本文重点:
用弹子球机来展示大语言模型的一些内部原理
如何去调整参数,以达到我们想要的模型输出效果
今年5月份的时候我说国内真正使用过ChatGPT的人不超过5%,但是到了11月份,我再和企业、政府等的一些客户交流时,已经很难再碰到整个交谈过程中不说大语言模型(LLM)的了。但是说实话,大部分人对于LLM的了解还是很“新闻”化的,看到了现象但不达本质,往往造成了对LLM的“神化”。所以今天这篇文章,我希望用相对不那么技术化的描述来讲讲LLM的一些原理和概念,让大家对LLM有更近一步了解,也许对大家后面使用LLM及其应用有一定的帮助。
首先做个说明:本文不会讲太多数学公式,我会尽量保证非数学、统计专业的朋友可以看懂。
弹子球机
今年2月份我写过一篇关于GPT的文章《ChatGPT会给文旅行业带来什么改变》,里面提了一下ChatGPT的原理,如下图所示。
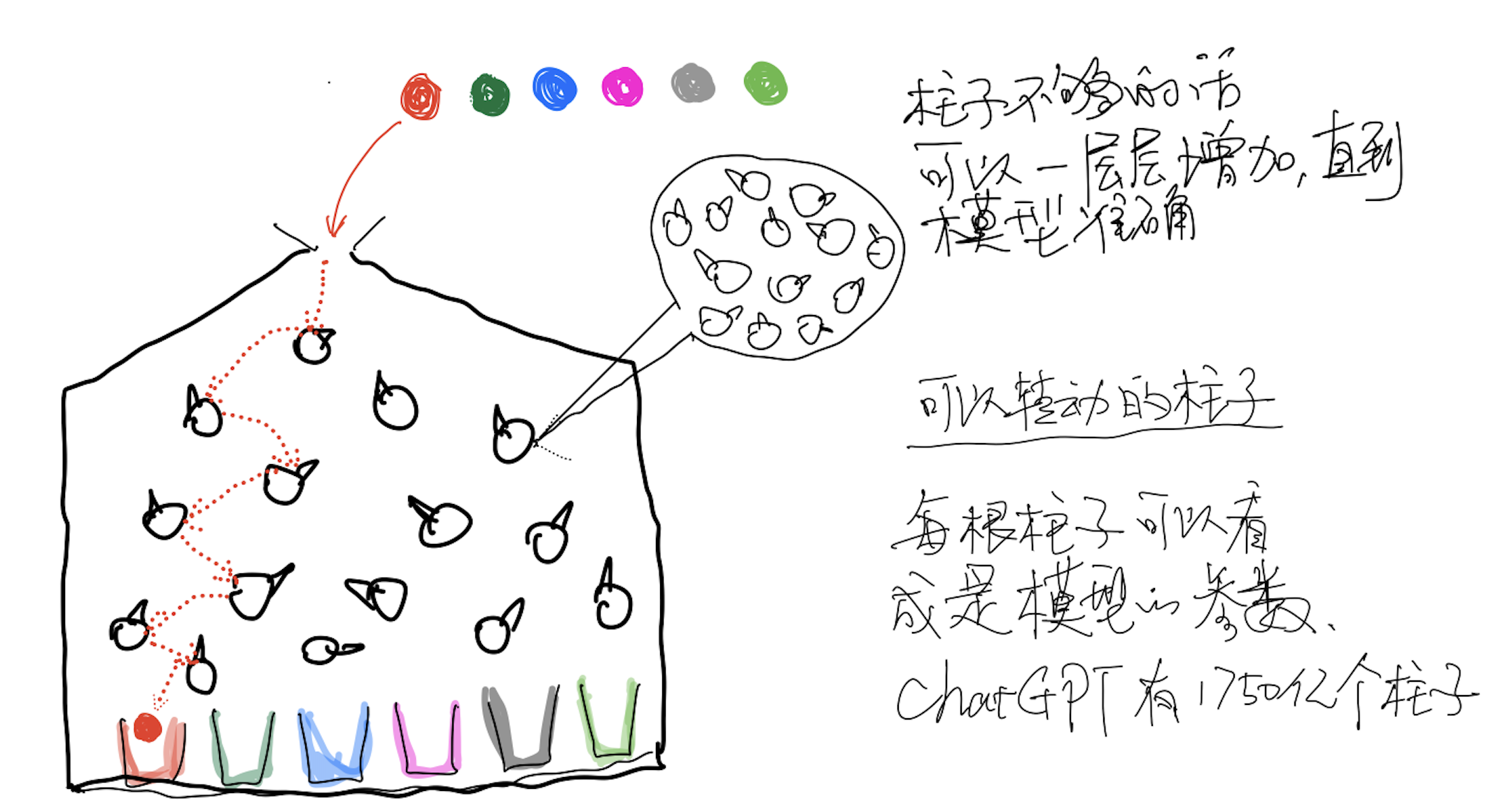
当时说的是假设我们有一个弹子球机器,把各种不同(颜色、重量、尺寸)的球从顶部扔进去,球会和里面的这些柱子(杯子上方的这些圈圈)相碰撞,最终掉下来,落进最下面的杯子里。我们期望机器可以做到”红色的球最终掉进红色的杯子,蓝色球掉进蓝色杯子,依次类推“,我们可以做的事情是调整机器里面的柱子(假设这些柱子表面是不规则的,而且我们可以旋转这些柱子)。
如果我们一次次进行试验,然后不断去调整里面的柱子,是可以达到一个比较理想的状态的。需要注意的是,这里我们采用计算机来做试验,所以如果试验100次不够,那就1亿次,如果柱子的层数不够而引起达不到理想的状态,那么我们可以不断增加柱子,就像图里面,每个柱子其实又可以细化成无数的柱子。最终让红球落到红杯子,蓝球落到蓝杯子,…… 。这时候,这些所有的柱子的状态,就形成了一个模型,这个模型的作用就是按颜色分球。
您现在应该可以知道,这些柱子就是参数,现在的大模型基本上最简单的也有60亿个参数,ChatGPT3.5据说是1750亿个参数。那么在计算机是怎么来创建参数的呢?
所以今天我们就用这个弹子球机来比喻一下,看看LLM的内部是怎么样的,特别是我们所谓的“参数”、“微调”、“损失函数”和“梯度下降”是什么意思。
参数和感知机
要说清楚计算机里面的柱子(参数)是怎么构建的,我们需要先认识一下感知机。
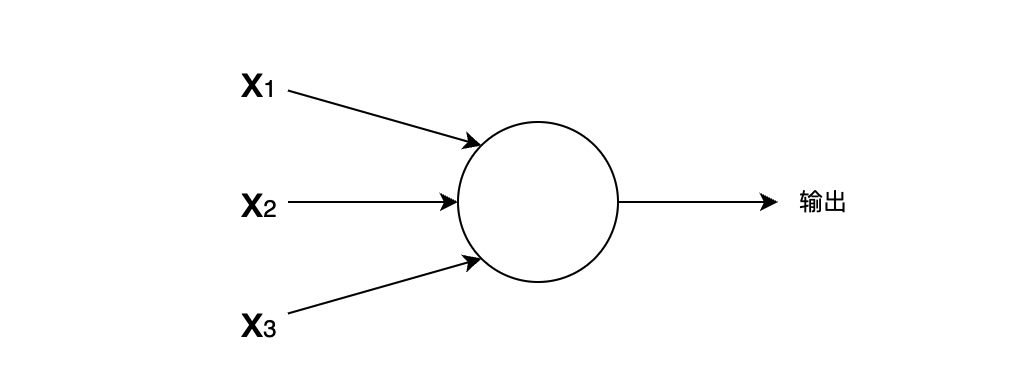
感知机的作用:接收三个输入条件x1、x2、x3,然后输出一个结果。这么说可能有点难理解,我们讲的例子。我们可以将感知机当做一个根据权重来做决策的机器,以周末是否去外面野餐为例,我们有可能有三个影响因素:
天气情况?
你的家人是否想去?
附近是否可以方便地停车?

但各个因素的重要性不同,如果下雨,那野餐的几率为零。
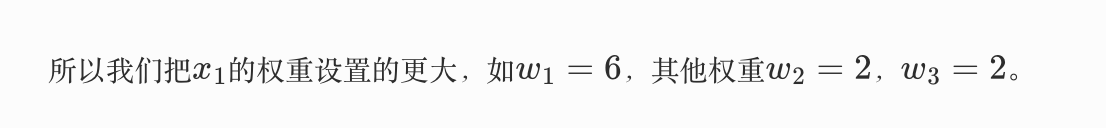
如果我们给这个感知机的阈值设置为5(最终的结果>5就出行),那么只要天气情况好,那最终输出就是6 (= 16 ),> 5,去野餐。这里,*三个x的权重和最终的阈值就是所谓的参数!!!
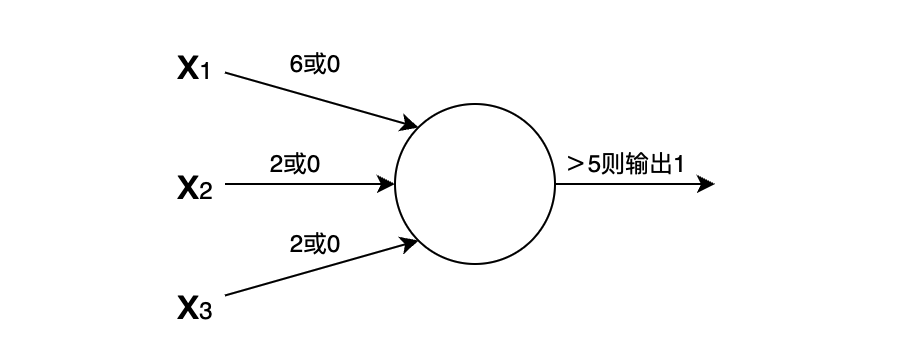
当时上面的例子里面,只要X1条件满足就去野餐了,好像其他两个条件就成了摆设。当然你可以把阈值设置的大于6(比如是7),那就可以让x2、x3也能发挥价值。但是一般情况下不太会把所有权重都放在一个感知机里面,而是会把多个感知机组合起来,实用的神经网络都具备很多层,如下面这个图所示:
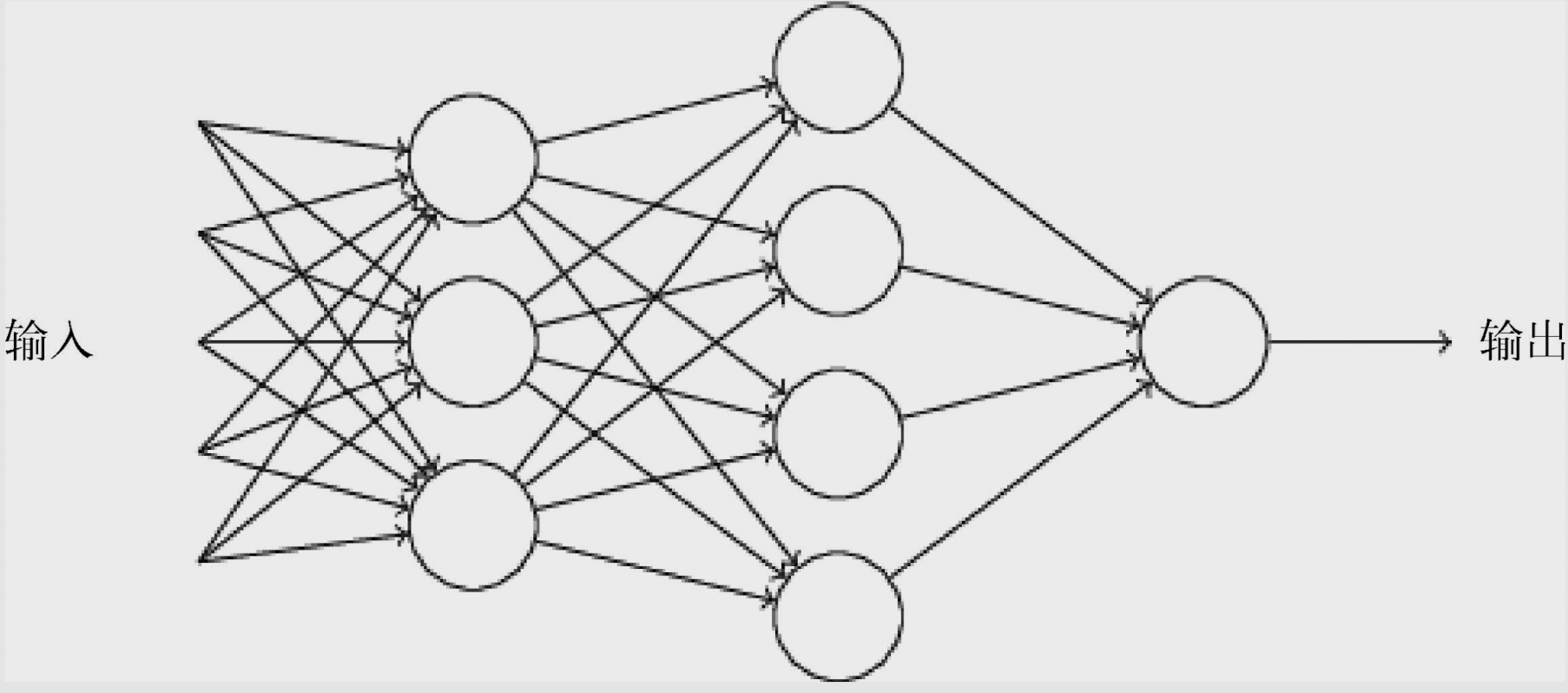
我们刚才做出来的野餐出行决定仅仅是其中一个人工神经元,将这个结果传递给下一层的神经元(上一层的输出结果作为下一层的输入因子)进行更复杂的判定。需要注意的是一个神经元的输出只有一个,上图其实一个神经元有多个箭头输出只是说明同一个输出可以被下一层的多个神经元接收作为输入因素。
哦,对了,有些参数还可以设置偏置值,就像最上面说的家人是否想去的因素x2的权重是2,也就是说家人想去,那么输出值可以是
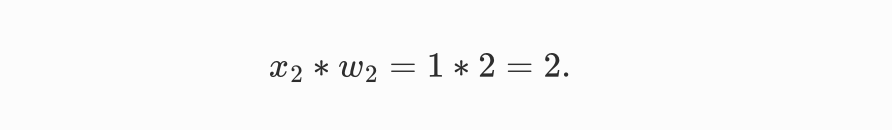
现在我们觉得家人是最重要的,只要家人想去,那么就算是下雨也可以去搭天幕野餐。这个时候,我们就可以给x2加一个偏置值,如b2=4,那这时候,输出值就等于6,>5直接出行。
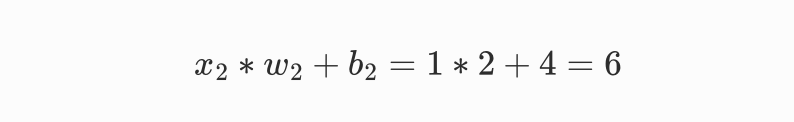
为了不太过多陷入技术细节的讲述,我们不再继续讲述Sigmoid神经元、多层神经网络(MLP)等概念了,因为我们已经大致知道了计算机是如何构建参数的。
损失函数
这一段不枯燥,我觉得大家可以耐心看
其实我们要做的事情是要让机器能自动帮我们找到权重和偏置值(w、b),使得神经网络输出的结果y(x)能够拟合(匹配)各种情况。这里就需要展现著名的损失(loss)函数了,有些地方也叫代价函数。
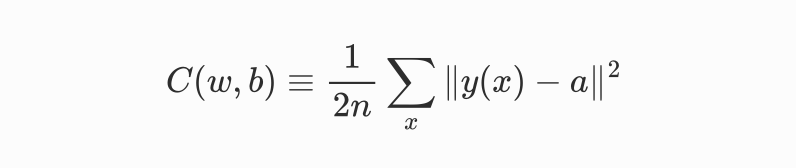
其中 w 表示神经网络中所有权重的集合,b是所有偏置,n是训练输入的数量,a表示输入为x时输出的向量,求和则是对所有训练输入  x进行的。当然,输出a 取决于 x、w和b,但是为了保持符号简洁,没有明确指出这种依赖关系。||v|| 是向量 v 的长度函数。我们把c 称为二次代价函数,也称均方误差(MSE)。观察二次代价函数的形式,可知 C(w,b)非负,这是因为求和方程中的每一项都是非负的。此外,确切地说,当对于所有训练输入x,y(x)近似等于输出a时,代价函数C(w,b)的值相当小,即C(w,b) ≈ 0。因此,如果学习算法能找到合适的权重(w)和偏置(b),使得C(w,b) ≈ 0,它就能很好地工作;相反,当C(w,b)很大时就不怎么好了,那意味着对于大量的输入,y(x)与输出a相差很大。因此,训练算法的目的是最小化代价函数C(w,b)。
回到弹子球机的案例:n等于是一次又一次的放球实验(的记录),x表示球的颜色(比如放进红球),a表示结果(掉进红杯子)。这时候,我们不断地在每次放球实验之后去调整柱子(w,b),又需要去考虑这次的调整不会影响其他的实验结果(比如红球可以了,之前已经调整过的蓝球却不行了)。
那么我们怎么样找到一个最合理的结果呢?这就需要通过梯度下降算法来实现。
梯度下降
如果您之前并不是专业从事深度学习算法工作的,那么在损失函数和梯度下降这两节不太看得懂是很正常的,因为在人工智能中,很多获得图灵奖的大牛可能穷其大半辈子也就是发明了一个算法,或者证明了某算法在某应用中是有效的。所以您开始的时候很难理解这些概念是很容易理解的。
好了,在上一节我们已经把调整弹子球机的方法用数学方式表达出来了,接下来我们需要继续用数学来求解这个函数。
说个题外话,不知道你对数学的喜好程度如何,说真的作为半个数学系专业(信息与计算科学)的毕业生,我对数学没有感情…但是我确实知道它有多重要,所以我很早就开始引导我儿子“爱上”数学。另外,这次OpenAI宫斗中董事会指责Sam Altman对董事会有所隐瞒,指的就是内部的新模型Q* (可以读:Q星)。据说Q* 模型会威胁人类,原因就是它懂数学,这可比懂文学、历史和其他学科要恐怖的多,所以这也说明了,数学真的是很重要。
好了,说回梯度下降算法,我们可以先制造一个梯度,大家先看一下。
grad_demo.py
1 |
|
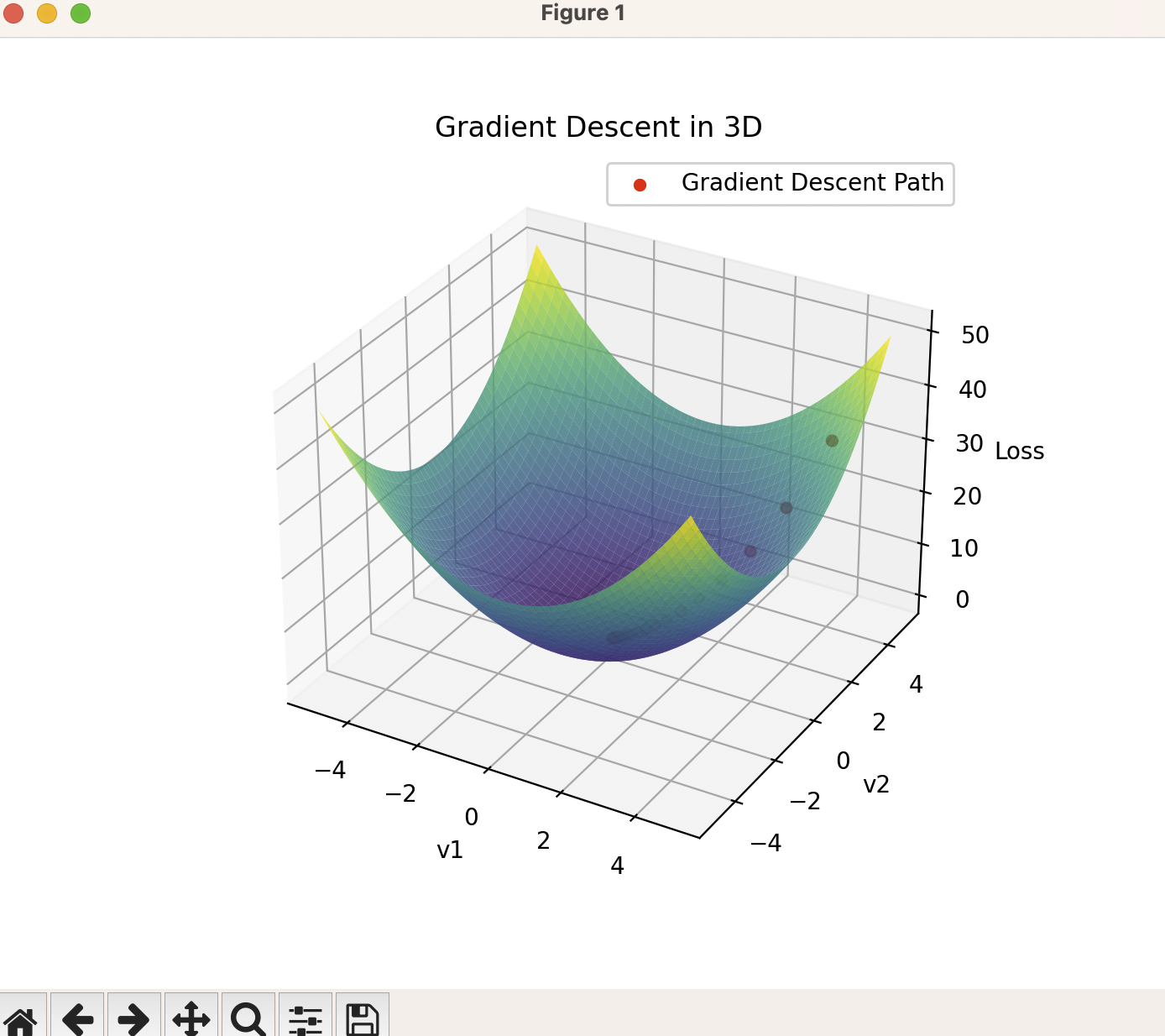
如果你在自己的机器上运行grad_demo.py,那么可以看到下面这个图,简单来说,我们要做的事情就是找到这个模型C(w,b)的最低点,我们可以狭义地认为最低点就是代表着损失函数最小,这时候w 和 b的参数调整状态可以让目前的模型输出y(x)与我们的预期最接近,也就是把我们的弹子球机的柱子调整好了。
这一段是数学推导,有兴趣可以看,不然可以直接回到人间。
那么如何用数学(或者说让计算机)来找到这个最小解呢?
我们先用真实世界的方式来思考:最直观的方式就是用一个小球在模型(曲面)上随机找一个点,让小球在重力影响下沿着曲面滚下来,小球最终会停在一个最低点,我们可以认为这就是最低点(最小值)。如果用微积分的角度去考虑,那么我们可以认为小球先动一点点,

小球的运动轨迹会发生变化,如果用微积分表示整个模型现在的状态,可以是:
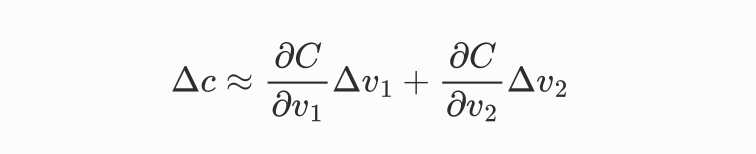
当然,考虑到可循环计算,可以把焦点放在C(w,b)的梯度向量上,上面的公式可以转化为:
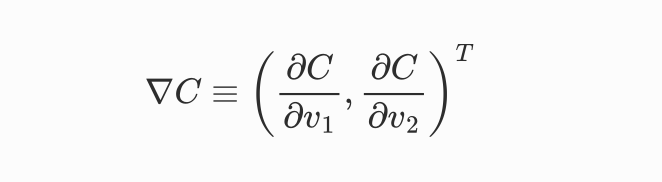
回到人间
提到这些数学公式是很无聊的,我相信大多数朋友也许不喜欢看,其实咱们确实也不需要太多关心这些数学公式。而且在实际的大模型训练过程中,公式基本上都是改良过的,可不是我上面写的这么简单,所以我在这里也不想深入去推导了。我需要知道的就是用微分偏导数计算的目的是为了找到这个模型的全局最小值,也就是小球滚到曲面(模型)的最低点。
当然,证明是不是全局最小值也是一件需要非常小心的事情,就像上面看到的这座山谷,如果半山腰有个大水塘,那么小球也可以直接滚进去就出不来了,系统误以为这就是整个模型的(全局)最小值了….所以,在实际的业务中,改良算法会复杂得多,比如加上随机梯度下降等。再说,有时候好像也需要一点点运气,这种半山腰的大水塘(局部最小值)会让模型训练卡住,浪费大量算力。所以OpenAI首席科学家Ilya Sutskever(是的,就是参与宫斗的这位仁兄),在2018年的新年贺词是:“愿你所有的局部最小值都是全局的,你的方差有界,你的标记数据丰富,你的计算量巨大!”可见他们对于全局最小值的寻找也是非常敬畏的(启动训练程序前可能需要烧香…)。
结合真实LLM来讲
以上内容我更多还是针对这个弹子球机来讲,比较袖珍吧,但是便于大家理解概念——如何才能不断去旋转这些柱子,让红球掉进红杯子、蓝球掉进蓝杯子….
下面我们结合真实的LLM简单讲一下。
LLM就非常庞大了,我们先不去说全量训练吧,仅仅说微调。微调的过程我们可以理解为:现在要在弹子球机里面再加一个颜色的球和杯子,如何调整?为了使用上面说的这些策略进行微调,你不仅需要足够的内存(其实准确说是显存)来存储整个模型,还需要足够的内存来存储整个模型中每个参数的梯度(梯度是让模型知道调整参数的优化方向的东西)。参数和梯度都需要驻留在GPU上,这就是为什么训练大语言模型需要如此多的GPU内存。
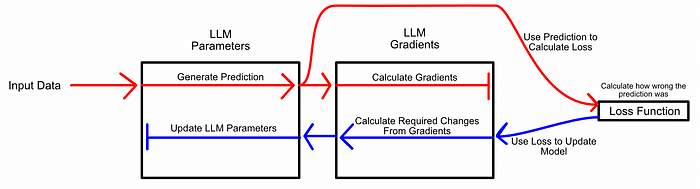
这是一个反向传播的示意图,用于训练机器学习模型的策略。这里使用的也是梯度下降,某个参数的微小变化就会影响整个模型输出。我们生成一个预测(Prediction),计算梯度,计算预测的错误程度,然后使用梯度来改进模型的参数。预训练和微调都采用反向传播,这需要计算模型中每个可学习参数的梯度。
这种情况下,如果我们有一个1000亿参数的模型,我们就需要存储1000亿个梯度。为了训练一个模型,我们还需要循环计算和调整(参数)至少几十亿次。
在存储梯度的问题之上,通常保存“检查点”(checkpoints),这是在整个训练过程中处于特定状态的模型副本。这是一个很好的策略,允许在微调过程的不同阶段对模型进行实验,但这意味着我们需要存储许多模型的全尺寸副本。我之前介绍过Falcon-180B,(见文章《不开玩笑,1800亿参数的Falcon大模型可以在家用电脑上部署了》),它就需要大约360GB的存储空间。如果我们想在整个微调过程中存储模型的检查点10次,它将消耗3.6 tb的存储空间,这是一个很大的容量。也许更重要的是,保存如此大量的数据需要时间。数据通常需要从GPU出来,进入RAM,然后存储,可能会大大延迟微调过程。
本来今天我想把后面的LoRA内容也一起写掉的,但是发现写这样的文章非常烧脑,因为我需要用大多数人耐心看就可以看得懂的语言来描述这些本来就很难的逻辑,脑力消耗很严重,所以LoRA的就下次再写吧。
为了浅显易懂,过滤了一些知识点,所以文章肯定有很多不足之处,还请大家及时指正和多多包涵..,写作不易,如果可以,也请您帮忙点赞、关注和分享哦!

