLM2-6B-Base | 32.4 | 6.5 | 33.7 | 47.9 | 51.7 | 50.0 | - | - |
| Best Baseline | 52.1 | 13.1 | 45.0 | 60.1 | 63.5 | 62.2 | 47.5 | 45.8 |
| ChatGLM3-6B-Base | 72.3 | 25.7 | 66.1 | 61.4 | 69.0 | 67.5 | 52.4 | 53.7 |
我想要更加”老土“一些、更加直接一些的方式,我的评测方法是这样的:
- 参加对比的模型:
ChatGLM2-6B、ChatGLM3-6B、Baichuan2-13B和ChatGPT-3.5。是的,Baichuan2-13B和ChatGPT3.5在参数体量上和6B完全不同,有点耍流氓,但是不妨作为一组对比,从更广度的对比上来看各个模型的能力; - 只测试7个问题:这次我只给出7个问题,分别包括实体提取、逻辑计算、英文翻译、归纳、计数、SQL生成和生成代码展示分析图表(问题集在分项评测中会贴出)。四个模型提交的问题都是一样的,这里需要说明一下就是ChatGLM2和3模型的Cli模式对于输入文字的显示不太友好,所以后面的截图中会出现一些显示问题,但是从答案中可以看到,实际并没有真正丢失这些信息;
- 只截取首次答案:我们都知道大模型对于同一个答案的每次结果输出会出现不太一样,比如连续问十次可能会有一次出现完全不同的结果,所以为了整个测试更加公平,我们只取第一次输出;
- 评比方法:为了让评比更简单明了,在输出中,只要基本正确,我就会判为争取。如果出现了重要的错误,影响了整体的正确性,那才会判错。我后面的各项评测截图都会贴出来,大家也可以自己分析,并得出自己的答案。
所以你看到了,这不是一次科学的评测。我最关心的还是大模型对于RAG应用中G(生成)的支撑效果。
我可以在说说我的环境:Intel i7 / 64GB / RTX 4090 / 2TB SSD,操作系统是Ubuntu Server 22.04,Python3.11,Conda环境。
分项评测
至于测试过程,我就不一一录屏了,直接上评测结果,分为7项测试,最后再加一个总结。
1.实体提取
实体和关系提取当然也可以使用NER,但是有大模型,为什么不用呢,而且它后面还可以做格式,所以在RAG应用中,我们喜欢用大模型来提取实体。而且,这种提取方式对于短句子特别有效——对的,就是对于用户的提问内容的实体提取。
Prompt:
请帮我分析一下这段话”我需要看2021年3月至7月(含)的浙江分公司的自研产品的销售数据报表“,如果包含时间,请帮我列出”时间:xxxx年xx月“这样的格式,如果包含机构,请帮我列出”机构:xxxx“,如果包含其他实体,请帮我列出”实体:xxxx/xxxx“
评测意义
这个prompt中,我们如果可以将时间、机构和其他实体先提取出来,就可以使用元数据过滤,在这么多月份的文件,这么多分公司(机构)的文件中,直接过滤掉大量不相干的文件chunk,极大提高向量相似度计算的速度。对于RAG应用来说,这是很关键的一种优化能力。
评测结果

- ChatGLM2-6B(0):完全不知道在做什么;
- ChatGLM3-6B(0.5):其实它也提取出了时间和机构,但是没有提取出其他的实体,给0.5分;
- Baichuan2-13B(1):应该说提取的比较好,最后的输出没用使用
/是个缺陷; - ChatGPT-3.5(1):提取的比较好,包括
/也给到了,但是它没有7月(含),也许是对中文理解的偏差吧。
2.逻辑计算
这是一道我用了半年多的题目,很多大模型被我考倒了。
Prompt:
小明老婆昨天生了一对龙凤胎,他们还有一个4岁的女儿,那么现在小明一共有几个孩子?分别是几个儿子,几个女儿?
评测意义
这里需要大模型对中文有一定理解能力,知道龙凤胎是一男一女,然后要去计算4岁的女儿,要做加法。如果大模型的逻辑计算能力出色,那我们可以将很多有文字有数字的内容塞给它,直接计算。比如一篇用记事本记录的今日花销流水账,直接就可以计算出来。是大模型是否”聪明“的一大体现。
评测结果
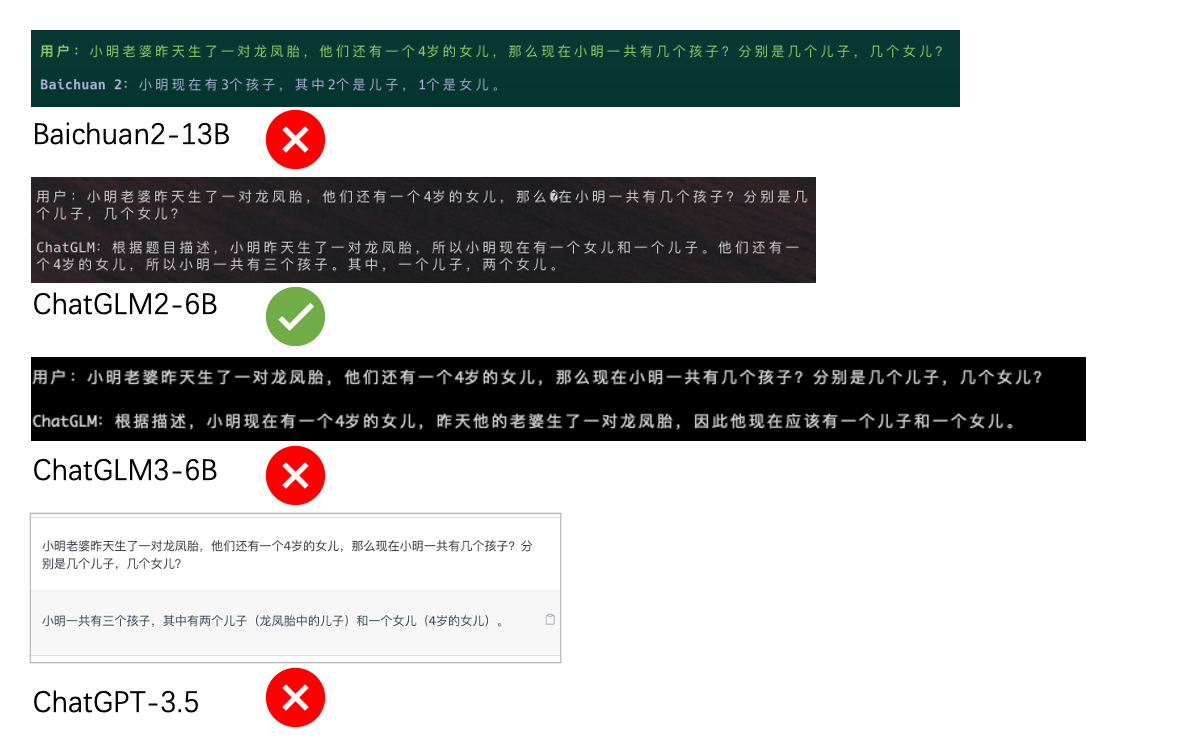
惊喜的事情来了!
这道题,居然只有被认为最弱的ChatGLM2-6B答对了!!!我之前是试过多次ChatGPT-3.5的,好像基本都是正确的,但是这次居然打错了,看来最近OpenAI算力吃紧,有意降低ChatGPT的能力是有一些依据的。
- ChatGLM2-6B(1):完全正确,惊喜;
- ChatGLM3-6B(0):错误;
- Baichuan2-13B(0):错误;
- ChatGPT-3.5(0):居然连ChatGPT-3.5都错了。
3.翻译
翻译算是一项常规技能了,特别是英文翻译成中文。
Prompt:
你是精通计算机科学的专家,并且是一位专业翻译人员,请帮我翻译以下英文内容:“With Large Language Models(LLM) such as Chat GPT, machines can interact with humans in ways that weren’t possible before. There’s a growing interest in fine-tuning these pre-trained LLM models to preserve data privacy and cater to domain-specific tasks, thanks to the democratization of open-source Large Language Models. We can find numerous posts discussing model fine-tuning and application of in-context learning (I’ve even written three articles myself.., each delving into a distinct technique). But it’s essential to grasp the fundamentals. When should you opt for fine-tuning, and when is in-context learning the better choice? How do you kickstart the process, and how do these methods fit into the bigger picture? What techniques are readily available for you to implement? In this post, we’re diving into the fine-tuning process for pretrained models, explore different fine-tuning methods, and provide a comparison of the latest state-of-the-art techniques.”
评测意义
常规技能,意义就不评价了,对于中文支持的模型,这是必备项。
评测结果

- ChatGLM2-6B(0.5):马马虎虎还是可以的,但还是有三个瑕疵。首先把fine-tuning翻译成了精调,这个也许有些不太符合习惯,一般还是用微调;第二个问题是表情符附近的myself;然后最后一句,”并比较最先进的最新状态“,语法上有些生硬;
- ChatGLM3-6B(0.8):其他都很好,也是最后一句,”并比较最先进的最新状态“,语法上有些生硬,这可能是GLM训练语料存在的问题;
- Baichuan2-13B(1):翻译的比较优质;
- ChatGPT-3.5(1):吹毛求疵一下,”机器可以以以前不可能的方式“这一句有优化空间,但是意思没错。
4.归纳
归纳应该算是RAG应用中非常重要的一项能力了,我们通过向量计算召回内容,然后让大模型进行归纳和润色,然后再输出最终结果。所以归纳的能力也不需要过多介绍了。
Prompt:
请帮我将分析一下文字的含义,然后使用不超过30个字进行归纳:我们可以看到有很多关于如何构建RAG应用程序的示例代码和开源框架(如LlamaIndex和Langchain),目前它们产出一些技术和代码案例,使用的托底LLM基本上都是OpenAI的ChatGPT。我们碰的一些已经在做RAG应用的企业,也是无一例外的在使用OpenAI。就像上面说的,这本身是正确的逻辑,因为先用目前的上限做测试,至少我们”未来可期“——等国产大模型慢慢追上来。但不得不说,ChatGPT虽然还不完美,但已经很强大了。看了这些案例之后,我们也能发现完全基于ChatGPT好像有点背离我们构建RAG的初衷,也存在一些风险: 违背设计初衷:RAG的设计初衷是减轻LLM的各类问题,比如前面说到的减少幻觉、减少费用,增加实时性。但重度依赖ChatGPT反而把RAG做成了一个大模型的客户端,有点违背帮LLM分担压力的初衷; 国内使用风险:在国内使用ChatGPT属于是两头堵的状况,OpenAI对中国大陆用户是明确禁用的,国家对于非可控信源也是有严格的使用说明的。如果你只是自己搭建在家里或者公司内容研究用,那可能风险相对较小。但是如果要基于LLM和RAG技术对外提供经营服务,那基本上你还是需要退回到使用国内经过网信办审核的大模型。 而像我们这样使用国产大模型,或使用自己本地部署的开源大模型,确实在整体效果上和OpenAI是存在一些差距的,有时候事倍功半,想想还是挺气人的。我们需要为大模型本身的能力差距做很多”胶水组件“,其实就是很多中间件,比如表格处理,使用OpenAI的话我们可以直接使用开源的PandasAI(我之前也介绍过这个库),它会产生一些代码执行语句,给到ChatGPT,就能生产很好的结果。但是在国产大模型里面,没有这么强的程序执行能力,我们就需要做一些表格存储、处理和计算的额外功能,像这样的例子还有很多。 但是这样做的好处是我们对RAG整个体系中各个环节都越来越清楚,可以快速定位到问题,知道怎么做一个胶水组件去解决问题。假以时日,国产大模型追上了GPT-3.5的水平了,那精通RAG内部各个细节的你,做出来的应用应该也会比别人的更优秀。
评测意义
RAG应用中最重要的技能之一,要保证语义不发生偏转,不能南辕北辙。
评测结果

- ChatGLM2-6B(0):出现严重错误,原文说的是使用ChatGPT有风险,结果归纳的时候变成了国产大模型;
- ChatGLM3-6B(1):非常完美;
- Baichuan2-13B(0.6):画蛇添足了,强行解释了一下RAG,结果解释错了,只能给一个0.6分;
- ChatGPT-3.5(1):非常完美。
5.统计次数
这也是一个传统艺能了,这可以帮助我们分析文章中哪些内容是比较重要的,和传统的TF-IDF是反着来的。
Prompt:
请帮我找出在后面将要给出的内容中,一共提到了多少个ChatGPT。以下是需要查找的内容:我们可以看到有很多关于如何构建RAG应用程序的示例代码和开源框架(如LlamaIndex和Langchain),目前它们产出一些技术和代码案例,使用的托底LLM基本上都是OpenAI的ChatGPT。我们碰的一些已经在做RAG应用的企业,也是无一例外的在使用OpenAI。就像上面说的,这本身是正确的逻辑,因为先用目前的上限做测试,至少我们”未来可期“——等国产大模型慢慢追上来。但不得不说,ChatGPT虽然还不完美,但已经很强大了。看了这些案例之后,我们也能发现完全基于ChatGPT好像有点背离我们构建RAG的初衷,也存在一些风险: 违背设计初衷:RAG的设计初衷是减轻LLM的各类问题,比如前面说到的减少幻觉、减少费用,增加实时性。但重度依赖ChatGPT反而把RAG做成了一个大模型的客户端,有点违背帮LLM分担压力的初衷; 国内使用风险:在国内使用ChatGPT属于是两头堵的状况,OpenAI对中国大陆用户是明确禁用的,国家对于非可控信源也是有严格的使用说明的。如果你只是自己搭建在家里或者公司内容研究用,那可能风险相对较小。但是如果要基于LLM和RAG技术对外提供经营服务,那基本上你还是需要退回到使用国内经过网信办审核的大模型。 而像我们这样使用国产大模型,或使用自己本地部署的开源大模型,确实在整体效果上和OpenAI是存在一些差距的,有时候事倍功半,想想还是挺气人的。我们需要为大模型本身的能力差距做很多”胶水组件“,其实就是很多中间件,比如表格处理,使用OpenAI的话我们可以直接使用开源的PandasAI(我之前也介绍过这个库),它会产生一些代码执行语句,给到ChatGPT,就能生产很好的结果。但是在国产大模型里面,没有这么强的程序执行能力,我们就需要做一些表格存储、处理和计算的额外功能,像这样的例子还有很多。 但是这样做的好处是我们对RAG整个体系中各个环节都越来越清楚,可以快速定位到问题,知道怎么做一个胶水组件去解决问题。假以时日,国产大模型追上了GPT-3.5的水平了,那精通RAG内部各个细节的你,做出来的应用应该也会比别人的更优秀。
评测意义
在RAG应用中,我们有时候需要统计各chunk或page中和问题相关的词频,以进行重排(rerank),所以统计也是有实际意义的。
上面这段话(从”以下是需要查找的内容:“开始),其实是有 6处 提到ChatGPT的,我们来看看各个模型的评测结果。
评测结果

- ChatGLM2-6B(0):2次,错误;
- ChatGLM3-6B(0):5次,错误;
- Baichuan2-13B(1):6次,正确;
- ChatGPT-3.5(0):4次,错误。
这个评测中,居然只有Baichuan2-13B是正确的,可怕。
6.生成SQL
生成SQL可以让我们通过语义理解来完成对本地数据库的查询,获取我们需要的数据,而不是通过程序员手动写SQL,或者只能按已经固化的SQL来进行某些变量(比如时间、实体等)的选择。
Prompt:
已知有两个mysql表,一个是代表销售人员的表:Persons,另一个是代表订单的表:Orders。具体的表定义如下: 表Persons: CREATE TABLE Persons (PersonID int, LastName varchar(255), FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (PersonID) ); 表Orders: CREATE TABLE Orders (O_Id int NOT NULL, OrderNo int NOT NULL, P_Id int, PRIMARY KEY (O_Id), FOREIGN KEY (P_Id) REFERENCES Persons(PersonID) ) 请帮我生成一个SQL语句,查询销售人员”Zhang san“的所有订单数据。
评测意义
在RAG应用中,根据语义生成SQL的能力是非常强大的,我们真的可以摆脱程序员预设的SQL来做事情。
评测结果
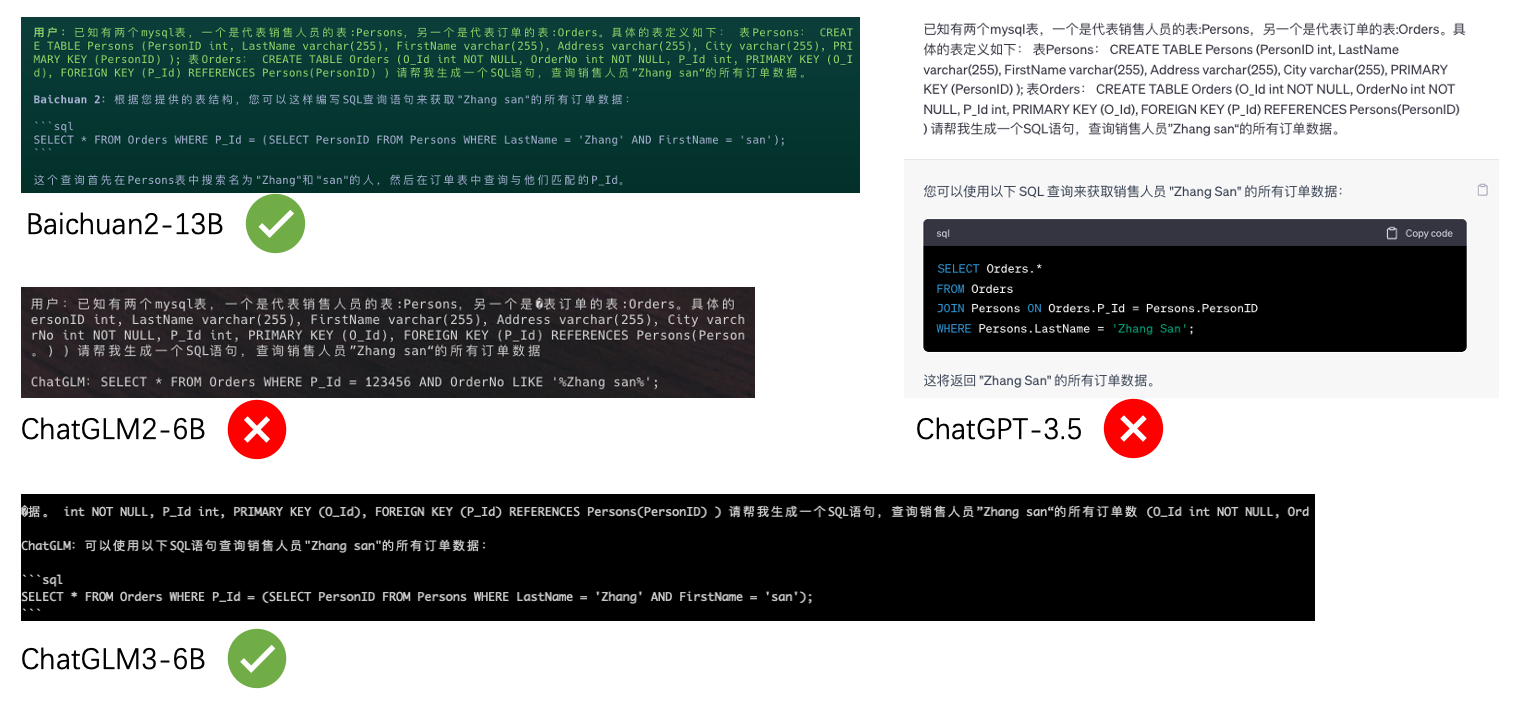
- ChatGLM2-6B(0):
P_Id = 123456是什么鬼,而且OrderNo LIKE '%Zhang san%'也是不知所云了; - ChatGLM3-6B(1):非常正确;
- Baichuan2-13B(1):非常正确;
- ChatGPT-3.5(0):ChatGPT-3.5用的语法我感觉是最好的,但是,它最后犯了一个错误,居然直接是
Persons.LastName = 'Zhang san',还是败在了对中文的理解上啊。
7.生成代码展示分析图表
这项任务我最初觉得是有一些挑战的。
Prompt:
已知浙江分公司2021年3月至7月(含)的自研产品销售数据依次为118万元、671万元、446万元、902万元和1011万元,请帮我用python的pyplot制作一个可查看趋势的柱状图表,注意,月份等标签请使用中文,并且,计量单位使用”万元“。
评测意义
在大模型的企业应用中,除了检索之外,我们很多时候也需要快速的得到一些数据分析指标,特别是一些趋势,用图表会更加直观,所以您直接说话,让应用(业务系统+数据库+大模型)立即给你直观的图表就变得很重要。一般我们会首先将语义转化为python代码,然后用matplotlib.pyplot等组件进行显示。当然,如果更复杂、更美观的分析图表,可以使用其他组件。
评测结果
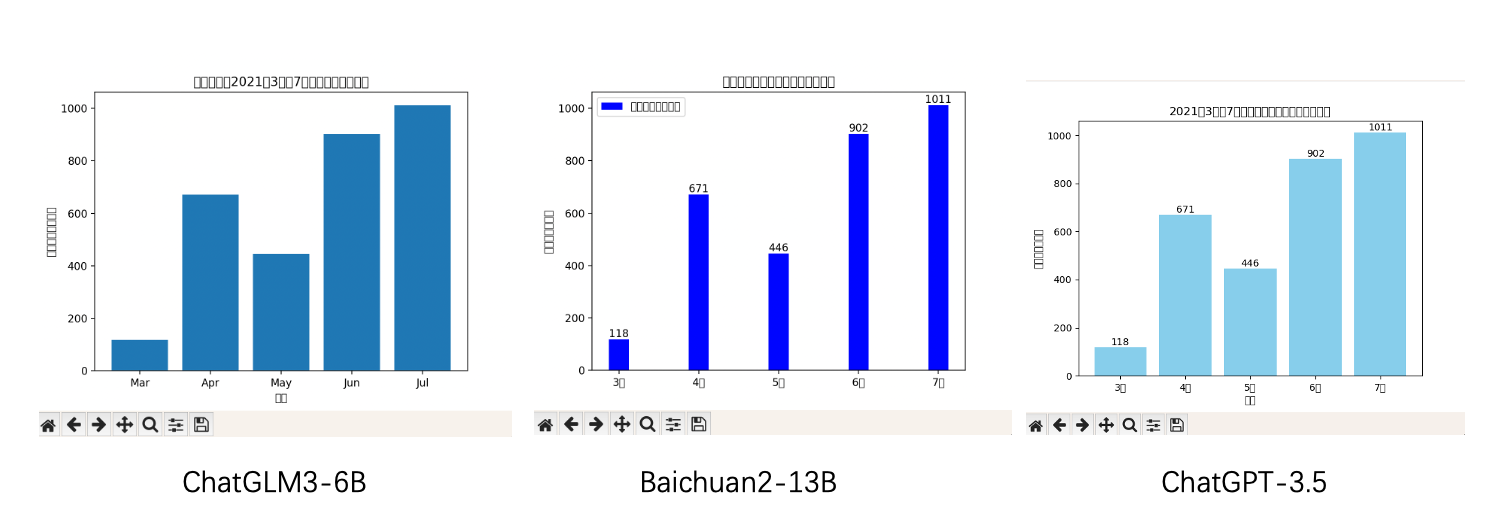
- ChatGLM2-6B(0):代码直接报错,无法运行;
- ChatGLM3-6B(0.8):基本满足,唯一的缺憾是缺少label,然后对中文的理解反而差了一些,特别是月份变成了May等;
- Baichuan2-13B(1):正确,而且还多了一个图例,很棒,中文乱码是因为我本地没装好中文环境;
- ChatGPT-3.5(1):正确,中文乱码是因为我本地没装好中文环境。
另外我贴一下各个模型给出的代码:
ChatGLM2-6B
1 | import matplotlib.pyplot as plt |
ChatGLM3-6B
1 | import pandas as pd |
Baichuan2-13B
1 | import matplotlib.pyplot as plt |
ChatGPT-3.5
1 | import matplotlib.pyplot as plt |
总结
我们先看总结一下上面的评分:
| 分项 | ChatGLM2-6B | ChatGLM3-6B | Baichuan2-13B | ChatGPT-3.5 |
|---|---|---|---|---|
| 实体提取 | 0 | 0.5 | 1 | 1 |
| 逻辑计算 | 1 | 0 | 0 | 0 |
| 英文翻译 | 0.5 | 0.8 | 1 | 1 |
| 归纳润色 | 0 | 1 | 0.6 | 1 |
| 统计次数 | 0 | 0 | 1 | 0 |
| 生成SQL | 0 | 1 | 1 | 0 |
| 生成图表 | 0 | 0.8 | 1 | 1 |
| 总计 | 1.5 | 4.1 | 5.6 | 4 |
这个结果,惊不惊喜意不意外!Baichuan2-13B和ChatGLM2-6B居然都超过了ChatGPT-3.5。
当然,这只是我针对目前在RAG应用上所做的一些具体能力的测试,如果真的要全面测试,我相信ChatGPT-3.5依然会遥遥领先。而且ChatGPT-3.5对于中文的一些细节方面理解偏差,是主要的失分原因,不然它应该是得到最高的6分的。
另外声明一点,我不是为百川打广告,因为本人不认识任何百川的人员,但目前确实在试用百川的大模型,效果不错。
ChatGLM3-6B这次的能力让我感到惊艳,毕竟和百川13B在参数体量上相差两倍多,但是能力上比较接近,在RAG中非常重要的归纳和SQL生成两项中都非常出色。而且,最关键的事ChatGLM3-6B可以在RTX 3090上部署,这是非常涨粉的优势!
以上三个本地模型都没有经过微调,我相信大家可以在ChatGLM3-6B和Baichuan2-13B中选定其中一款,然后进行微调,去匹配自己的RAG应用。
最后,什么是行业大模型?难道装进去行业知识多就是这个行业的大模型吗?RAG就是来解决行业知识问题的。所以,在行业里面应用,我更倾向于专项大模型,比如金融行业,就需要更强的逻辑计算、SQL和图表生成能力;而文博行业,更倾向的润色、归纳和统计次数等能力。所以,我认为可以有专项大模型,只有行业应用,没有行业大模型。

