本文主要内容:
- 近期关于RAG的一些行业交流
- RAG过度依赖ChatGPT好吗?
- RAG存在的一些问题
- 5个改善RAG性能的方法
近期行业交流的收获
近两周我们也在做一些RAG方面接地气的探索,所谓接地气,就是不仅仅研究产品技术,还包括和一些行业人士交流RAG在他们的业务场景中的需求。包括与金融、法律、高校、生产型工厂、贸易公司、电商、餐饮、知识产权和文旅等行业的人士交流,后续还安排了和政务、医疗、通信、能源、教育(非义务教育)和交通等行业的人士交流。说实在的,现在大家需要的基本都是Chat——快速根据已有文档,建立知识对话系统。但是随着交流的深入,我们和行业专家也发现了一些有意思的应用,绕开了问答系统,而且,这些系统往往更加适配行业客户的需要。
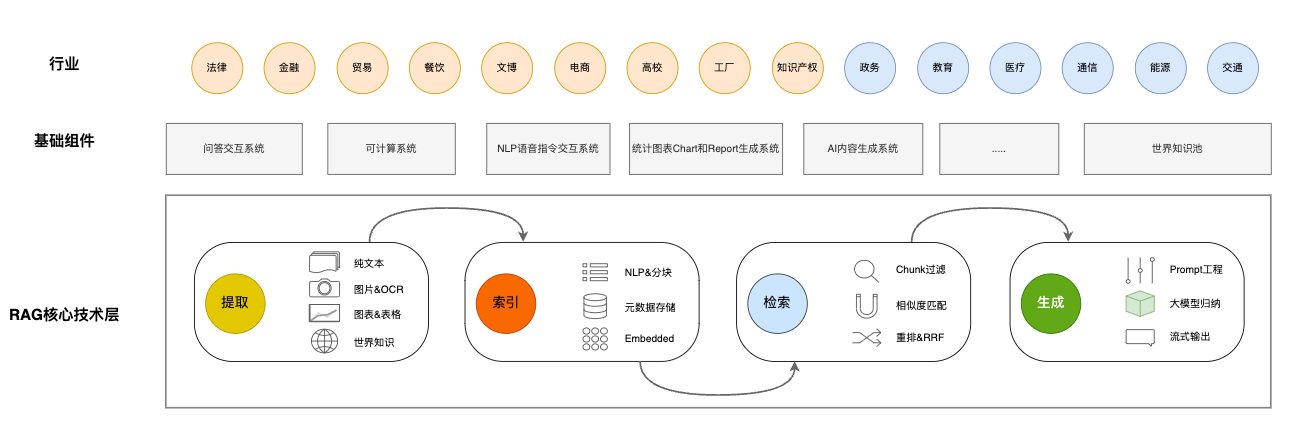
增加行业交流,是做产品PMF中的一个基础工作,使我们要知可以道技术能带来什么产品,而产品能为使用者带去什么价值。后续我们会继续交流,但是会把重心锁定在其中的两三个行业,做好真正有价值的产品。
通过近期的交流,也发现了一些问题,和大家分享一下。
RAG过度依赖ChatGPT好吗?
假设我们有一个可以无限输入tokens长度的LLM,输入字符串的长度对生成式LLM的精度没有影响。除此之外,它的行为与所有其他流行的大语言模型完全相同。我们称这个模型为完美LLM。我们认为它是完美的,不是因为它有出色的性能,而是因为它有理想的无限输入tokens长度,这在今天是不可能的。无限制的输入tokens长度确实是一个吸引人的特性。事实上,像ClaudeAI就允许输入的tokens长度为100万!但是,100万tokens够了吗?因为它只相当于4-5MB,仍然比实际业务中的大量文档要小得多。
现在的问题是:当你拥有如此完美的LLM时,你还会考虑RAG架构吗?具有无限输入长度的完美LLM减少了构建复杂RAG的必要性。然而,可能是的,您仍然需要考虑RAG体系结构。RAG架构不仅克服了LLM输入长度的限制,而且降低了LLM调用的成本,提高了处理速度。生成式大语言模型必须按顺序处理内容:输入越长,速度越慢。
关于调用成本我想多说一句,传统的应用程序,随着并发量增加,其实边际成本是在下降的。当然它也有一个临界点,比如1千并发和1万并发需要的硬件资源会急剧上升。但是总体上来说,边际成本还是会随着并发量增加而下降。但是,这种情况目前在GPU算力主导的LLM身上没有发生,现在基本上还是存在着并发越高成本也越高的情况。也许后面会有所改善,但是目前我还没有看到这个迹象,如果你有看到不同的信息,也可以分享一下。
但这里我想提一个相反的意见!
我们可以看到有很多关于如何构建RAG应用程序的示例代码和开源框架(如LlamaIndex和Langchain),目前它们产出一些技术和代码案例,使用的托底LLM基本上都是OpenAI的ChatGPT。我们碰的一些已经在做RAG应用的企业,也是无一例外的在试用OpenAI。就像上面说的,这本身是正确的逻辑,因为先用目前的上限做测试,至少我们”未来可期“——等国产大模型慢慢追上来。但不得不说,ChatGPT虽然还不完美,但已经很强大了。看了这些案例之后,我们也能发现完全基于ChatGPT好像有点背离我们构建RAG的初衷,也存在一些风险:
- 违背设计初衷:RAG的设计初衷是减轻LLM的各类问题,比如前面说到的减少幻觉、减少费用,增加实时性。但重度依赖ChatGPT反而把RAG做成了一个大模型的客户端,有点违背帮LLM分担压力的初衷;
- 国内使用风险:在国内使用ChatGPT属于是两头堵的状况,OpenAI对中国大陆用户是明确禁用的,国家对于非可控信源也是有严格的使用说明的。如果你只是自己搭建在家里或者公司内容研究用,那可能风险相对较小。但是如果要基于LLM和RAG技术对外提供经营服务,那基本上你还是需要退回到使用国内经过网信办审核的大模型。
而像我们这样使用国产大模型,或使用自己本地部署的开源大模型,确实在整体效果上和OpenAI是存在一些差距的,有时候事倍功半,想想还是挺气人的。我们需要为大模型本身的能力差距做很多”胶水组件“,其实就是很多中间件,比如表格处理,使用OpenAI的话我们可以直接使用开源的PandasAI(我之前也介绍过这个库),它会产生一些代码执行语句,给到ChatGPT,就能生产很好的结果。但是在国产大模型里面,没有这么强的程序执行能力,我们就需要做一些表格存储、处理和计算的额外功能,像这样的例子还有很多。
但是这样做的好处是我们对RAG整个体系中各个环节都越来越清楚,可以快速定位到问题,知道怎么做一个胶水组件去解决问题。假以时日,国产大模型追上了GPT-3.5的水平了,那精通RAG内部各个细节的你,做出来的应用应该也会比别人的更优秀。
RAG性能预期
我们直接将Prompt输入到LLM中,LLM会直接消化输入文本中的所有信息,最终结果的准确性仅取决于生成式LLM的性能。
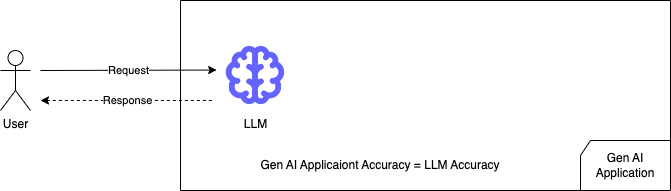
对于普通的RAG应用程序,还有两个影响最终性能的组件:语义搜索方法和RAG实现。
RAG架构使用Embedding模型来生成真实知识和查询的向量。然后使用向量相似度匹配算法来检索最相关的内容。Embedding模型从文本中提取表征向量的能力是非常关键的。除了Embedding模型之外,在RAG开发中还有很多实现细节,这些细节也会严重影响最终的结果。也就是说,RAG输出的准确率等于LLM的准确率 x 语义搜索的准确率 x RAG信息保存率。
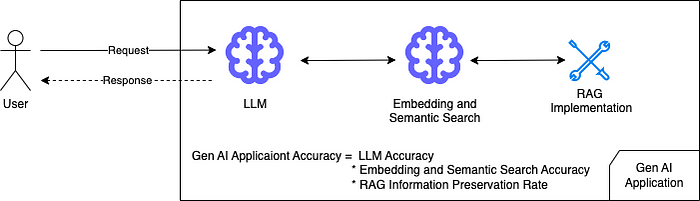
如果这三个因素都小于100%,RAG应用程序的预期精度会低于直接使用LLM模型的精度(我在之前的文章中已经提到过)。如果RAG的设计不合理,其性能会显著下降。当我们开始考虑我们的RAG应用程序设计时,这是要记住的第一个概念。否则,意想不到的结果会让我们非常失望。
信息保存
很容易理解,LLM模型和语义搜索都不能达到100%的准确率。让我解释一下什么是RAG信息保存率。
我们提供给应用程序的文本语料库可以包含非常丰富的信息。让我们来看看语料库中的内容以及如何将信息输入LLM:
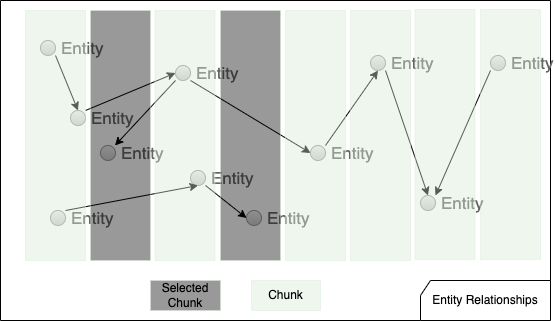
上图描述了文本语料库中的实体关系。实体分布在整个语料库中,引用关系也无处不在。在分块之后,实体在每个筒仓中受到约束,并且chunk之间的关系都被切断。在检索短语中,只有top-k的chunk会有机会被检索召回,然后发送给LLM处理输出。这意味着只有一部分实体和关系可以转发到LLM。如果需要广泛的关系知识来响应查询,LLM将会遇到麻烦。
除了实体关系之外,分块操作还会对输入中的其他各种类型的信息产生影响:
- 上下文信息:
在大多数情况下,文本具有多层上下文信息。例如,《统计学习的要素》这本书有18章,每一章都专注于一个主题。每章有副标题和第二层副标题等。人们习惯于在语境中理解文章。分块策略使内容与上下文脱节。
- 位置信息:
文本的权重取决于它们在文档中的位置。文档开头和结尾的文字比中间的文字更重要。它们出现在一章的开头或结尾比出现在一章的中间更重要。
- 连续的信息:
自然文本也经常使用显性和隐性语言连接来连接主题。例如,一个故事可能以“in the beginning”开头,然后以“then”、“therefore”、“after that”继续,直到以“finally”、“finally”等结尾。使用分块策略,这种连接不再是完整的。不仅谜题不见了,而且排序顺序也被打乱了。
- 描述信息:
这指的是描述单个主题的信息。使用分块,可能无法保证描述性信息集中在一起。想象一下你正在打电话,突然电话线被切断了。这取决于你的电话有多重要,当它发生时,影响范围从微不足道到非常令人沮丧。
RAG的优势和劣势
如果我们把只使用分块和向量相似度搜索的抹布称为“香草抹布”,我们可以看到它们只能处理几种类型的查询,因为它们丢失了我们之前谈到的一些输入信息:
- 擅长小范围的描述性问题回答。例如,哪个主体具有某些特征?
- 不擅长关系推理,即寻找从实体A到实体B的路径或识别实体集团。
- 不擅长时间跨度很长的总结。例如,“列出所有哈利波特的战斗”或“哈利波特有多少次战斗?”
RAG应用程序在这类任务上的表现很差,因为只有少数chunk可以输入到LLM中,而且这些chunk是分散的。LLM会缺少很多辅助信息,比如元数据和世界知识。当然,元数据和世界知识都是可以去增加的,这也是我们现在的工作之一。
了解RAG能做什么和不能做什么,可以让我们为RAG寻找最适合的领域,避免强行进入错误的地方,比如千万别让RAG去写诗,它的算数能力也很差,我们现在是自己做了外挂程序(胶水组件)来完成这部分工作的。
如何改进RAG应用程序
讨论了RAG应用程序的局限性之后,让我们看看如何改进它的性能。
好好优化你喂给LLM的内容
通常,在处理输入查询时,我们只是接受用户输入的任何内容。这并不理想,不仅因为存在prompt泄漏和prompt注入等安全风险,还因为性能也可能令人失望。
根据研究人员的说法,大语言模型对prompt中的拼写错误和措辞差异很敏感,为了确保大语言模型以其最佳性能运行,请考虑纠正所有错字并将输入改写为大语言模型更容易理解的形式。
保持Embedding模型在同一层面上
在大多数情况下,用户发送简短的查询,比如“告诉我更多关于徐悲鸿的信息”。然后,将查询转换为Embedding向量,该向量捕获该特定查询的本质。使用直接查询进行语义搜索可能具有挑战性,因为:
- 用户查询很短,以问题的形式出现。它们包含有限的语义特征。虽然文档Embeddings以各种形式的语句的形式很长,但文档Embeddings在其向量中具有丰富得多的信息。
- 由于用户查询中的语义特征有限,语义搜索功能热衷于过度解释查询中的琐碎细节,致使文档Embedding有很大的噪声。分块使情况变得更糟,因为许多关系、上下文和顺序链接都是错乱了。
- Embedding模型和LLM属于不同的家族。他们接受的训练不同,行为也不同(比如Baichuan2-13B和ChatGLM2-6B在功能和行为上就差异很大,一个马上会给出简洁明确的答案,另一个则更像诗人,可能答案也是对的,但是用词浮躁对于用户干扰很大)。Embedding模型不具有与生成大语言模型相同水平的推理能力。他们甚至不像生成大语言模型那样重视语言细节。直接使用用户输入进行查询,在最坏的情况下,会使语义搜索功能降级为关键字搜索。
- 由于Embedding和LLM是两种不同的模型,在整个过程中扮演着不同的角色,它们并不在同一层面上。这两个模型根据他们自己对需求的理解来完成他们的工作,但他们彼此不交谈。检索到的信息可能不是LLM产生最佳结果所需的信息。这两个模型没有办法相互对齐。
为了避免这个问题,您可能希望首先使用LLM来增加用户查询。考虑下面的例子:
原始用户查询:跟我说说托尼·艾伯特。
在原始查询的基础上使用Bard重新表述的增强查询:
艾伯特的政治背景是什么?
托尼·阿博特最显著的成就是什么?
艾伯特的政治观点是什么?
托尼·阿博特的个人兴趣是什么?
托尼·阿博特卷入了哪些争议?
你能看到信息丰富程度的提高吗?增强查询提供了更多的特性,从而产生了更好的检索结果。此外,通过发送增强查询,LLM有机会告诉Embedding模型它需要什么,Embedding模型可以更好地为LLM提供高质量的块。这就是两种模式协同工作的方式。
分块策略
块(chunk)大小是我们可以为RAG应用程序调优的为数不多的超级参数之一。为了获得更好的结果,建议使用较小的块大小。微软就有这样的分析:
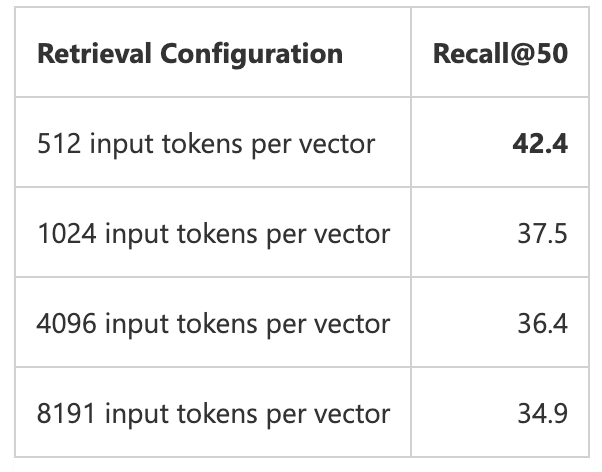
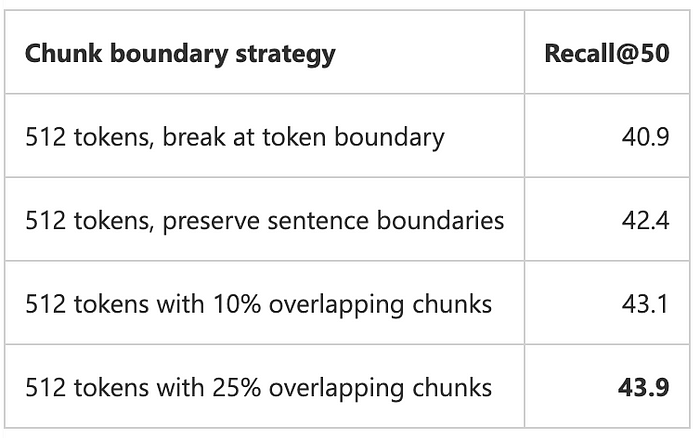
在分割文本时,我们也可以选择不同的分割策略。最简单的方法是在单词的中间切断。我们也可以尝试不同的策略,比如在一个句子或段落的中间切断。为了得到更好的结果,我们可以重叠相邻的块。来自微软分析的分块策略比较:
Embedding模型的语义提取能力有限。它们在呈现多主题、多回合语料库时不如简单语料库有效。这就是为什么RAG更喜欢较短的块。那么块的大小是最好的呢?在微软的分析中,最小的块大小是512个tokens。一些企业级RAG应用程序中的块大小只有100个tokens。最小的块大小是否总是能获得更好的结果?
如前所述,分块策略会将文本语料库分解成小块,导致信息丢失。数据块越小,丢失的信息就越多。所以,有一个最优的块大小。过小的分块可能不太理想。然而,寻找最优块大小就像超参数调优一样。你必须用你的数据做实验。
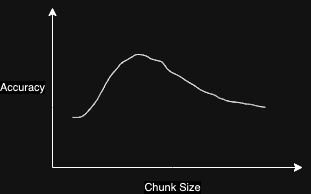
减少信息损失
微软的分析发现,大量重叠的分块可以提高准确性。为什么它有帮助,我们能否找到更好的方法来提高RAG性能?
重叠背后的原因是重叠可以帮助将相邻的块链接在一起,并为块提供更好的上下文信息。然而,即使是非常激进的25%重叠也只能将准确率提高1.5%,从42.4%提高到43.9%。这意味着这不是优化RAG性能的最有效方法。我们不能通过更多的重叠来进一步提高RAG的性能。记住,重叠分块甚至不能用于小块。
但是重叠有时候在处理代词的时候很有效,比如上一个chunk说到”徐悲鸿非常擅长画马“,然后下一句说”他画马的主要技法是xxxxx“,这时候如果缺少了重叠,就会让这个代词变成”无主之地“。
当然,目前还有一种非常流行的做法是引入知识图谱,包括NebulaGraph提出的Graph RAG。
在知识图谱的帮助下,RAG可以将这些关系存储在图数据库中。块之间的连接可以完全保留。如果关系推理对您的项目至关重要,那么这是一个非常可观的解决方案。
然而,带有知识图谱的RAG并不是没有挑战的。从非结构化文本中建立知识图谱是非常重要的。有很多关于从文本输入中提取实体-关系三元组的实验。当你需要将解决方案产品化时,情况就不同了。自动提取的实体和关系可能包含大量的噪声,忽略了太多的真实信息。你们必须非常仔细地检查产品的质量。即使在填充知识图谱之后,所支持的查询也与图数据库设计紧密耦合。
支持向量搜索的关系数据库不像带有Knowledge Graph的RAG那么花哨,它也是工具箱中非常重要的组件。像pgvector这样的数据库允许您将复杂的信息存储为列,同时保留语义搜索功能。它比知识图谱更容易与其他企业系统集成,也更灵活。
这些都是值得考虑的有效选择。唯一需要注意的是,许多支持矢量的图形数据库、搜索引擎和关系数据库并没有完全优化为向量数据库。它们在处理大规模向量索引时的速度可能不理想,特别是当它们必须经常更新索引时。可参考之前的一篇文章《》
看看主要原因是什么
有时,我们发现RAG不能很好地回答我们的问题。我们应该考虑以下问题,而不是盲目的捣腾一通:
- LLM是否已经获得了它需要的所有信息?
- 这些信息是否对LLM友好的方式喂进去的?
让我们考虑下面的例子:
我们正在SharePoint网站上构建一个RAG应用程序。其中一个网页是关于所有的项目和他们的团队成员,包括所有人的个人资料。我们需要确保RAG准确地回答项目与团队成员的问题:然而,最初的结果非常令人失望。
初步调查显示,SharePoint网站没有以结构化的方式组织内容,从而使信息的从属关系易于理解。删除所有HTML标签后,网页内容如下所示:
1 | project A |
如果说人类很难区分谁是谁,那么RAG也很难区分。为了更好地组织信息,我们使用Python代码根据HTML属性将信息聚合在一起,将每个项目和团队成员的姓名分离到一个文本文件中,并将每个人的信息放入自己的文件中:
1 | file project_A.txt: |
生成的文本文件很小,这似乎与RAG分块实践不一致。原因是合并后的文件避免了分裂的问题,完全消除了噪音。有了新生成的文件,RAG可以毫无问题地回答诸如“谁在做项目x?”以及“亚当·斯密的爱好是什么?”
然而,当我们把问题转过来:“亚当·斯密在做哪个项目?”我们看到亚当·斯密被列在项目成员名单中。我们不太确定为什么Embedding模型不能捕捉到它。为了帮助LLM完成工作,我们可以使信息脱颖而出。我们在这个人的文件中添加了一行,明确地说明了项目的参与情况:
1 | file person_A.txt: |
这一行使RAG应用程序能够100%准确地回答上述问题。
结束语
RAG作为一项新兴技术,正在快速发展。我发现逐项研究它的组成部分对我有很大帮助。通过研究细节,我可以更深入地了解这项技术的利弊,并对一项新想法是否可行有一个基本预判。有一些非常流行的框架可以帮助我们更快地开发RAG应用程序。我发现其中的一些执行理念非常鼓舞人心。但是,我不建议仅仅因为它们很容易上手就开始学习或开发基于这些库的RAG,很多时候如果你真的要扎根进去,还是可以考虑一下”古法酿造“,会有更多惊喜的收获。
如果您已经阅读了本文,那么您肯定同意RAG是一个复杂的体系结构,所谓入门简单精通极难。很多国外的文章以及流行的框架掩盖了所有的细节,这让人们认为这些细节并不重要。当我们在项目中遇到问题时,会发现很难找到出路,因为有太多的实现细节。而且对于国内的程序员来说,这个难度还会极大提高,因为我们在正式环境中很难对接OpenAI的ChatGPT,除非你只是把应用部署在自己家里或者公司自用。抛开ChatGPT这个”超级“大模型,替换成可以本地部署的开源大模型或者国产大模型,如果你要达到一样的效果,那就需要在中间件和应用层做很多胶水组件。
如果你刚刚接触RAG不够,我还是建议你先从基本知识开始研究,了解内部细节,再用那些主流框架的时候,你才会收放自如。
引用
0.Practical Considerations in RAG Application Design:https://pub.towardsai.net/practical-considerations-in-rag-application-design-b5d5f0b2d19b (本文很多内容来自该文章)
1.Prompt Robustness: How to Measure and How to Enhance:https://pub.towardsai.net/prompt-robustness-how-to-measure-and-how-to-enhance-644fb6493ec?source=post_page-----b5d5f0b2d19b--------------------------------
2.Azure Cognitive Search: Outperforming vector search with hybrid retrieval and ranking capabilities:https://techcommunity.microsoft.com/t5/azure-ai-services-blog/azure-cognitive-search-outperforming-vector-search-with-hybrid/ba-p/3929167?source=post_page-----b5d5f0b2d19b--------------------------------
3.What We Need to Know Before Adopting a Vector Database:https://medium.com/@kelvin.lu.au/what-we-need-to-know-before-adopting-a-vector-database-85e137570fbb?source=post_page-----b5d5f0b2d19b--------------------------------
4.Disadvantages of RAG:https://medium.com/@kelvin.lu.au/disadvantages-of-rag-5024692f2c53?source=post_page-----b5d5f0b2d19b--------------------------------
Update: 2024-01-26

我们的TorchV Bot产品目前已经开始试用了,详情可以点击:https://www.luxiangdong.com/2024/01/25/lanuch-1
目前只接受企业用户试用,需要您填写一些信息,必要信息如下:
邮箱: 用来接收地址和账号
如何称呼您:
所服务的公司:
您的职位:
当然,如果您可以告诉我们您的使用场景,我们将更加感激!
对了,可以发送到yuanwai@mengjia.net
另外,也可以直接加我微信(lxdhdgss)联系我。

