前面刚测试了Baichuan2-13B的本地化模型能力,对于我来说,归纳能力已经足够了。但是一旦深入RAG的应用,Baichuan2还是有一些弱势的,比如在表格的处理能力上,显得力不从心。让我们比较失望的是,目前国内一众模型里面,对这一块的处理能力都够呛,唯一可行的还是OpenAI的ChatGPT。
于是这两天也在空隙里面找可以本地化部署,对于RAG又比较友好的LLM,发现还真的有几个新的LLM出来了。
首先看到的是Mistral-7B,据说性能超过了Llama-13B。正当我准备好好研究一下的时候,又看到Wenqi Glantz老师在推Zephyr-7b-alpha,而且推荐理由里面有两点正是我想要的:
- 对RAG比较友好;
- 性能比Mistral-7B更强。
并且她还做了对比。
Zephyr介绍
下面我们来看看Zephyr-7b-alpha的介绍,以及它的性能如何!
Zephyr其实是一个大语言模型的系列名称,Zephyr-7B-alpha是该系列的第一款型号,它是基于Mistral-7B-v0.1微调而来的,使用直接偏好优化(DPO)对公开可用的合成数据集进行混合训练。我们发现,删除这些数据集的内置对齐提高了MT Bench上的性能,可以让模型更加出类拔萃。当然,这个模型因为是MIT的协议,所以是可以免费商用的,和其他很多可商用模型一样,也是申明仅用于教育和研究目的,意思就是在商用上出什么幺蛾子我不管的。
我在它的官方提供的测试地址上做了测试,首先它是支持中文的(答案当然是不准的):

然后呢,它对于表格类型的问答,处理能力应该说比较弱吧,甚至有点不听指令(机器觉醒?)

Wenqi Glantz使用了EDD(评估驱动开发)的视角来探索zephyr-7b-alpha,使用LlamaIndex构建的多文档RAG管道,并与OpenAI模型GPT-3.5进行了比较。
zephyr-7b-alpha是一种7b参数类似gpt的模型,从Mistralai/Mistral-7B-v0.1微调而来。根据HuggingFace MT Bench,一个评估机器翻译(MT)系统质量的基准套件,zephyr-7b-alpha优于Llama-2-70b-chat-hf和Mistral-7B-Instruct-v0.1,请看下面的比较表。

LlamaIndex一直对各种LLM做兼容性跟踪评测,执行了一个LLM兼容性跟踪,从中我们了解到zephyr-7b-alpha是迄今为止唯一一个在高级RAG任务上表现良好的开源7b模型。
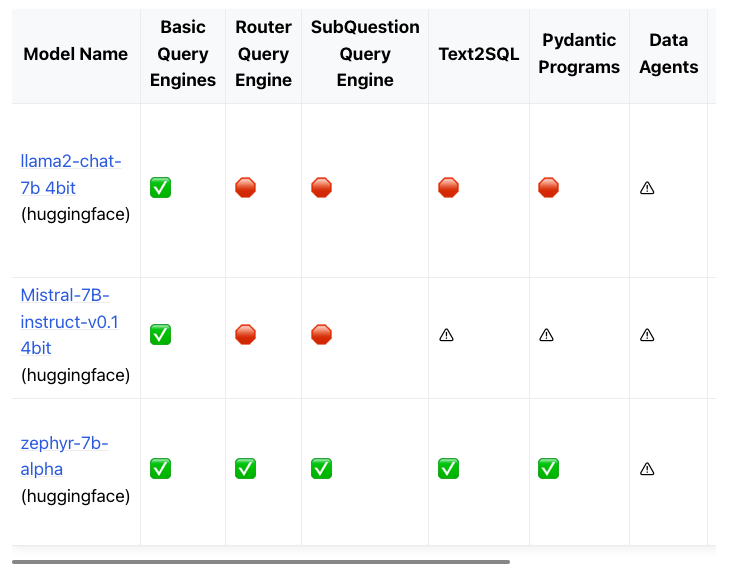
从上面的截图中可以看出,尽管zephyr-7b-alpha在大多数类别中都优于其他两个7b模型,但作为数据agent,它仍然有其局限性。让我们在下一节中继续进行评估POC时记下它。
BAAI/bge-base-en-v1.5
BAAI/big-base-en-v1.5是由北京人工智能研究院(BAAI)开发的文本Embedding模型。它是一个在大量文本和代码数据集上训练的大型语言模型。它可以为各种NLP任务生成文本Embeddings,例如检索、分类、聚类和语义搜索。它是HuggingFace的MTEB(海量文本Embedding基准)排行榜上目前排名第二的Embedding模型,仅次于其更强大的兄弟big-large-en-v1.5。
我们将使用BAAI/big-base-en-v1.5作为评估POC的Embedding模型。
POC评估
我们用两种实现策略评估了一个多文档RAG管道的能力:
- 递归检索器+文档代理
- 元数据替换+节点句子窗口
正如上面关于zephyr-7b-alpha的部分所指出的,它对数据代理有限制。在本文中,我们将忽略递归检索器+文档代理的实现策略,而将重点放在相同的多文档RAG管道的元数据替换+节点句子窗口的策略上。我们将比较以下两种实现:
gpt-3.5-turbo+BAAI/bge-base-en-v1.5zephyr-7b-alpha+BAAI/bge-base-en-v1.5
gpt-3.5-turbo + BAAI/bge-base-en-v1.5
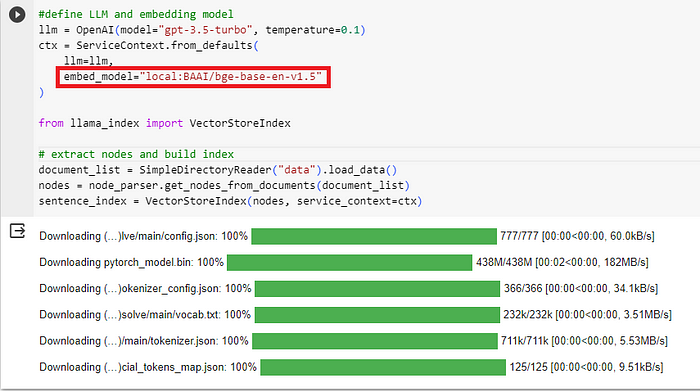
现在,让我们使用Embedding模型——BAAI/big-base-en-v1.5 ,请参阅下面的代码片段。注意,在构造ServiceContext时,embed_model现在指向local:BAAI/big-base-en-v1.5。
1 | #define LLM and embedding model |
这将触发将local:BAAI/big-base-en-v1.5下载到我们在Colab的环境中(你也可以用本地环境)。
zephyr-7b-alpha + BAAI/bge-base-en-v1.5
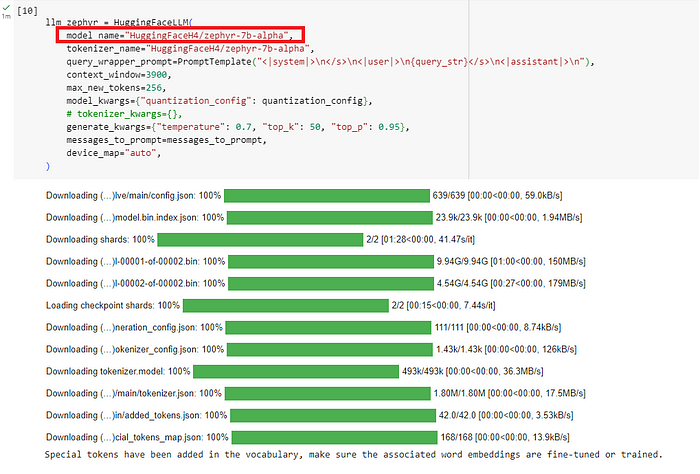
现在,让我们试试zephyr-7b-alpha + BAAI/big-base-en-v1.5的组合。请参阅下面的代码片段。注意,在构建ServiceContext时,我将embed_model更改为local:BAAI/big-base-en-v1.5。
1 | import torch |
如果您在免费版Colab笔记本中运行上述代码,则在下载zephyr-7b-alpha 时可能会遇到错误。我不得不支付9.99美元的月费升级到专业版,并将硬件加速器的运行时类型更改为T4 GPU,并打开了High-RAM。这个小小的投资是非常值得的。
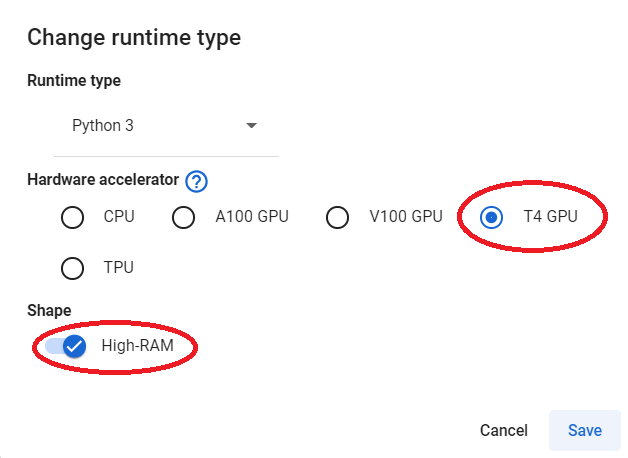
通过硬件调整,我们现在可以成功下载zephyr-7b-alpha。
评测
让我们使用LlamaIndex的响应评估模块添加剩余的评估代码。
综上所述,使用LlamaIndex的响应评估模块的高级步骤包括:
- 使用
DatasetGenerator自动生成评估问题。 - 定义
faithfulness和relevancy的评估者。 - 使用
BatchEvalRunner来异步运行响应的评估。 - 比较评价结果。
1 | from llama_index.evaluation import FaithfulnessEvaluator, RelevancyEvaluator |
让我们看看gpt-3.5-turbo和zephyr-7b-alpha的结果,两个测试的Embedding模型都是local:BAAI/big-base-en-v1.5。
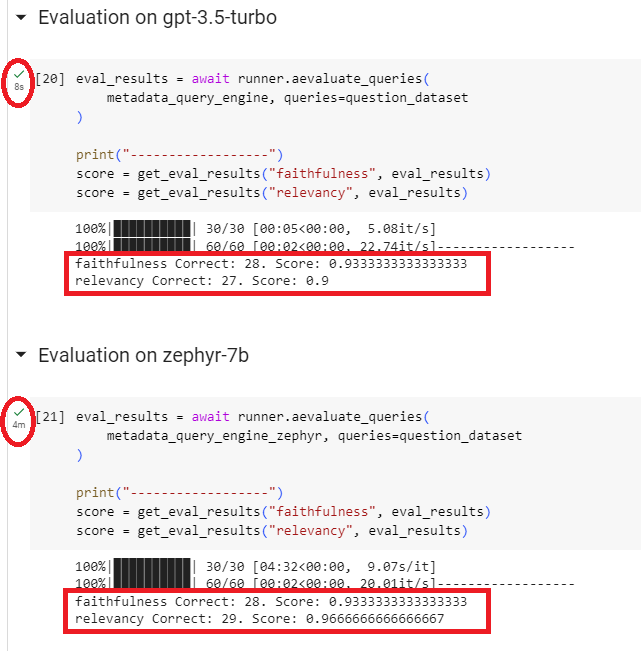
评价
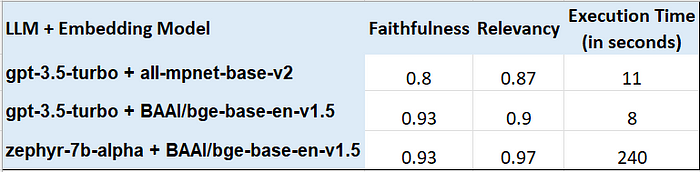
让我们收集这两个评估的结果并把它们放在一起(忽略all-mpent-base-v2)。
我们将faithfulness和relevancy的数字映射到一个图表中,得到以下结果。
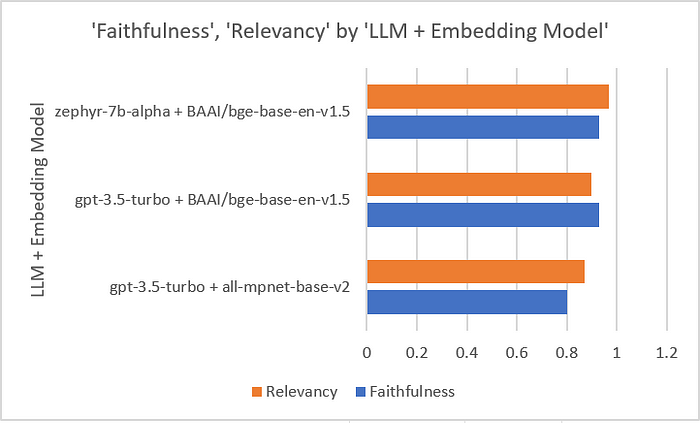
我们可以看到:
- 与
gpt-3.5-turbo+BAAI/big-base-en-v1.5相比,zephyr-7b-alpha+BAAI/big-base-en-v1.5的得分相同,faithfulness为0.93比0.93,relevancy为0.97比0.9。 - 评估执行时间在两个选项之间差异很大,
zephyr-7b-alpha+BAAI/big-base-en-v1.5需要4分钟才能完成,而其他选项大约需要10秒。哎呀!这当然不理想。
zephyr-7b-alpha在评估的faithfulness和relevancy类别中确实看起来很有希望。然而,值得一提的是,HuggingFace:)对其局限性提出了几个关键点
Zephyr-7B-α没有通过RLHF等技术与人类偏好保持一致,也没有使用ChatGPT等循环过滤响应,因此模型可能产生有问题的输出(特别是在提示这样做的时候)。它也不知道语料库的大小和组成是用来训练基础模型的(Mistral-7B-v0.1),但是它很可能包括了网络数据和技术来源如书籍和代码的混合。
同样重要的是要记住,从评估结果中得出的结论只适用于我们处理的特定用例。zephyr-7b-alpha + BAAI/big-base-en-v1.5在我们的POC RAG管道中略优于GPT-3.5,但这并不意味着它在您的用例中会优于GPT-3.5。本文旨在传达评估驱动开发的重要性,甚至在选择大语言模型和Embedding模型时也是如此。使用EDD作为瑞士军刀来剖析和评估您的用例,以找到最合适的工具和实现策略,使您的RAG管道成功。
总结
在本文中,我们通过EDD(评估驱动开发)的视角探索了zephyr-7b-alpha,使用rag相关技术:gpx-3.5-turbo + BAAI/big-base-en-v1.5和zephyr-7b-alpha + BAAI/big-base-en-v1.5。我们使用LlamaIndex的响应评估模块进行了评估,并比较了所有三种情况的结果。
我们可以得出结论,对于我们的POC RAG管道,zephyr-7b-alpha + BAAI/big-base-en-v1.5的组合略微优于OpenAI的ggt -3.5 + BAAI/big-base-en-v1.5。这对开源社区来说确实是一个鼓舞人心的消息!
引用
- Wenqi Glantz的评测原文:https://levelup.gitconnected.com/exploring-zephyr-7b-alpha-through-the-lens-of-evaluation-driven-development-faf69e9d9ec7
- HuggingFaceH4/zephyr-7b-alpha:https://huggingface.co/HuggingFaceH4/zephyr-7b-alpha
- BAAI/bge-base-en-v1.5:https://huggingface.co/BAAI/bge-base-en-v1.5
- Colab notebook for zephyr-7b-alpha-feature-test:https://colab.research.google.com/drive/16Ygf2IyGNkb725ZqtRmFQjwWBuzFX_kl?usp=sharing
- Open Source LLMs:https://docs.llamaindex.ai/en/stable/core_modules/model_modules/llms/root.html#open-source-llms
- LlamaIndex Response Evaluation Module:https://docs.llamaindex.ai/en/stable/core_modules/supporting_modules/evaluation/modules.html#response-evaluation

