主要内容:
RAG在我们产品体系中的定位;
TorchV RAG的技术选型;
RAG知识目录
0.开始
从9月份开始在微信公众号分享RAG技术以来,收获了很多来自业界的认可和鼓励,所以11月中旬从老东家离职之后就和小明开始了创业之旅——创建了TorchV品牌,主要是围绕RAG+LLM的产品研发和应用销售。经过一个多月的努力,我们已经有了一个基础架构和一个产品。当然和规划中的成型战力还有一定的距离,但是依然可以分享一下RAG在TorchV产品体系中应用情况,主要包含以下三个问题:
- TorchV如何围绕RAG打造产品体系?
- TorchV RAG的技术选型;
- 常见问题。
TorchV名字由来
在进入正题之前,先允许我用一分钟介绍一个TorchV这个名字的由来。
- Pytorch:在AI行业的朋友都应该知道PyTorch这个深度学习计算框架(库),应该说目前除了谷歌系的大模型外,几乎所有的大语言模型(比如GPT、Llama、GLM等)都是基于Pytorch开发的。所以我们取了Pytorch中的torch(代码中大家用的其实就是torch),然后加了一个V,代表了向量(其实是因为 torchv.com 能注册);
- 火炬:torch本身的意思是火炬,在传统的三元九运里面,接下来20年是火运,..是“大势所趋”,哈哈,你懂的!
所以,这就是TorchV名字的由来,哈。

1.RAG的定位
对于大语言模型(Large Language Model,LLM)是什么,相信读这篇文章的读者应该都不需要我再专门展开介绍了,也正是LLM掀起了这拨AI新浪潮。对于个人用户来说,GPT-4、Claude等LLM可以直接用,而且用的很爽,但对于企业应用来说,情况就复杂得多——实效性、私有数据、幻觉和数据安全,都可能成为隐患。
好马配好鞍
这时候,我们发现了检索增强生成(Retrieval-Augmented Generation,RAG),这是目前为止我们认为最经济、最有效的企业级LLM解决方案。如果把LLM比作一匹野马,那么RAG就是一副马鞍。
我们在3月份在部署了ChatGLM-6B,4月份微调了Dolly2,到了5月份全量训练了BLOOM-7B(用了8块A100)。在这个过程中,我们知道全量训练的昂贵成本,一个7B(70亿个参数)模型已经让我们直不起腰了。所以,对于大模型我们一般可以做的事情就剩下三件:Prompt工程、微调(Fine-Tune)和RAG(感觉上我提这三点的时候国内几乎是还没看见其他人在提的,也有可能是大神们不屑于发表)。在实践中,我们觉得Fine-Tune还是有点奢侈的,特别是数据整理是个大问题,基本上当时的微调都需要按目标数据和通用数据比1:7的比例喂进去,微调成本(不仅仅是money)过于高,有点像是给马儿打造一辆马车。所以,对于不是专职做大模型的团队来说,微调至少不能当做常规手段,尽管我们依然会对LLM和embedding模型做一些微调。再接下来就是Prompt工程,当时宝玉翻译的吴恩达视频算是一个入门,后面更是直接看外网资料学习,Prompt工程确实有效,而且很自然地成了RAG中的一环。而在我们的实践中,RAG最终成了最靠谱的解决方案。
关于RAG的系统性介绍可以看我之前的一篇文章《大模型主流应用RAG的介绍——从架构到技术细节》,文末也有一个关于RAG各部分细节的目录,大家如果想要了解或学习RAG,那可以按文末的目录进行查阅。
本文主要讲的还是RAG在TorchV产品系列中的定位,分享我们的实践和心得。
围绕RAG打造产品
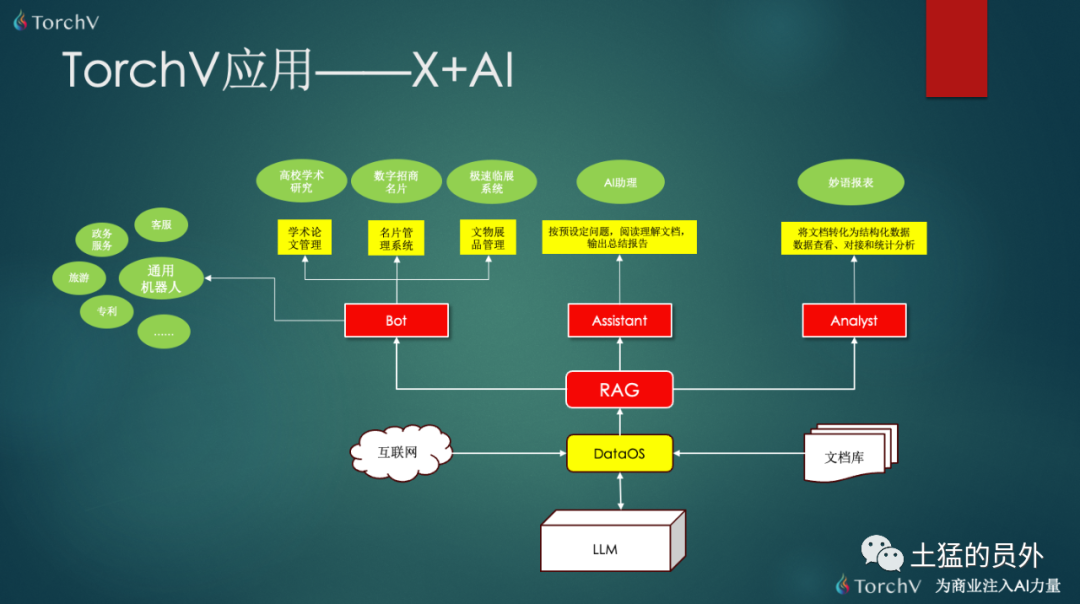
我们可以看到RAG刚好处于整个产品体系的中间。
在RAG上面,首先是基于RAG打造三个基线产品:Bot(机器人)、Assistant(AI助理)和Analyst(妙语分析师),这三款产品在最后会有介绍,它们很大程度上都是基于RAG的能力来实现的。这些基线产品可以直接用,但是相比于更贴近客户需求场景的“应用”,这些基线产品更像是毛坯房。
在RAG下面,DataOS是RAG的数据底座,为RAG提供了数据更新、数据清洗,元数据抽取,文档内容提取等工作。它的数据源当然最主要的还是(租户)手工维护为主,但是依然会提供给租户一个文档库来管理自己的文档;另外一个数据来源就是互联网,适合于对完全公开的公共网站定向fetch。
对于LLM,目前我们采用的要么是本地的baichuan2-13B或QWen-14B,要么就是在线的QWen-72B API。我们目前也在不断测试多个模型的特长,模仿类似Mistral AI的Mixtral-8x7B,为多个不同能力专长的大模型做一个LLM选择和切换。
实践心得
这样的架构可以让我们成员有限的产研团队聚焦在RAG这一线集中发力,而不是东一榔头西一棒槌。TorchV RAG作为一个核心“母”组件,一直保持着每周至少一个迭代的更新频率,目前内部迭代版本v0.5.6,但是迭代路线是清晰的,进度也在正常范围内。三个基线产品和RAG保持了紧密关联,把技术难度(性能、精确率等)留在RAG,把产品能力放在基线产品,把业务逻辑和使用体验放在最终的应用。
2.TorchV RAG的技术选型
我们很早就发现,要做好AI应用似乎对开发者的要求会非常高,非常明显的一点就是仅仅会工程技能(指的是传统的产研,包括CURD、系统框架、高并发、高可用等)是没用的,仅仅会算法(指的是AI算法和数据分析,包括深度学习、统计分析和数学计算等)也是远远不够的。Python是AI业界第一语言没有问题,但是和Java、Go、C++等语言相比,无论是生态、实践和类型等方面,在企业级架构能力上依然偏弱。
RAG底座
TorchV RAG的整体架构或者说底座,是用Java开发的,而上面的组件, 用的很多是Python写的,也包括一些开源组件。
我们没有使用LangChain和LlamaIndex,因为企业应用中有很多复杂的需求,我们必须保证架构原创,才能游刃有余地为后期做优化和修改。当然,这个底座我们也不是完全从零开始,还是源自于之前我们自己开发的一款非常好的产品的架构思路,这个产品我在《总结过去三年的产品心路》里面讲过,从2019年就开始了。
向量数据库
对于向量数据库,我们采用的是elasticsearch,而且用的混合检索,BM25+KNN(实际是ANN,更精确说是HNSW,我在之前的文章《Rerank——RAG中百尺竿头更进一步的神器,从原理到解决方案》里有详细讲解)。另外一方面也是elasticsearch我们在使用上已经有多年的集群使用经验(学费已经交过了),在处理规模扩展上相对新型的向量数据库有更多信心。
其他的技术选型就比较杂了,而且有些是TorchV独有的,比如我前面文章里面说过的幂等分类器、统一输出风格的执行器等等,这里就不再展开。
3:RAG知识目录
近两个月一直有很多朋友加我微信好友,咨询各种关于RAG的问题,其实我觉得大部分内容我都已经在文章里面有提及了。但是因为之前的文章也是想到哪里写到哪里,没有规划,所以大家找起来就比较麻烦了,所以在这里,我做一个目录。
RAG概述
我觉得《大模型主流应用RAG的介绍——从架构到技术细节》应该可以算作是比较全面介绍RAG的文章,对于开始入门的朋友非常适合,可以看到RAG技术的一个大概全貌;
Embedding
如果想深入了解,可以看看这篇关于Embedding讲解的文章《大模型应用中大部分人真正需要去关心的核心——Embedding》,也是一篇阅读过万的文章,对你理解语义、向量相似度等知识有非常大的好处;
需要你认真的Chunking
Chunking可能会是影响大部分人检索精度的第一个拦路虎,因为分块分的不好,检索是不可能好的,特别是把一个完整的句子切断了,或者句子里面有代词“TA”,怎么办?你可以耐心看一下这篇文章《最详细的文本分块(Chunking)方法——可以直接影响基于LLM应用效果》,应该可以帮到你,还有就是NLTK的chunking,值得推荐;
embedding模型微调
embedding模型选择应该也是大家在构建RAG应用时经常会面对的问题,甚至我们会很热衷于试用各种模型,比如Bge-large-zh、Jina、m3e等,当然还有API方式的,像通义千问、OpenAI的text-embedding-ada-002等等。还有一种方式就是对选择的embedding模型基本满意,那么还有一点小问题,我们可以通过微调来解决。可以参考《手工微调embedding模型,让RAG应用检索能力更强》;
内容提取能力
这是另外一个非常影响最后质量的能力,就是我们需要先把文档中的内容提取出来。最简单的当然是文本,但是我们也需要去记录一些元数据(页码、标题、副标题等);然后就是对表格的提取,需要对表格提取的内容设置相应的制表符,有些中文的表哥是非常复杂的,提取表格是toB应用的关键能力之一。另外就是图片上的内容提取,有时候需要采用大量的OCR。嗯,关于这些内容,大家可以看《完全指南——使用python提取PDF中的文本信息(包括表格和图片OCR)》;
本地化部署国产大模型
如果你有私有化部署整套RAG系统,那么就需要去部署国产大模型。之所以选择国产,原因还是这些模型至少有专业团队在用中文数据来做训练,对于中文的理解和处理能力不会差,比如Baichuan2-13B、QWen-14B、ChatGLM3-6B等。对于Llama2,当然也是很优秀的,包括现在的明星产品Mistral,但是这些模型我总感觉在未来的中文能力上是会弱后与前面提到的这几家。
让你,关于国产大模型部署,看《实战!私有化部署RAG,选ChatGLM2-6B还是Baichuan2-13B?》;
Rerank
如果前面提到的问题你都解决了,检索结果还不尽如人意,那么就是要用高阶的方法rerank了。rerank的原因其实来自于我们在第一次接收用户的问题,在成千上万份文档(chunks)中去做检索的时候,为了保证实时性,特意牺牲了很多精度。比如我们只知道全校读书最好的TOP30,但并不知道TOP3是哪几位,以至于我们随机叫三位,极大概率并不是真正的第一名、第二名、第三名。rerank就是在第一次检索后,把TOP30再做一次打分排序,这次我们就知道谁是第一名了。具体的可以看《Rerank——RAG中百尺竿头更进一步的神器,从原理到解决方案》;
RAG如何面对不同类型场景
我们的客户类型很多时候决定了我们的使用场景。比如我们的用户专业性很强,他们讲出来的都是专业术语,那么可能BM25的检索会比相似度会好,这时候就需要将更大的权重放在BM25上。另外,你是否允许在未召回满意的结果时(比如置信度< 0.68,0.68是假设)让大模型兜底作答(很可能会胡说八道),还是说告诉客户该问题根据已知内容无法获悉。
这些都可以通过抽出一些参数来做控制,大家可以看《使用5个参数控制不同场景中RAG检索的准确度》一文,非常简短,更多是一种思路的启发。
其他的一些方法我们也还没用所以就没写,最大的一块应该是基于图关系数据库的。这个后面再看吧,我们至少目前没有碰到什么多跳的问题。
附录1:TorchV三个基线产品简述
简单介绍一下我前面提到的产品,其实大家看图就可以了。
TorchV Bot

TorchV Assistant

TorchV Analyst

结尾
OK,TorchV的RAG实践分享第一篇就写到这里。
Update: 2024-01-26

我们的TorchV Bot产品目前已经开始试用了,详情可以点击:https://www.luxiangdong.com/2024/01/25/lanuch-1
目前只接受企业用户试用,需要您填写一些信息,必要信息如下:
邮箱: 用来接收地址和账号
如何称呼您:
所服务的公司:
您的职位:
当然,如果您可以告诉我们您的使用场景,我们将更加感激!
对了,可以发送到yuanwai@mengjia.net
另外,也可以直接加我微信(lxdhdgss)联系我。

