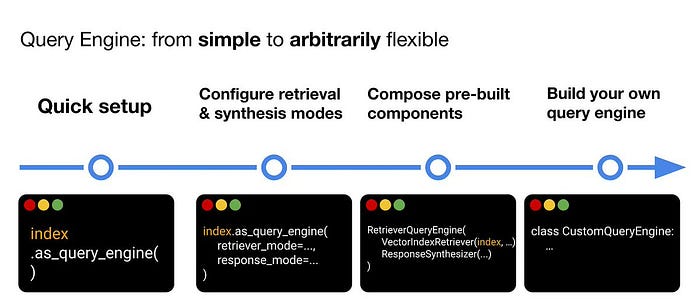
LlamaIndex(也称为GPT Index)是一个用户友好的界面,它将您的外部数据连接到大型语言模型(Large Language Models, llm)。它提供了一系列工具来简化流程,包括可以与各种现有数据源和格式(如api、pdf、文档和SQL)集成的数据连接器。此外,LlamaIndex为结构化和非结构化数据提供索引,可以毫不费力地与大语言模型一起使用。
from llama_index import GPTKeywordTableIndex, SimpleDirectoryReader from IPython.display import Markdown, display from langchain.chat_models import ChatOpenAI
## by default, LlamaIndex uses text-davinci-003 to synthesise response # and text-davinci-002 for embedding, we can change to # gpt-3.5-turbo for Chat model index = GPTListIndex.from_documents(documents)
query_engine = index.as_query_engine() response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
## Check the logs to see the different between th ## if you wish to not build the index during the index construction # then need to add retriever_mode=embedding to query engine # query with embed_model specified query_engine = new_index.as_query_engine( retriever_mode="embedding", verbose=True ) response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
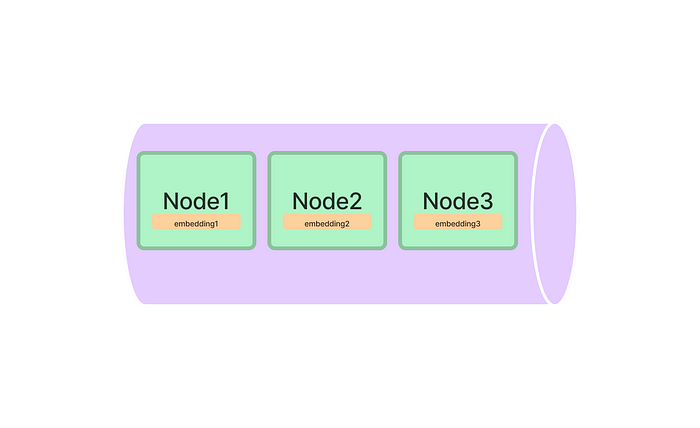
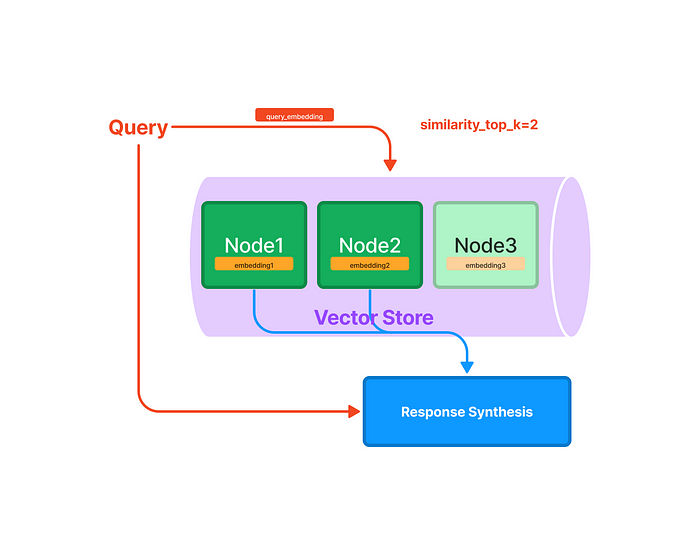
index = GPTVectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine() response = query_engine.query("What did the author do growing up?") response
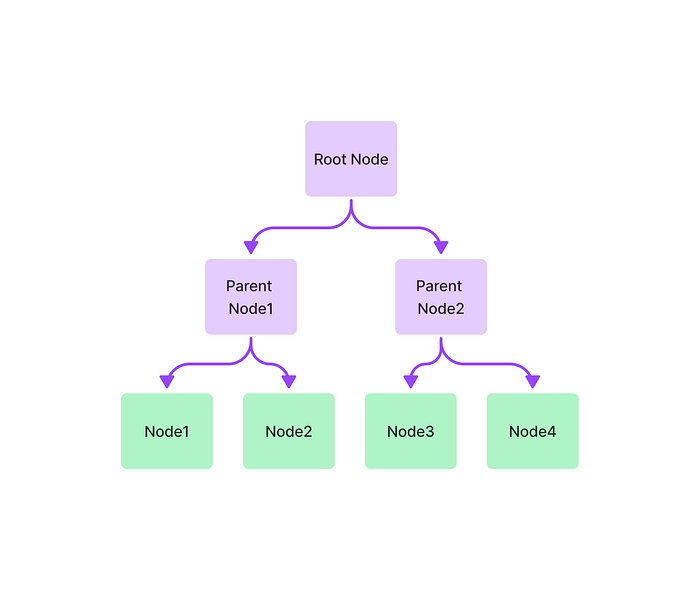
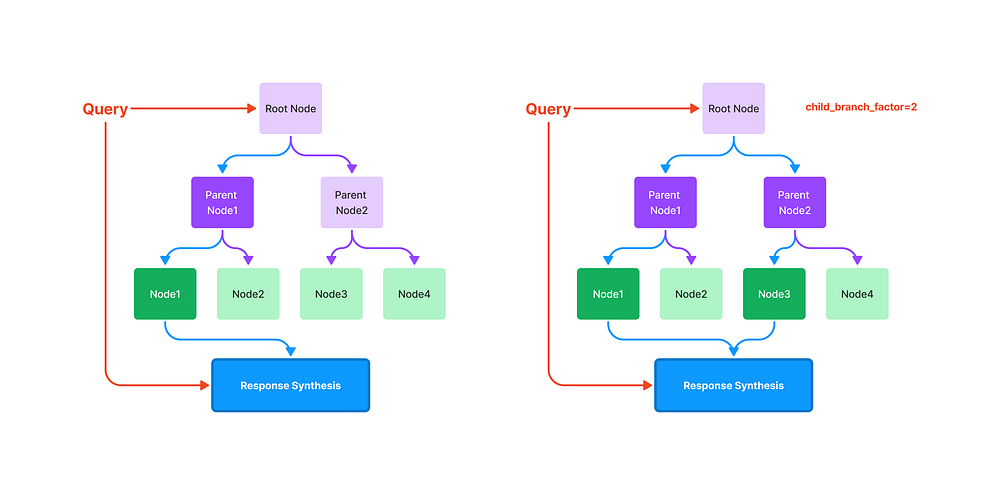
new_index = GPTTreeIndex.from_documents(documents) response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
## if you want to have more content from the answer, # you can add the parameters child_branch_factor # let's try using branching factor 2 query_engine = new_index.as_query_engine( child_branch_factor=2 ) response = query_engine.query("What is net operating income?") display(Markdown(f"<b>{response}</b>"))
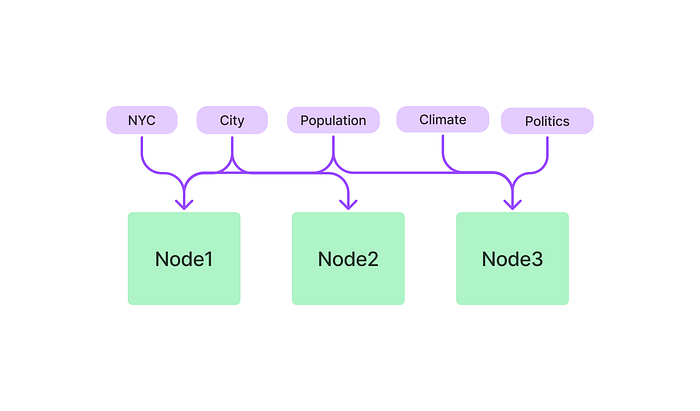
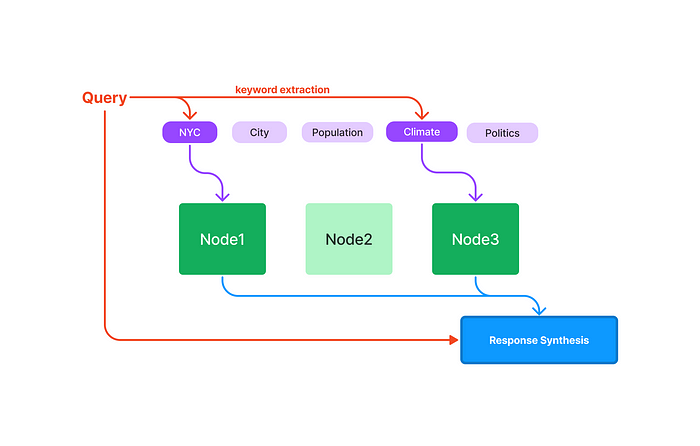
from llama_index import GPTKeywordTableIndex index = GPTKeywordTableIndex.from_documents(documents) query_engine = index.as_query_engine() response = query_engine.query("What is net operating income?")
for year in years: year_docs = loader.load_data(f'../notebooks/documents/Apple-Financial-Report-{year}.pdf', split_documents=False) for d in year_docs: d.extra_info = {"quarter": year.split("-")[0], "year": year.split("-")[1], "q":year.split("-")[0]} doc_set[year] = year_docs all_docs.extend(year_docs)
为每个季度创建矢量指数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## setting up vector indicies for each year #--- # initialize simple vector indices + global vector index # this will use OpenAI embedding as default with text-davinci-002 service_context = ServiceContext.from_defaults(chunk_size_limit=512) index_set = {} for year in years: storage_context = StorageContext.from_defaults() cur_index = GPTVectorStoreIndex.from_documents( documents=doc_set[year], service_context=service_context, storage_context=storage_context ) index_set[year] = cur_index # store index in the local env, so you don't need to do it over again storage_context.persist(f'./storage_index/apple-10k/{year}')
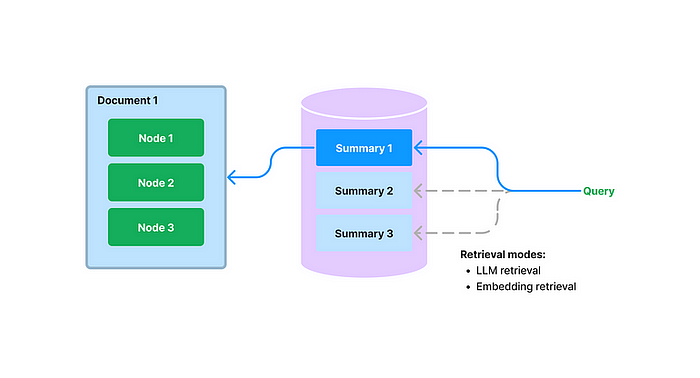
从树索引生成摘要。如前所述,Tree Index对于总结文档集合很有用。
1 2
# describe summary for each index to help traversal of composed graph index_summary = [index_set[year].as_query_engine().query("Summary this document in 100 words").response for year in years]
### Composing a Graph to Synthesize Answers from llama_index.indices.composability import ComposableGraph
from langchain.chat_models import ChatOpenAI from llama_index import LLMPredictor
# define an LLMPredictor set number of output tokens llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, max_tokens=512, model_name='gpt-3.5-turbo')) service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor) storage_context = StorageContext.from_defaults()\
## define a list index over the vector indicies ## allow us to synthesize information across each index graph = ComposableGraph.from_indices( GPTListIndex, [index_set[y] for y in years], index_summaries=index_summary, service_context=service_context, storage_context=storage_context )
root_id = graph.root_id
#save to disk storage_context.persist(f'./storage_index/apple-10k/root')
## querying graph custom_query_engines = { index_set[year].index_id: index_set[year].as_query_engine() for year in years }
# NOTE: the table_name specified here is the table that you # want to extract into from unstructured documents. index = GPTSQLStructStoreIndex.from_documents( wiki_docs, sql_database=sql_database, table_name="city_stats", service_context=service_context )
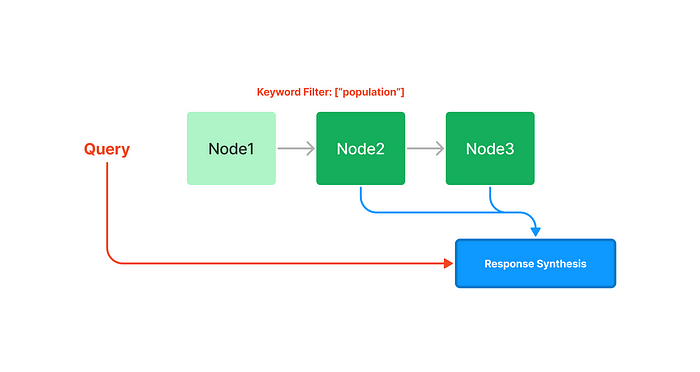
# view current table to verify the answer later stmt = select( city_stats_table.c["city_name", "population", "country"] ).select_from(city_stats_table)
with engine.connect() as connection: results = connection.execute(stmt).fetchall() print(results)
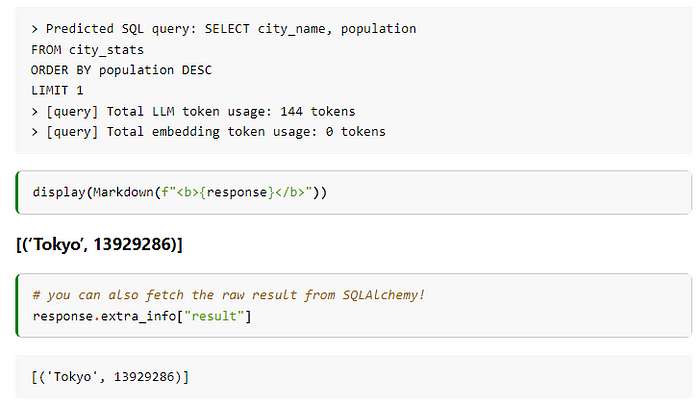
query_engine = index.as_query_engine( query_mode="nl" ) response = query_engine.query("Which city has the highest population?")
withopen(data_path / f"{title}.txt", 'w') as fp: fp.write(wiki_text)
# Load all wiki documents city_docs = [] for wiki_title in wiki_titles: docs = SimpleDirectoryReader(input_files=[f"data/{wiki_title}.txt"]).load_data() docs[0].doc_id = wiki_title city_docs.extend(docs)
# default mode of building the index response_synthesizer = ResponseSynthesizer.from_args(response_mode="tree_summarize", use_async=True) doc_summary_index = GPTDocumentSummaryIndex.from_documents( city_docs, service_context=service_context, response_synthesizer=response_synthesizer )