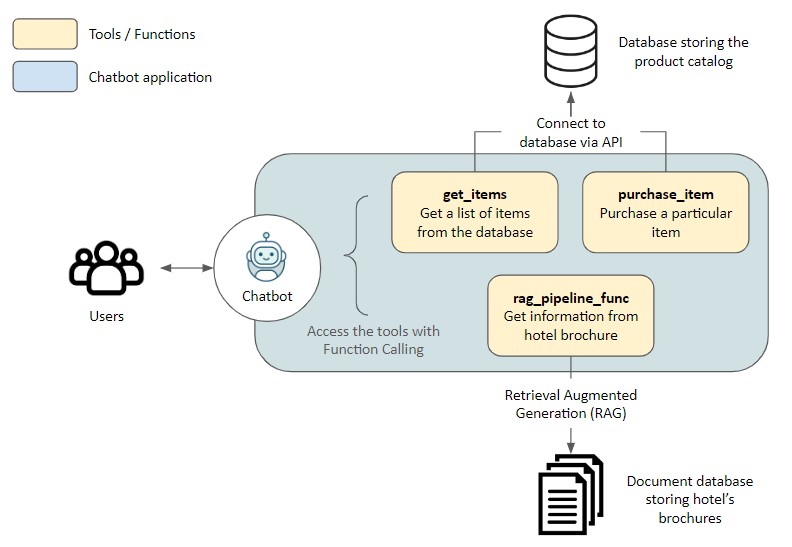
我们首先连接到 OpenRouter。或者,只要您有 OpenAI API 密钥,使用原始 OpenAIChatGenerator 文件而不覆盖 也可以 api_base_url
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
import os from dotenv import load_dotenv from haystack.components.generators.chat import OpenAIChatGenerator from haystack.utils import Secret from haystack.dataclasses import ChatMessage from haystack.components.generators.utils import print_streaming_chunk
# Set your API key as environment variable before executing this load_dotenv() OPENROUTER_API_KEY = os.environ.get('OPENROUTER_API_KEY')
chat_generator.run(messages=[ChatMessage.from_user("Return this text: 'test'")]) ---------- The response should look like this ---------- {'replies': [ChatMessage(content="'test'", role=<ChatRole.ASSISTANT: 'assistant'>, name=None, meta={'model': 'openai/gpt-4-turbo-preview', 'index': 0, 'finish_reason': 'stop', 'usage': {}})]}
Step 1: 建立数据存储
在这里,我们在应用程序和两个数据源之间建立连接:非结构化文本的文档存储和通过 API 的应用程序数据库
from haystack import Pipeline, Document from haystack.document_stores.in_memory import InMemoryDocumentStore from haystack.components.writers import DocumentWriter from haystack.components.embedders import SentenceTransformersDocumentEmbedder
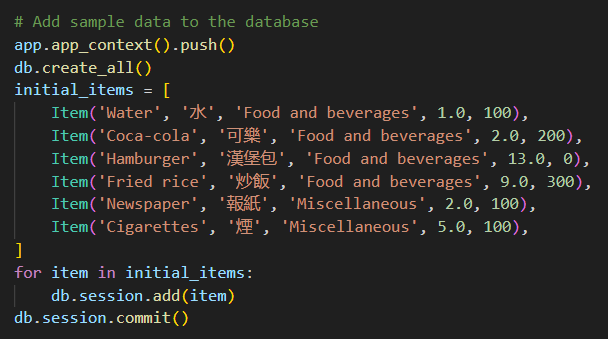
# Sample documents documents = [ Document(content="Coffee shop opens at 9am and closes at 5pm."), Document(content="Gym room opens at 6am and closes at 10pm.") ]
# Create the document store document_store = InMemoryDocumentStore()
# Create a pipeline to turn the texts into embeddings and store them in the document store indexing_pipeline = Pipeline() indexing_pipeline.add_component( "doc_embedder", SentenceTransformersDocumentEmbedder(model="sentence-transformers/all-MiniLM-L6-v2") ) indexing_pipeline.add_component("doc_writer", DocumentWriter(document_store=document_store))
from haystack.components.embedders import SentenceTransformersTextEmbedder from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever from haystack.components.builders import PromptBuilder from haystack.components.generators import OpenAIGenerator
template = """ Answer the questions based on the given context. Context: {% for document in documents %} {{ document.content }} {% endfor %} Question: {{ question }} Answer: """ rag_pipe = Pipeline() rag_pipe.add_component("embedder", SentenceTransformersTextEmbedder(model="sentence-transformers/all-MiniLM-L6-v2")) rag_pipe.add_component("retriever", InMemoryEmbeddingRetriever(document_store=document_store)) rag_pipe.add_component("prompt_builder", PromptBuilder(template=template)) # Note to llm: We are using OpenAIGenerator, not the OpenAIChatGenerator, because the latter only accepts List[str] as input and cannot accept prompt_builder's str output rag_pipe.add_component("llm", OpenAIGenerator(api_key=Secret.from_env_var("OPENROUTER_API_KEY"), api_base_url="https://openrouter.ai/api/v1", model="openai/gpt-4-turbo-preview"))
# Flask's default local URL, change it if necessary db_base_url = 'http://127.0.0.1:5000'
# Use requests to get the data from the database import requests import json
# get_categories is supplied as part of the prompt, it is not used as a tool defget_categories(): response = requests.get(f'{db_base_url}/category') data = response.json() return data
defget_items(ids=None,categories=None): params = { 'id': ids, 'category': categories, } response = requests.get(f'{db_base_url}/item', params=params) data = response.json() return data
tools = [ { "type": "function", "function": { "name": "get_items", "description": "Get a list of items from the database", "parameters": { "type": "object", "properties": { "ids": { "type": "string", "description": "Comma separated list of item ids to fetch", }, "categories": { "type": "string", "description": "Comma separated list of item categories to fetch", }, }, "required": [], }, } }, { "type": "function", "function": { "name": "purchase_item", "description": "Purchase a particular item", "parameters": { "type": "object", "properties": { "id": { "type": "string", "description": "The given product ID, product name is not accepted here. Please obtain the product ID from the database first.", }, "quantity": { "type": "integer", "description": "Number of items to purchase", }, }, "required": [], }, } }, { "type": "function", "function": { "name": "rag_pipeline_func", "description": "Get information from hotel brochure", "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "The query to use in the search. Infer this from the user's message. It should be a question or a statement", } }, "required": ["query"], }, }, } ]
Step 3: 将它们放在一起
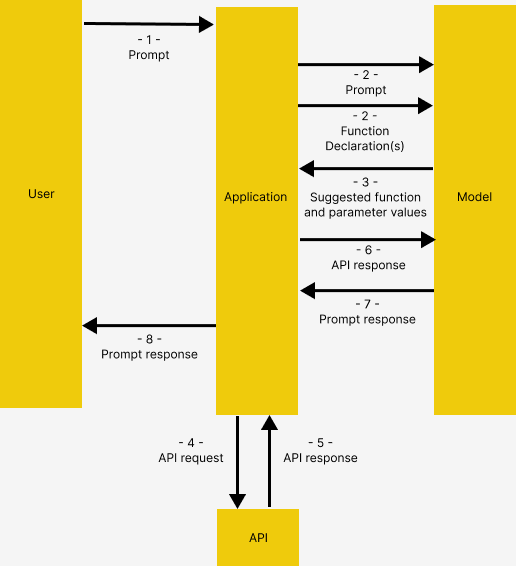
现在,我们有了测试函数调用的必要输入!在这里,我们做一些事情:
向模型提供初始提示,为其提供一些上下文
提供用户生成的消息示例
最重要的是,我们将工具列表传递给聊天 tools 生成器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# 1. Initial prompt context = f"""You are an assistant to tourists visiting a hotel. You have access to a database of items (which includes {get_categories()}) that tourists can buy, you also have access to the hotel's brochure. If the tourist's question cannot be answered from the database, you can refer to the brochure. If the tourist's question cannot be answered from the brochure, you can ask the tourist to ask the hotel staff. """ messages = [ ChatMessage.from_system(context), # 2. Sample message from user ChatMessage.from_user("Can I buy a coffee?"), ]
# 3. Passing the tools list and invoke the chat generator response = chat_generator.run(messages=messages, generation_kwargs= {"tools": tools}) response ---------- Response ---------- {'replies': [ChatMessage(content='[{"index": 0, "id": "call_AkTWoiJzx5uJSgKW0WAI1yBB", "function": {"arguments": "{\\"categories\\":\\"Food and beverages\\"}", "name": "get_items"}, "type": "function"}]', role=<ChatRole.ASSISTANT: 'assistant'>, name=None, meta={'model': 'openai/gpt-4-turbo-preview', 'index': 0, 'finish_reason': 'tool_calls', 'usage': {}})]}
现在让我们检查一下响应。请注意,函数调用如何返回模型选择的函数,以及用于调用所选函数的参数。
1 2 3 4 5 6 7 8
function_call = json.loads(response["replies"][0].content)[0] function_name = function_call["function"]["name"] function_args = json.loads(function_call["function"]["arguments"]) print("Function Name:", function_name) print("Function Arguments:", function_args) ---------- Response ---------- Function Name: get_items Function Arguments: {‘categories’: ‘Food and beverages’}
当出现另一个问题时,模型将使用另一个更相关的工具
1 2 3 4 5 6 7 8 9 10 11 12 13
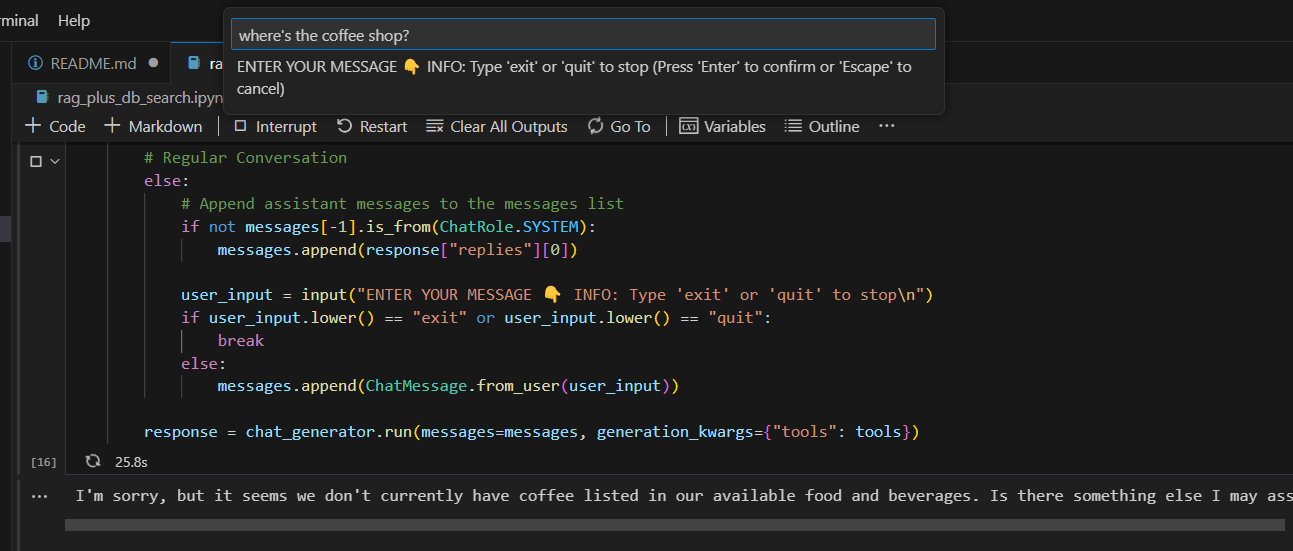
# Another question messages.append(ChatMessage.from_user("Where's the coffee shop?"))
# Invoke the chat generator, and passing the tools list response = chat_generator.run(messages=messages, generation_kwargs= {"tools": tools}) function_call = json.loads(response["replies"][0].content)[0] function_name = function_call["function"]["name"] function_args = json.loads(function_call["function"]["arguments"]) print("Function Name:", function_name) print("Function Arguments:", function_args) ---------- Response ---------- Function Name: rag_pipeline_func Function Arguments: {'query': "Where's the coffee shop?"}
同样,请注意,这里没有调用任何实际函数,这就是我们接下来要做的!
调用函数
然后,我们可以将参数输入到所选函数中
1 2 3 4 5 6 7
## Find the correspoding function and call it with the given arguments available_functions = {"get_items": get_items, "purchase_item": purchase_item,"rag_pipeline_func": rag_pipeline_func} function_to_call = available_functions[function_name] function_response = function_to_call(**function_args) print("Function Response:", function_response) ---------- Response ---------- Function Response: {'reply': 'The provided context does not specify a physical location for the coffee shop, only its operating hours. Therefore, I cannot determine where the coffee shop is located based on the given information.'}
print(response_msg.content) ---------- Response ---------- For the location of the coffee shop within the hotel, I recommend asking the hotel staff directly. They will be able to guide you to it accurately.
whileTrue: # if OpenAI response is a tool call if response and response["replies"][0].meta["finish_reason"] == "tool_calls": function_calls = json.loads(response["replies"][0].content)
for function_call in function_calls: ## Parse function calling information function_name = function_call["function"]["name"] function_args = json.loads(function_call["function"]["arguments"])
## Find the correspoding function and call it with the given arguments function_to_call = available_functions[function_name] function_response = function_to_call(**function_args)
## Append function response to the messages list using `ChatMessage.from_function` messages.append(ChatMessage.from_function(content=json.dumps(function_response), name=function_name))
# Regular Conversation else: # Append assistant messages to the messages list ifnot messages[-1].is_from(ChatRole.SYSTEM): messages.append(response["replies"][0])
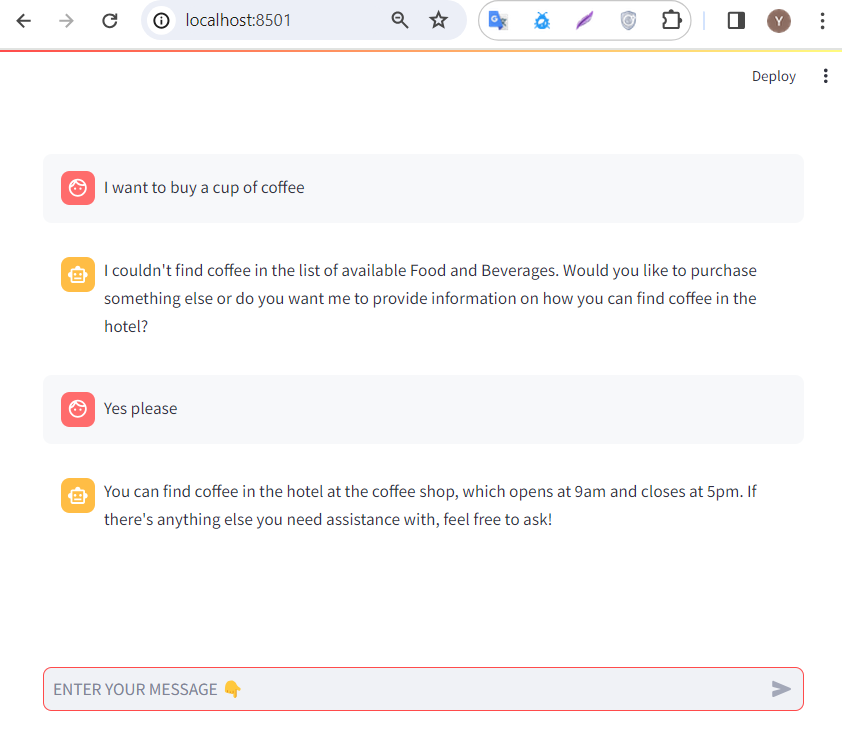
user_input = input("ENTER YOUR MESSAGE .. INFO: Type 'exit' or 'quit' to stop\n") if user_input.lower() == "exit"or user_input.lower() == "quit": break else: messages.append(ChatMessage.from_user(user_input))