介绍
世界正在向数字时代发展,在这个时代,每个人都可以通过点击距离获得几乎所有他们想要的东西。可访问性、舒适性和大量的产品为消费者带来了新的挑战。我们如何帮助他们获得个性化的选择,而不是在浩瀚的选择海洋中搜索?这就是推荐系统的用武之地。
推荐系统可以帮助组织增加交叉销售和长尾产品的销售,并通过分析客户最喜欢什么来改进决策。不仅如此,他们还可以学习过去的客户行为,给定一组产品,根据特定的客户偏好对它们进行排名。使用推荐系统的组织在竞争中领先一步,因为它们提供了增强的客户体验。
在本文中,我们将重点介绍FinalMLP,这是一个旨在提高在线广告和推荐系统中点击率(CTR)预测的新模型。通过将两个多层感知器(MLP)网络与门控和交互聚合层等高级功能集成在一起,FinalMLP优于传统的单流MLP模型和复杂的双流CTR模型。作者通过基准数据集和现实世界的在线A/B测试测试了它的有效性。
除了提供FinalMLP及其工作原理的详细视图外,我们还提供了实现和将其应用于公共数据集的演练。我们在一个图书推荐设置中测试了它的准确性,并评估了它解释预测的能力,利用作者提出的两流架构。
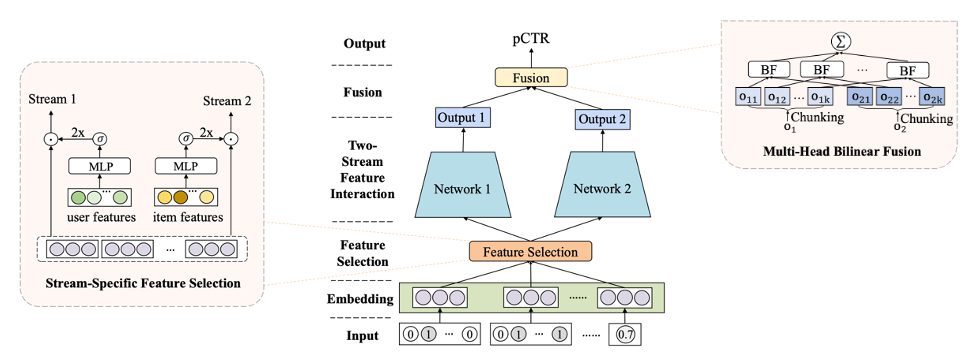
FinalMLP: (F)特征门控层和(IN)交互层(A)聚合层(L)在两个mlp之上
FinalMLP[1]是建立在DualMLP[2]之上的两流多层感知器(MLP)模型,通过引入两个新概念对其进行增强:
- 基于门控的特征选择增加了两个流之间的区别,使每个流专注于从不同的特征集学习不同的模式。例如,一个流侧重于处理用户特征,而另一个流侧重于处理项目特征。
- 多头双线性融合改进了两个流的输出如何通过建模特征交互进行组合。使用依赖于求和或串联等线性操作的传统方法可能不会发生这种情况。

Figure 2: FinalMLP architecture (source)
它是如何工作的?
如前所述,FinalMLP是由两个简单并行的MLP网络组成的两流CTR模型,从不同的角度学习特征交互,它由以下关键组件组成:
特征embedding 层是一种将高维和稀疏的原始特征映射到密集数字表示的常用方法。无论是分类的、数值的还是多值的,每个特征都被转换成一个embedding向量并连接起来,然后再输入feature Selection模块。
将Categorical Features转换为单热特征向量,并与词汇量n、embedding维数d的可学习embedding矩阵相乘,生成其嵌入[3]。
数值特征可以通过以下方式转换为嵌入:1)将数值存储为离散特征,然后将它们作为分类特征处理,或者2)给定标准化标量值xj,embedding可以作为xj与vj 的乘法, vj 是j域中所有特征的共享embedding向量[3].
多值 f特征可以表示为将值序列转换为长度为k的单热编码向量(k为序列的最大长度),然后乘以一个可学习的embedding矩阵来生成其嵌入[3]。
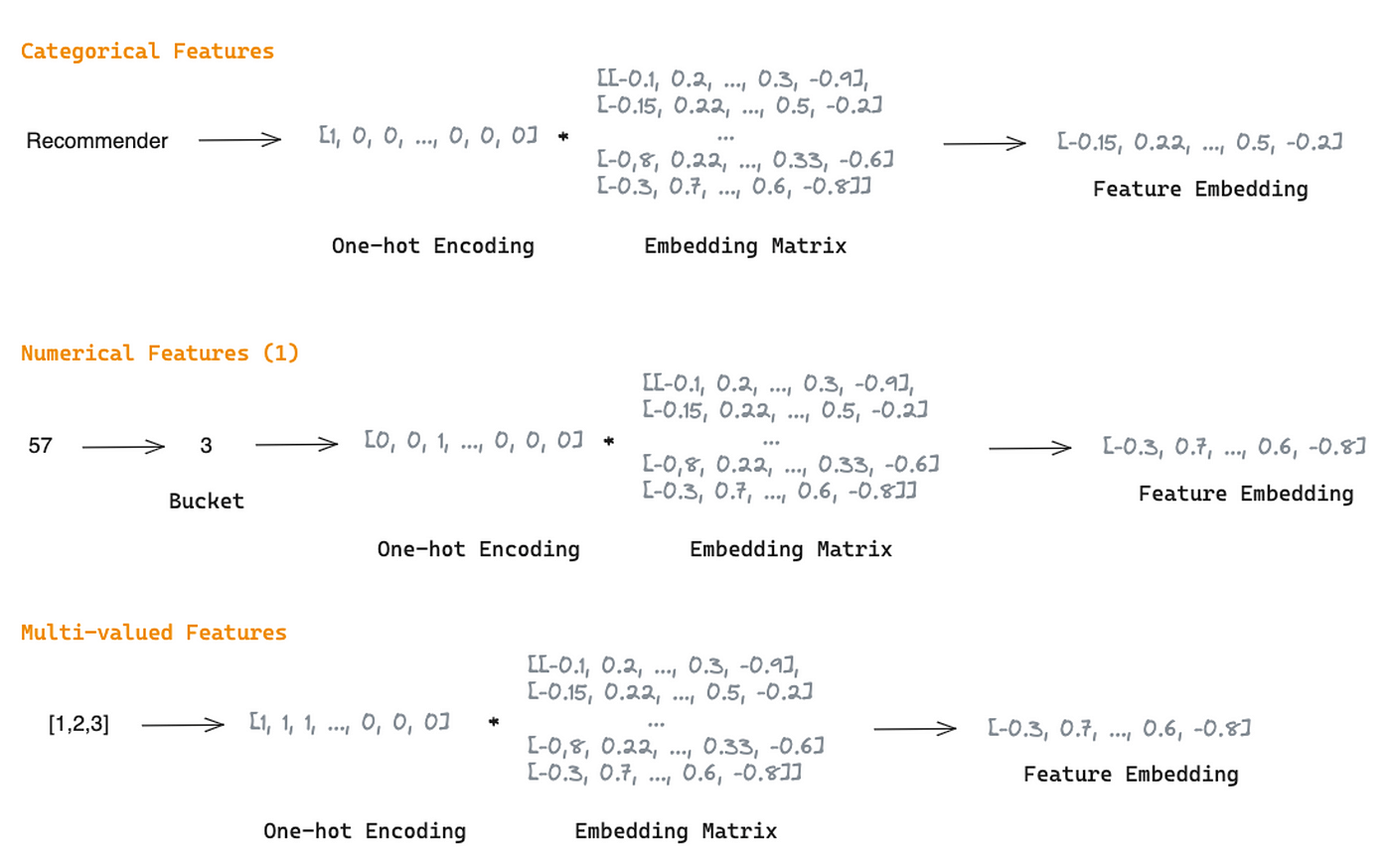
图3:每种特征类型的embedding创建(由作者提供的图像)
The feature Selection Layer用于获取特征重要性权重,以抑制噪声特征,使重要特征对模型预测的影响更大。
如前所述,FinalMLP使用基于门控的特征选择,这是一个带有门控机制的MLP。它接收嵌入作为输入,并产生与输入相同维数的权重向量。特征重要性权重是通过对权重向量应用sigmoid函数,然后对乘数2进行乘数,生成一个范围为[0,2]的向量来获得的。然后通过特征embedding与特征重要性权重的逐元素积得到加权特征。
这个过程减少了两个流之间的同质学习,使特征交互的学习更加互补。它被独立地应用于每个流,以区分每个流的特征输入,并允许它们专注于用户或项目维度。
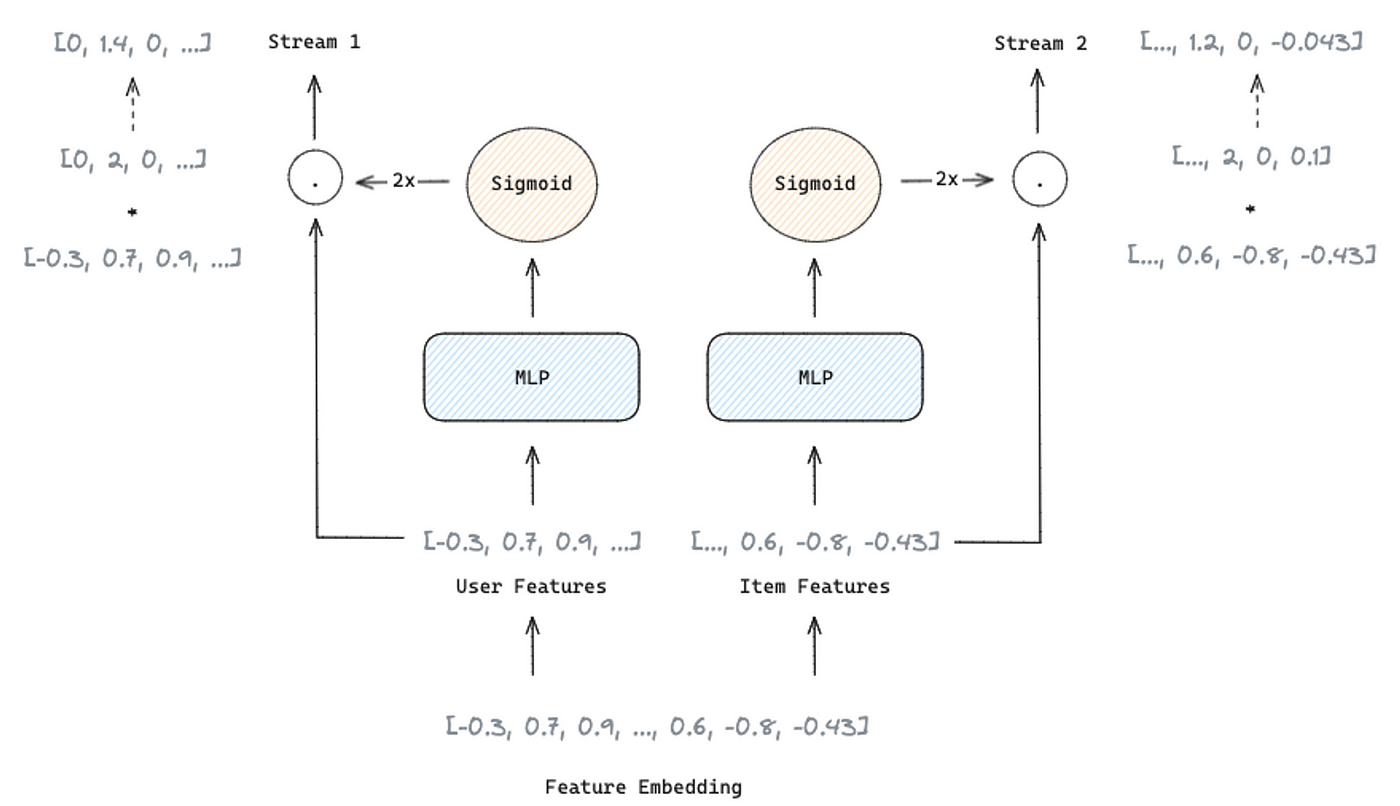
图4:使用独立MLP的特征选择过程,每个流都有一个门控机制(图片来自作者)
流级融合层需要结合两个流的输出,以获得最终的预测概率。通常,组合两个输出依赖于求和或连接操作。然而,FinalMLP的作者提出了一个双线性交互聚合层,将两个输出结合起来,从特征交互中获得线性组合可能无法获得的信息。
受transformers结构中的注意力层的启发,作者将双线性融合扩展为多头双线性融合层。它用于降低计算复杂度和提高模型的可扩展性。
双线性融合方程包括:
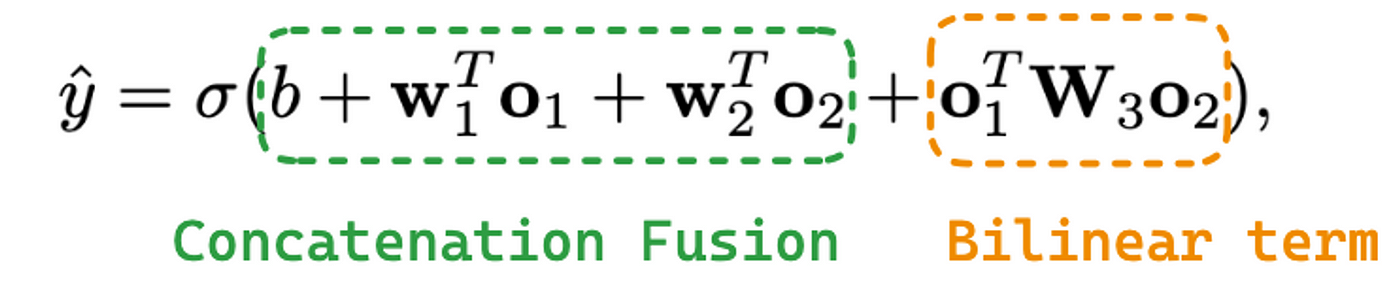
方程1:双线性融合方程
其中σ是一个s型函数,b是偏置项,01是一个流的输出。w1是要应用到o1的可学习权值,o2是另一个流的输出,w2是要应用到o2的可学习权值。最后,w3为提取特征交互信息的双线性项中的可学习矩阵。如果将w3设置为零矩阵,则退化为传统的串联融合。
双线性融合和多头双线性融合的区别在于,它不是使用来自两个流的整个向量应用双线性融合,而是将输出o1和o2chunks到k子空间中。在每个子空间中进行双线性融合,聚合并馈送s型函数以产生最终概率。
图5:多头双线性融合的实践(图片来源:作者)
使用FinalMLP创建图书推荐模型
在本节中,我们将在许可CC0:公共领域下的Kaggle的公共数据集上实现FinalMLP。该数据集包含有关用户、图书以及用户对图书的评分的信息。
该数据集由以下内容组成:
User-ID—用户标识Location—以逗号分隔的字符串,包含用户所在的城市、州和国家Age— 用户的年龄ISBN— 图书标识符Book-Rating— 用户对某本书的评分Book-Title— 书的标题Book-Author— 书的作者Year-of-Publication— 该书出版的年份Publisher— 出版这本书的编辑
我们将根据与每个用户的相关性对图书进行排名。之后,我们使用归一化贴现累积增益(nDCG)将我们的排名与实际排名进行比较(根据用户给出的评级对图书进行排序)。
nDCG是一种评估推荐系统质量的度量标准,它根据结果的相关性来衡量结果的排名。它考虑每个项目的相关性及其在结果列表中的位置,排名越高,重要性越大。nDCG的计算方法是将折扣累积收益(DCG)与理想DCG (iDCG)进行比较,后者是将排名较低的物品的收益进行折扣,而理想DCG是给出完美排名的最高可能DCG。这个标准化分数的范围在0到1之间,其中1表示理想的排名顺序。因此,nDCG为我们提供了一种理解系统如何有效地向用户呈现相关信息的方法。
我们从导入库开始:
1 | %matplotlib inline |
然后,我们加载三个数据集并将它们合并为一个数据集:
1 | books_df = pd.read_csv('data/book/Books.csv') |
之后,我们进行一些探索性数据分析,以识别数据中的问题:
- 删除用户对书没有评价的地方。
1 | df = df[df['Book-Rating'].notnull()] |
- 检查缺失的值并将缺失的
Book-Author和Publisher替换为unknown类别。
1 | print(df.columns[df.isna().any()].tolist()) |
- 删除书中缺失信息的评论。
1 | df = df[df['Book-Title'].notnull()] |
- 将非整数’出版年份’替换为空值。
1 | df['Year-Of-Publication'] = pd.to_numeric(df['Year-Of-Publication'], errors='coerce') |
- 检查“年龄”、“出版年份”和“图书评级”分布,以识别异常情况。
1 | plt.rcParams["figure.figsize"] = (20,3) |
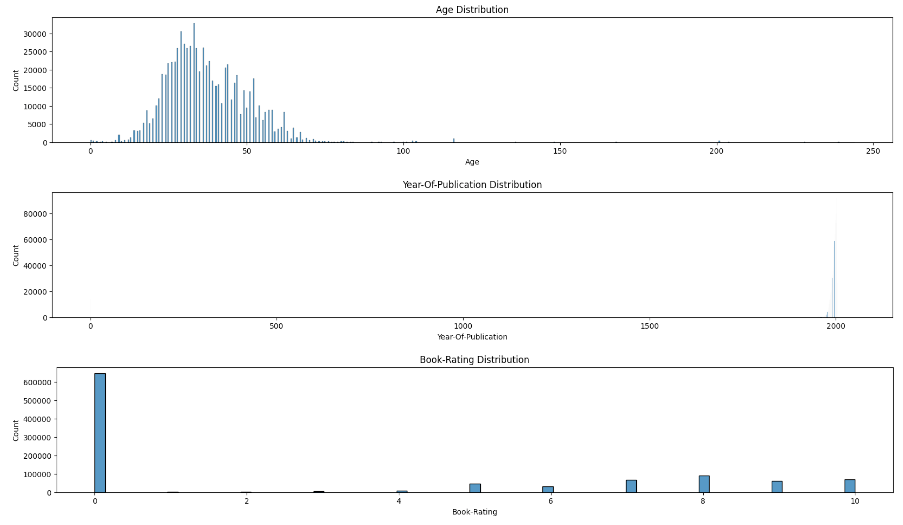
图6:数据分布(作者图片)
最后,我们通过以下方式清理数据:
- 替换
age > 100(这似乎是一个错误),丢失的值稍后处理。 - 将上限限制为2021年,因为这是数据集在Kaggle中发布的时间,并将
Year-of-Publication <= 0替换为稍后处理的缺失值。 - 删除
rating = 0的观察,因为这些书被用户阅读但没有评级。 - 从“位置”创建3个新功能(“城市”,“州”,“国家”)。既然城市太吵了,我们就不去了。
- 为FinalMLP创建一个二进制标签,我们考虑与用户相关的率高于7的书籍。
1 | df['Age'] = np.where(df['Age'] > 100, None, df['Age']) |
清理数据集后,我们将数据分为训练、验证和测试,随机选择70%的用户进行训练,10%的用户进行验证,20%的用户进行测试。
1 | # create list with unique users |
在将数据输入模型之前,我们将对数据进行一些预处理:
我们使用多语言编码器为文本特征Book-Title创建嵌入,并使用PCA降低维度,解释了80%的方差。
我们使用多语言编码器,因为标题是用不同的语言编写的。请注意,我们首先提取不同的Book-title,以便在用户多于另一本书时不影响降维。
1 | # create embeddings |
我们用中值填充数值特征的缺失值,并使用MinMaxScaler对数据进行归一化。
1 | # set numerical columns |
准备好提供给FinalMLP的所有数据后,我们必须创建两个yaml配置文件:dataset_config.yaml和model_config.yaml。
dataset_config.yaml负责定义模型中使用的特性。此外,它还定义了它们的数据类型(它们在embedding层中的处理方式不同)以及到训练集、验证集和测试集的路径。你可以看到配置文件的主要部分如下:
1 | FinalMLP_book: |
model_config.yaml负责设置模型的超参数。您还必须定义哪些流将处理用户特性,哪些流将处理项目特性。该文件应定义如下:
1 | FinalMLP_book: |
我们回到Python并加载最近创建的配置文件。然后,我们创建特征映射(即,每个分类特征中有多少个类别,如果存在,它应该如何替换不同特征中的缺失值,等等)。我们将csv转换为h5文件。
1 | # Get model and dataset configurations |
之后,我们就可以开始模型的训练过程了。
1 | model_class = getattr(src, params['model']) |
最后,我们可以预测看不见的数据;我们只需要将批大小更改为1就可以对所有观察值进行评分。
1 | # to score all observations |
我们选择了一个有不止一本书评级的客户,并且每本书都有不同的评级,以实现没有关系的适当排名。它的nDCG分数是0.986362,因为我们放错了2本书,距离为1位。
我们还使用Recall来评估FinalMLP。召回率是一个度量系统从一个集合中识别所有相关项目的能力的度量,表示为从可用的所有相关项目中检索到的相关项目的百分比。当我们指定Recall@K(比如Recall@3)时,我们关注的是系统在前K个推荐中识别相关项目的能力。这种适应对于评估推荐系统至关重要,因为用户主要关注的是最热门的推荐。K的选择(例如,3)取决于典型的用户行为和应用程序的上下文。
如果我们看一下这个客户的Recall@3,我们有100%,因为另外三本相关的书被放在了前3个位置。
1 | true_relevance = np.asarray([test_df[test_df['User-ID'] == 1113]['Book-Rating'].tolist()]) |
我们还计算了剩余测试集的nDCG分数,并将FinalMLP性能与CatBoost Ranker进行了比较,如图7所示。虽然这两个模型都表现得很好,但FinalMLP在这个测试集上的表现略好,每个用户的平均nDCG为0.963298,而CatBoost Ranker *only*达到了0.959977。
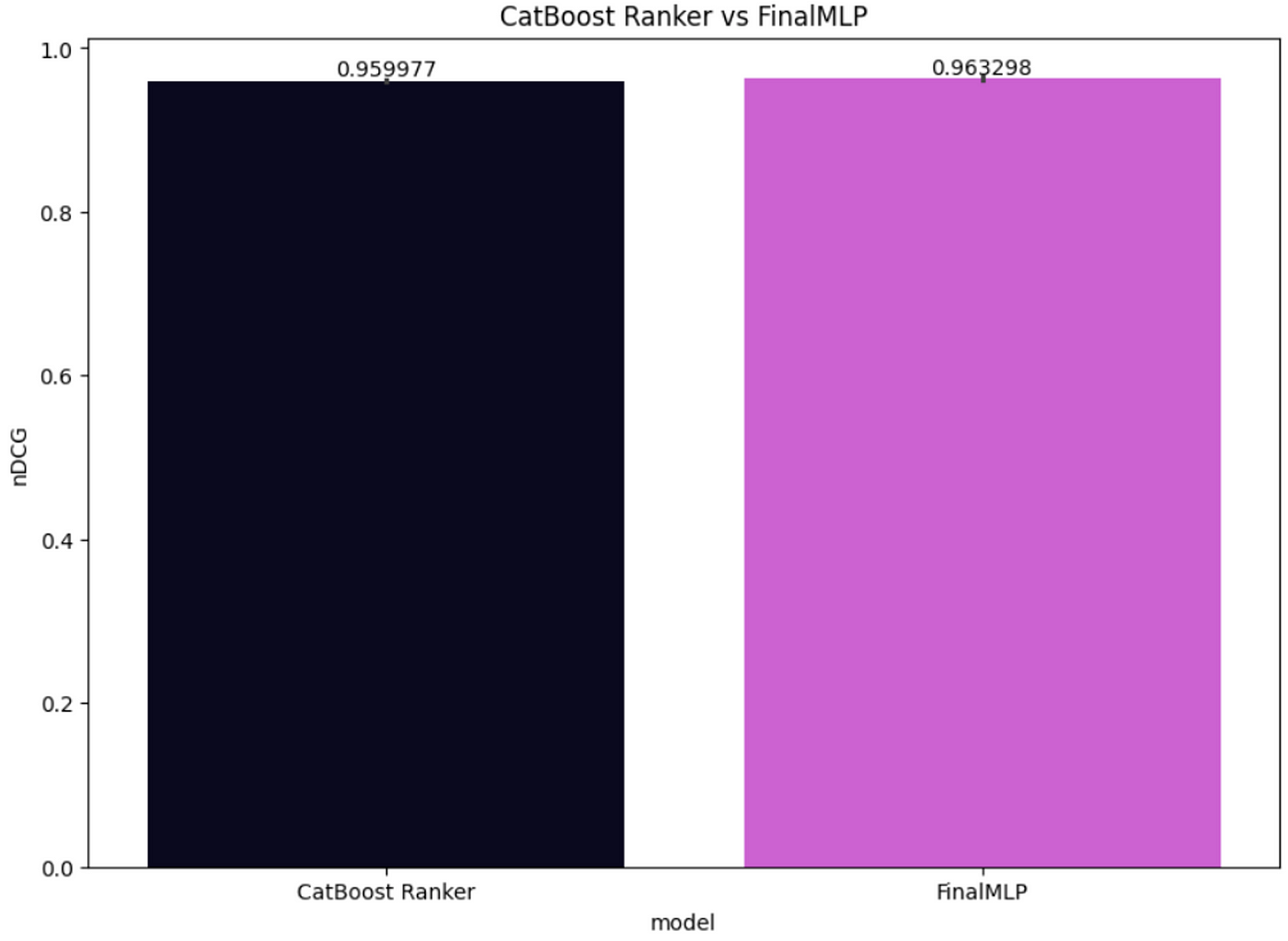
图7:CatBoost Ranker与FinalMLP的nDCG对比(图片来源:作者)
在可解释性方面,该模型执行特征选择,使我们能够提取权重向量。然而,解释和理解每个特性的重要性并不简单。请注意,在embedding层之后,我们最终得到了一个930维的向量,这使得将其映射回原始特征变得更加困难。尽管如此,我们可以尝试通过提取每个流的输出经过线性处理后的绝对值来理解每个流的重要性,这些线性处理由前面提到的线性项给出,如公式2所示。
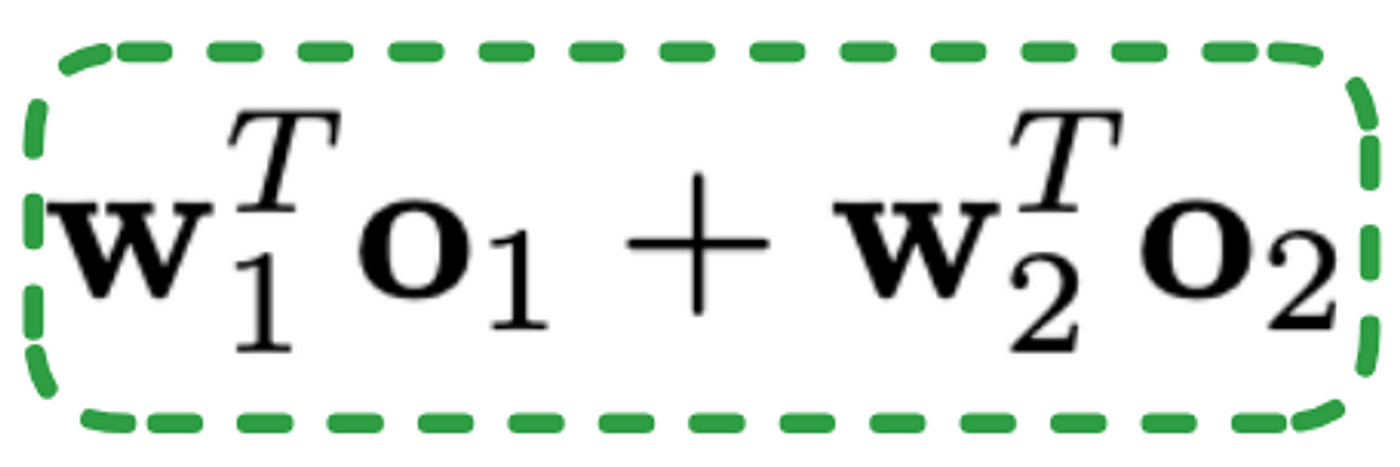
方程2:线性项
为此,我们需要更改 InteractionAggregation模块,并添加以下代码行来提取每一步后的线性转换值:
1 |
|
经过训练后,我们可以预测并绘制出每个流的线性变换所产生的绝对值。如图8所示,项目流比用户流更重要。之所以会出现这种情况,是因为我们有更多关于物品的功能,但也因为用户功能非常普遍。
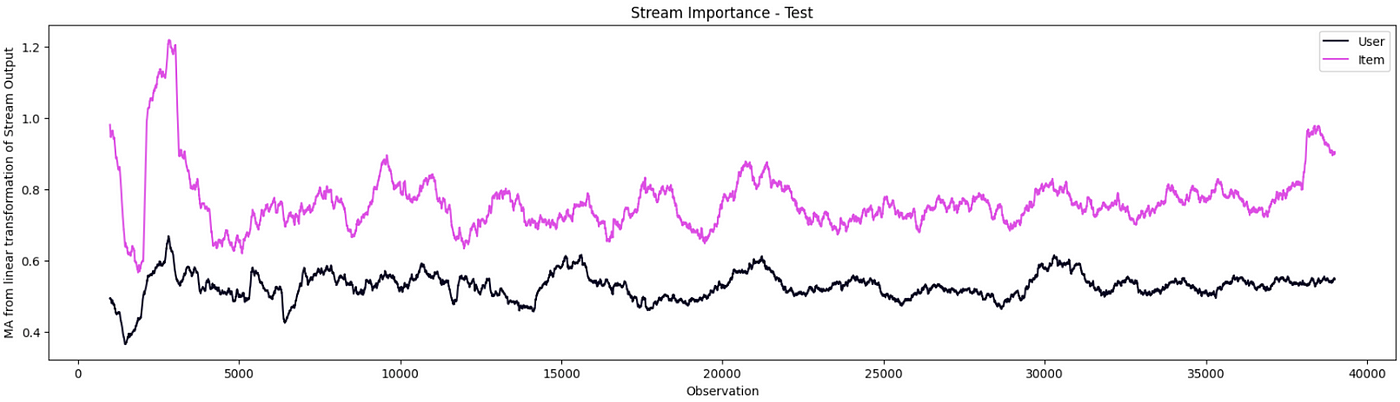
图8:用户流和项目流的重要性对比(作者图片)
结论
推荐系统通过提供个性化推荐和授权组织做出驱动增长和创新的数据驱动决策来增强用户体验。
在本文中,我们介绍了为推荐系统开发的最新模型之一。最后,mlp是一个具有两个独立网络的深度学习模型。每个网络都将其学习集中在两个不同视角中的一个:用户和项目。然后将从每个网络学习到的不同模式馈送到一个融合层,该融合层负责将每个网络的学习结合起来。它创建用户-项目对交互的单一视图,以生成最终分数。该模型在我们的用例中表现良好,击败了CatBoost Ranker。
请注意,算法的选择可能取决于您要解决的问题和您的数据集。对几种方法进行相互比较测试总是好的做法。您还可以考虑测试xDeepFM、AutoInt、hen或DLRM。
参考文献
[1] Kelong Mao, Jieming Zhu, Liangcai Su, Guohao Cai, Yuru Li, Zhenhua Dong. FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction. arXiv:2304.00902, 2023.
[2] Jiajun Fei, Ziyu Zhu, Wenlei Liu, Zhidong Deng, Mingyang Li, Huanjun Deng, Shuo Zhang. DuMLP-Pin: A Dual-MLP-dot-product Permutation-invariant Network for Set Feature Extraction. arXiv:2203.04007, 2022.
[3] Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, Xiuqiang He. BARS-CTR: Open Benchmarking for Click-Through Rate Prediction. arXiv:2009.05794, 2020.

