检索增强生成(RAG)是通过集成来自外部知识来源的附加信息来改进大型语言模型(大语言模型)的过程。这允许大语言模型产生更精确和上下文感知的反应,同时也减轻幻觉。
自2023年以来,RAG已成为基于LLM的系统中最流行的架构。许多产品的功能都严重依赖于RAG。因此,优化RAG的性能,使检索过程更快,结果更准确成为一个至关重要的问题。
本系列文章将重点介绍先进的RAG技术,以提高RAG生成的质量。
朴素RAG回顾
朴素RAG的典型工作流程如图1所示。
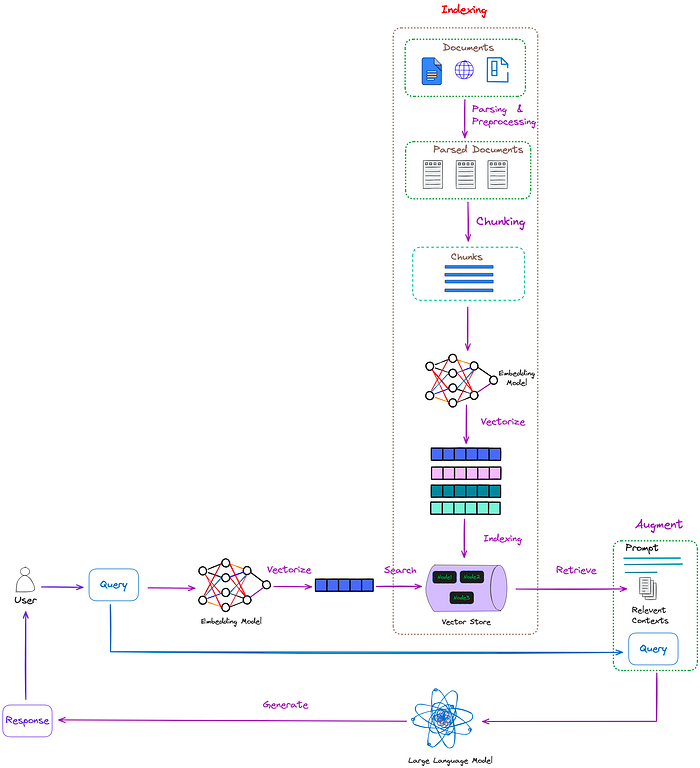
图1:朴素RAG的典型工作流程。图片来自作者。
如图1所示,RAG主要包括以下几个步骤:
- 索引(indexing):索引过程是离线执行的关键初始步骤。首先清理和提取原始数据,将各种文件格式(如PDF、HTML和Word)转换为标准化的纯文本。为了适应语言模型的上下文约束,这些文本被分成更小、更易于管理的块,这个过程称为分块。然后使用Embedding模型将这些块转换为向量表示。最后,创建一个索引,将这些文本块及其向量Embeddings存储为键值对,从而实现高效和可扩展的搜索功能。
- 检索(Retrieval):用户查询用于从外部知识来源检索相关上下文。为了实现这一点,用户查询由编码模型处理,该模型生成语义相关的Embeddings。然后,在向量数据库上进行相似性搜索,检索最接近的k个数据对象。
- 生成(Generation):将用户查询和检索到的附加上下文填充到prompt模板中。最后,将检索步骤得到的增强prompt输入到LLM中。
简易RAG的问题
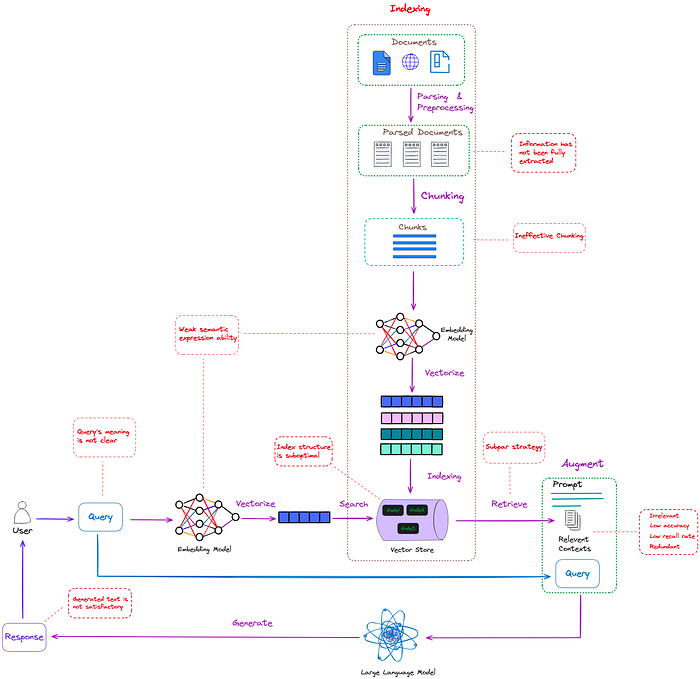
图2:朴素RAG有问题(红色虚线框)。图片来自作者。
如图2所示,朴素RAG在上面提到的所有三个步骤中都存在问题(红色虚线框),并且有足够的优化空间。
Indexing(索引化)
- 信息提取不完整,不能有效处理非结构化文件(如PDF)中的图像和表格中的有用信息。
- 分块过程采用“一刀切”策略,而不是根据不同文件类型的特点选择最优策略。这导致每个块包含不完整的语义信息。此外,它没有考虑重要的细节,例如文本中现有的标题。
- 索引结构没有充分优化,导致检索效率低下。
- Embedding模型的语义表示能力较弱。
Retrieval(检索)
- 回忆上下文的相关性不足,准确性低。
- 低召回率阻碍了所有相关段落的检索,从而阻碍了大语言模型生成全面答案的能力。
- 查询可能不准确或Embedding模型的语义表示能力较弱,导致无法检索到有价值的信息。
- 检索算法的局限性在于没有结合不同类型的检索方法或算法,如组合关键字检索、语义检索、向量检索等。
- 当多个检索上下文包含相似的信息时,会出现信息冗余,导致生成的答案中的内容重复。
Generation(生成)
- 可能无法有效地将检索到的上下文与当前生成任务集成,从而导致输出不一致。
- 在生成过程中过度依赖增强信息存在较高风险。这可能导致输出只是简单地重复检索的内容,而不提供有价值的信息。
- LLM可能会产生不正确、不相关、有害或有偏见的反应。
请注意,这些问题的原因可能是多方面的。例如,如果给用户的最终响应包含不相关的内容,它可能不仅仅是由于LLM问题。潜在的原因可能是从PDF中不精确地提取文档,或者Embedding模型无法准确捕获语义,等等。
英文原文:https://ai.plainenglish.io/advanced-rag-part-01-problems-of-naive-rag-7e5f8ebb68d5

