最近一直和小明在搞RAG,我们认为这对于大部分公司和个人来说,就是大模型的未来,有应用才能更好推动大模型发展,至少近三年内应该是。前面也输出了一些RAG方面的文章,也有了一套精确度相对较高的技术产品。但是你知道的,RAG领域也在不断发展,而且我们确实也还面临着一些实际的问题,所以最近开始细细研究LlamaIndex——我觉得适用于RAG领域的话,可能会比LangChain更优秀。今天我们先来看看LlamaIndex的索引。
什么是LlamaIndex
这是我自己列的一个结构图,当然是按我自己的理解画的,您只做参考吧,哈哈。
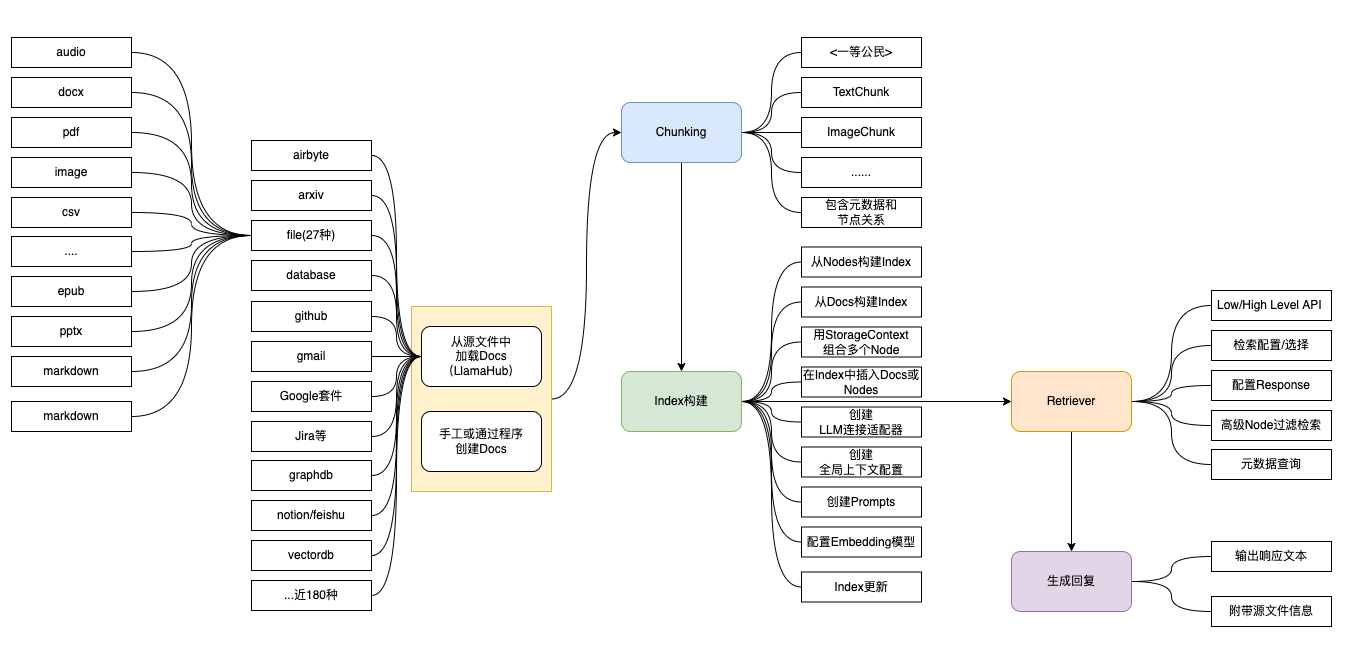
LlamaIndex是一个大型语言模型(大语言模型)的数据框架,提供以下工具:
- 数据摄取: LlamaIndex提供数据连接器来摄取您现有的数据源和数据格式(api, pdf,文档,SQL等),以便您可以与大语言模型一起使用它们。
- 数据构建: LlamaIndex提供了构建数据(索引,图表)的方法,以便可以轻松地与大语言模型一起使用。
- 检索和查询接口: LlamaIndex为您的数据提供了高级检索/查询接口。您可以输入任何LLM输入prompt,LlamaIndex将返回检索到的上下文和知识增强的输出。
- 与其他框架集成: LlamaIndex允许轻松集成与您的外部应用程序框架(例如与LangChain, Flask, Docker, ChatGPT,或其他任何)。
LlamaIndex是为初学者和高级用户设计的。高级API允许初学者使用LlamaIndex在5行代码中摄取和查询他们的数据。低级api允许高级用户自定义和扩展任何模块(数据连接器、索引、检索器、查询引擎、重新排序模块),以满足他们的需求。
以下是使用LlamaIndex的一些好处:
- 易于使用: LlamaIndex有一个简单直观的API,使其易于入门。
- 灵活: LlamaIndex可用于摄取和查询各种数据源和格式。
- 功能强大: LlamaIndex提供了广泛的功能,帮助您构建强大的LLM应用程序。
- 可扩展: LlamaIndex是开源和可扩展的,因此您可以自定义它以适应您的特定需求。
什么是index
LlamaIndex中的索引是一种数据结构,它允许您从大量文本语料库中快速搜索和检索数据。它的工作原理是在语料库中的关键字或短语与包含这些关键字或短语的文档之间创建映射。这种映射允许您快速找到包含特定关键字或短语的所有文档,即使语料库非常大。
索引对于各种任务都很有用,例如:
- 搜索信息:您可以使用索引快速找到包含特定关键字或短语的所有文档。这对于研究、客户支持或任何其他需要在大量文本语料库中查找信息的任务都很有用。
- 排序文档:您可以使用索引根据文档与特定查询的相关性对文档进行排序。这对于搜索引擎、推荐系统或任何其他需要对文档进行排序的应用程序都很有用。
- 分析文本:您可以使用索引来分析大量文本的内容。这对于理解文档的情感、识别主题或提取关键字非常有用。
LlamaIndex提供了各种不同的索引类型,每种类型都有自己的优缺点。特定任务的最佳索引类型将取决于任务的特定需求。
Llamaindex提供的结构或组织数据的索引类型:
让我们先了解一些术语。根据Llamaindex的官方文件:
- Node:对应于文档中的一大块文本。LlamaIndex接受Document对象,并在内部将它们解析/块化为Node对象。
- Response Synthesis:你可以认为是一个放置你选择Node的购物车,它会完成合成,然后处理后续的响应。
为了便于理解,我们可以将节点视为大约1k个单词的文本块,而响应合成则是通过查看相关节点(文本块)来给出问题答案(响应)的LLM。这里大家也可以回看我之前的文章《最详细的文本分块(Chunking)方法,直接影响LLM应用效果》。
Llamaindex提供不同类型的索引,以便更好地组织和检索相关信息,并使用Embeddings和LLM高效地运行查询。我们将逐一查看主要Index:
List Index :
List Index是一个简单的数据结构,它将文档存储为节点序列。在索引构建期间,文档文本被分块、转换为节点并存储在一个列表中。这使得它成为检索包含特定关键字或短语的文档的非常有效的索引。
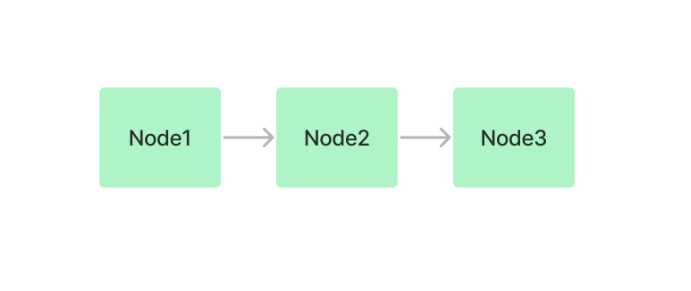
使用列表索引的优点
- 效率:列表索引对于检索包含特定关键字或短语的文档非常有效,这是因为它只需要扫描节点列表来查找与查询匹配的文档。
- 简单:列表索引是非常简单的实现和使用,对于性能很重要,但开发时间有限的项目来说,这是一个很好的选择。
- 灵活性:列表索引可用于任何类型的文档数据,这使得它成为具有各种文档格式的项目的一个很好的选择。
在查询的过程中发生了什么?
在查询期间,如果没有指定其他查询参数,LlamaIndex只是将列表中的所有节点加载到响应合成模块中。
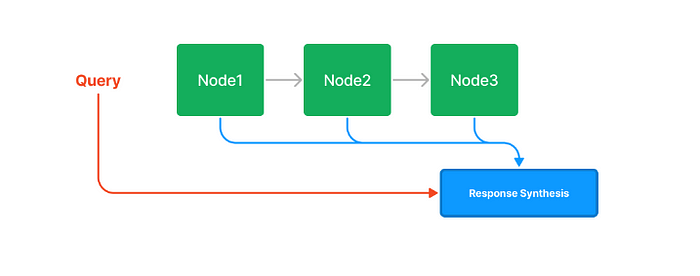
当用户输入关键字或短语时,查询列表索引。然后,索引扫描节点列表以查找包含关键字或短语的文档。然后将匹配查询的文档返回给响应合成模块:
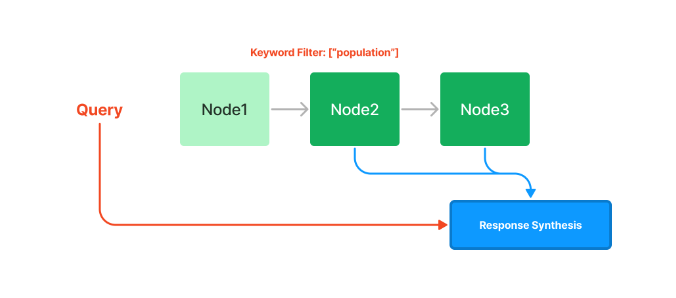
使用List Index的缺点或问题:
- 可伸缩性:对于大型数据集,List Index可能会变得低效,这是因为它需要扫描整个节点列表来查找与查询匹配的文档。
向量存储索引
向量索引是一种将文档文本转化为向量的索引,向量通常是由编码器transformer模型(如Bert等)生成的,它们也被称为Embeddings模型(参考前面关于embedding的文章《Embedding——从入门到生产使用》)。向量表示文本的含义,可以根据用户的查询来查找相关文档。
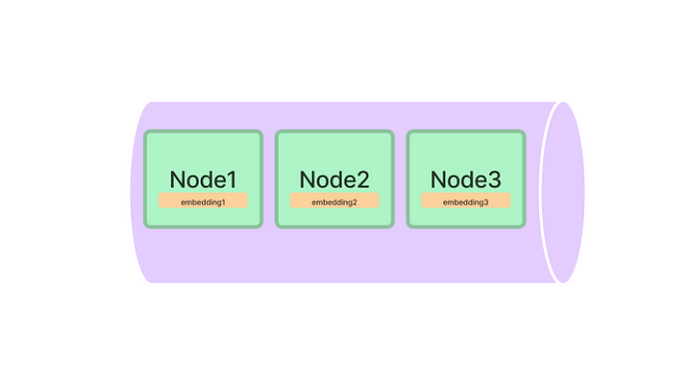
使用LlamaIndex来创建向量Index是非常简单,可以从文档中直接提取文本建立索引,可以看下面这段代码:
1 | from llama_index import Document, VectorStoreIndex |
或者我们也可以从先生成Node,才建立索引,我推荐这种方式,因为后面更好管理:
1 | from llama_index import Document, VectorStoreIndex |
使用向量索引的优点:
- 向量索引对于查找类似文档非常有效。这是因为向量可以直接进行比较,而无需进行任何文本处理。
- 向量索引扩展相对容易,它们可以用于索引包含数百万甚至数十亿个文档的大型数据集。
- 向量索引创建相对容易,拥有Embedding模型(中文常用的包括m3e、bge等)之后,就可以为文档生成向量,并将它们存储在向量索引中。
我们看看向量索引在查询的时候发生了什么:
- 当您查询向量索引时,您提供一个查询字符串。查询字符串首先由相同的Embedding模型处理以生成向量。
- 然后将向量与索引中所有文档的向量进行匹配,具有最相似(可以设置top_k)向量的文档将作为查询的结果返回。
- 我们还可以定义返回top-k最相似的节点,并将它们传递到我们的响应合成模块。
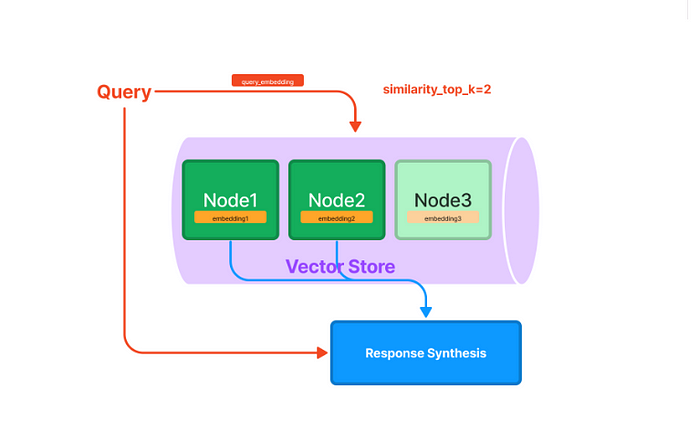
总的来说,向量索引与传统查询的索引相比,更具备语义属性,可以让我们根据语义来检索,而不仅仅是按关键词匹配等字面意思来搜索。而且向量索引使用高效、可扩展能力强,且易于创建。当然了,它也有不好的一方面,就是如果您使用的不是本地embedding模型,而是使用OpenAI的text-embedding-ada-003、通义千问的embedding模型等,那么是需要成本的,而且量大的话可能很昂贵,即使使用免费的BGE、m3e等本地模型,也是需要一些硬件资源的。对了,说一点开心的,本地的embedding模型的话,我们自己是可以微调训练的,可以参考我之前的文章《手工微调embedding模型》。
TREe Index(树索引)
Tree Index也是一种索引类型,它将文档的文本存储在树状结构中。树中的每个节点表示其子文档的摘要。我相信看这篇文章的朋友应该多少都接触过树的数据结构,通过遍历树并查找与查询相关的节点,树索引可用于查找与给定查询相关的文档。
为什么用树?我们通过和数组、链表的比较,使用大学知识简单复习一下树的优点:
数组:支持随机访问,进过排序的数组在查找的时候效率极高——O(1),但是数组的insert、delete等操作需要变动后续的所有元素,复杂度就会变大——O(n);
链表:和数组相反,链表的插入删除等效率极高,只需要将前后连接点打断,插入,再接好,所以时间复杂度一般是O(1)。但是它的查询速度就慢了,需要全部遍历才能找到相应元素,一般时间复杂度是O(n)。当然,链接有很多变种,比如散列链表的查询复杂度也是可以做到O(1)的;
树:树结构算是一个折中吧,特别是二叉树,它的查询和操作(插入、删除等)的复杂度都是O(logn)。二分法的威力就是n越大,它的上升曲线会越来越平缓。比如一组有序数字的猜大小的游戏中,8个数字(n=8),只要猜3次;32个数字猜5次,但是1024个数字也只需要10次。且很关键的一点,二叉树的效率非常稳定,这一点在开发中对于性能的可预估性非常重要。
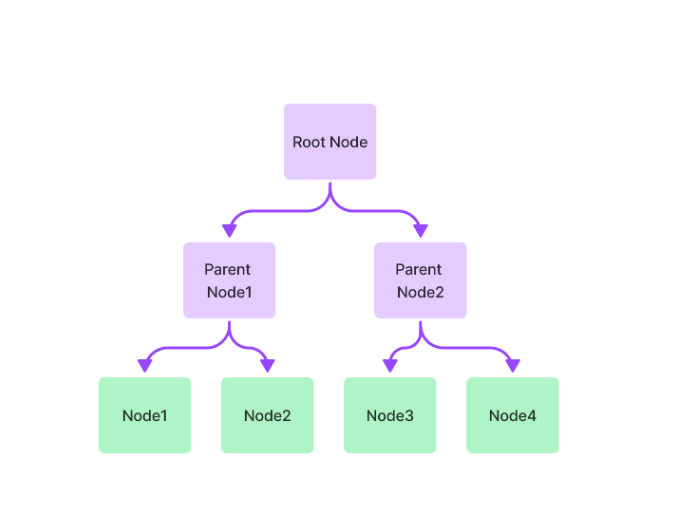
使用树索引的优点:
- 树索引对于查找相关文档非常有效,这是因为树结构允许索引快速地将搜索范围缩小到可能与查询相关的少量文档。
- 树索引也非常可扩展,它们可以用于索引包含数百万甚至数十亿个文档的大型数据集,不管数据量大小,性能相对稳定。
- 树索引相对容易创建,一旦有了文档,就可以通过手动或自动将文档分组到相关的集群中来创建树形结构。
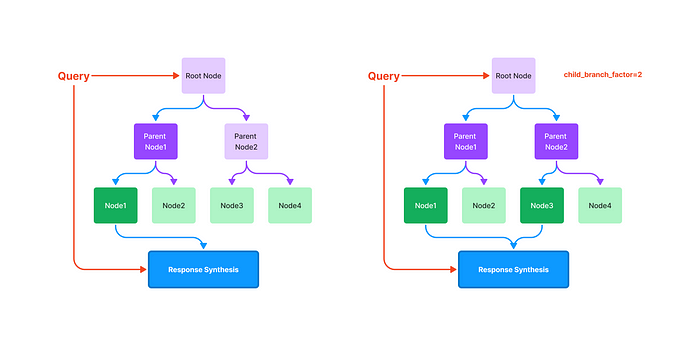
在查询过程中发生了什么?
- 查询树索引时,需要提供查询字符串。首先处理查询字符串以识别与查询相关的关键字。
- 然后索引遍历树,从根节点开始(也可以是其他地方开始)。在每个节点上,索引检查查询中的关键字是否出现在节点的摘要中。如果是,则索引下降到节点的子节点。如果不是,则索引移动到下一个节点。
- 这个过程一直持续到索引到达一个叶子节点,或者直到它耗尽树中的所有节点。到达的叶节点是最有可能与查询相关的文档。
- 根据原始文档:查询树索引需要从根节点向下遍历到叶节点。默认情况下,(
child_branch_factor=1),查询在给定父节点的情况下选择一个子节点。如果child_branch_factor=2,查询将在每个级别选择两个子节点。
使用树索引的缺点:
- 树索引可能比其他类型的索引(如向量索引)更难创建。这是因为需要手动或自动地将文档分组到相关的集群中。
- 树索引在查找与查询“无关”的文档时效率较低(也就是空转的效率较低)。这是因为索引需要遍历整个树,即使查询只与少量文档相关。
- 树索引可能比其他类型的索引更难理解。这是因为树形结构不是人类可以直接解释的。
总的来说,树索引是索引和查询大型文本数据集的强大工具。它们对于查找相关文档非常有效,可伸缩,并且相对容易创建。但是,它们比其他类型的索引更难创建,并且在空转查询时效率较低。
关键词表索引
关键字表索引是一种将文档的关键字存储在表中的索引,我觉得这更加类似Map<k,v>或者字典的结构。表中的每一行代表一个关键字,每一列代表一个文档。通过在表中查找关键字,可以使用表索引来查找包含给定关键字的文档。
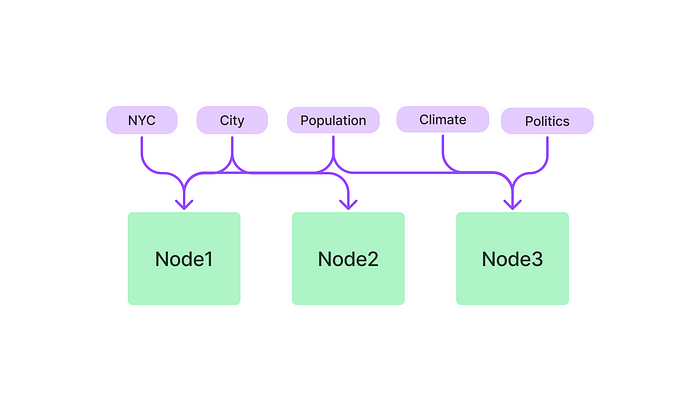
使用关键字表索引的优点:
- 关键字表索引对于查找包含特定关键字的文档非常有效,这是因为索引可以快速查找表中的关键字,并找到包含该关键字的所有文档。
- 关键字表索引也非常可扩展,它们可以用于索引包含数百万甚至数十亿个文档的大型数据集。
- 关键字表索引相对容易创建,一旦有了文档,就可以从文档中提取关键字并将其存储在关键字表中。
看看查询的过程:
- 查询关键字表索引时,需要提供关键字。然后索引在表中查找关键字并返回包含该关键字的所有文档。
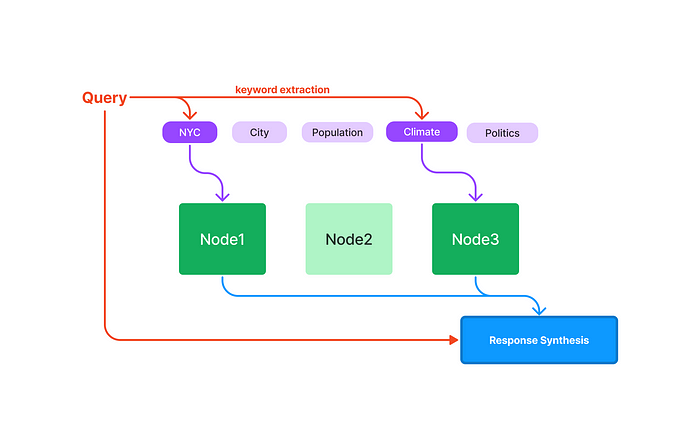
使用关键字Index的缺点或问题:
- 关键字表索引在查找包含多个关键字的文档时效率较低,这是因为索引需要单独查找表中的每个关键字。
- 关键字表索引对于具有大量关键字的文档可扩展性较差,这是因为表需要更大才能存储所有文档的关键字。
- 对于同义词或相关关键字的文档,关键字表索引可能不太准确,这是因为索引将只返回包含所查询的确切关键字的文档。
总的来说,关键字表索引是索引和查询大型文本数据集的强大工具。它们对于查找包含特定关键字、可伸缩且相对容易创建的文档非常有效。但是,它们在查找包含多个关键字的文档时效率较低,在查找包含大量关键字的文档时可伸缩性较差,在查找包含同义词或相关关键字的文档时准确性较差。
总结
我们讨论了5种类型的索引,它们如何存储数据,在查询时如何工作,以及每种索引的优缺点。因此,您可以根据自己的要求和约束条件选择最适合的Index。有一些高级类型的索引,如知识图谱索引等,后面再单独讲,需要结合知识图谱本身的一些概念。
对LlamaIndex的研究是因为它确实很优秀,很多理念也给了我们极大启发。就像小明说的,他想好好学习LlamaIndex,然后用Java也写一个简化版,因为他要拯救广大面对AI大浪而处于彷徨中的Java程序员,哈哈。
引用
1.Different types of indexes in LlamaIndex to improve your RAG system:https://uttu-parashar.medium.com/different-types-of-indexes-in-llamaindex-to-improve-your-rag-system-fa9c49f40559
2.LlamaIndex官方文档:https://docs.llamaindex.ai/en/stable/core_modules/data_modules/documents_and_nodes/root.html

