原文:What Are Transformer Models and How Do They Work?
Transformer模型是机器学习中最令人兴奋的新发展之一。它们在论文Attention is All You Need中被介绍。Transformer可以用于写故事、文章、诗歌,回答问题,翻译语言,与人类聊天,甚至可以通过对人类来说很难的考试!但是它们到底是什么呢?你会很高兴地知道,Transformer模型的架构并不复杂,它只是一些非常有用组件的串联,并且每个组件都有自己的功能。在本篇文章中,您将了解所有这些组件。
此博客文章包含简单概念性介绍。关于Transformer模型及其工作原理更详细描述,请查看Cohere公司Jay Alammar撰写的这两篇优秀文章!
简而言之,Transformer的作用是什么?想象一下你在手机上写短信。每输入一个单词后,你可能会得到三个建议的单词。例如,如果你输入“Hello, how are”,手机可能会建议下一个单词为“you”或“your”。当然,如果你继续选择手机中的建议单词,很快就会发现这些单词组成的信息毫无意义。如果你看每一组连续的3或4个单词,则它们可能有意义,但这些单词并不构成任何有意义的句子。这是因为手机使用的模型没有携带消息整体上下文,只是预测最近几个字后更可能出现哪个字。相反地,“Transformer”可以跟踪所编写内容背景,并且这就是它们编写文本使其具有意义之处所在。

手机可以建议在短信中使用下一个单词,但没有生成连贯文本的能力。
我必须对你诚实,第一次发现Transformer逐字建立文本时,我简直不敢相信。首先,这不是人类构成句子和思想的方式。我们首先形成一个基本思想,然后开始完善它并添加单词。这也不是ML模型完成其他任务的方式。例如,图像不是以这种方式构建的。大多数基于神经网络的图形模型会形成图像的粗略版本,并逐渐完善或添加细节直到完美为止。那么为什么Transformer模型要逐字构建文本呢?一个答案是因为这样做非常有效。更令人满意的答案是因为Transformer非常擅长跟踪上下文,所以它选择下一个单词时恰好符合保持某个想法进行所需。
那么Transformer如何训练呢?使用了大量数据,事实上包括互联网上所有数据。因此当您将“你好吗”输入到转换器中时,它只需要根据互联网上所有文本知道最佳下一个单词就是“你”。如果您给出更复杂的命令,则可能会确定使用良好的下一个单词,“曾经”。然后它将该单词添加到命令中,并确定下一个好单词是“在……之上”,以此类推。逐字逐句,直到它写出一篇故事为止。
命令:Write a story.
回应:Once
下一条命令:Write a story. Once
回应:upon
下一条命令:Write a story. Once upon
回应:a
下一条命令:Write a story. Once upon a
回应:time
下一条命令: Write a story. Once upon a time
回复: there
等等…
现在我们知道了transformers的作用,让我们来看一下它们的架构。如果你已经看过transformer模型的架构,你可能会像我第一次看到时那样惊叹不已,因为它看起来非常复杂!然而,当你将其分解成最重要的部分时,就没有那么难了。Transformer有4个主要部分:
- 分词
- 嵌入
- 位置编码
- Transformer块(其中包含多个)
- Softmax
其中第四个——Transformer块是最复杂的。可以连接多个这样的块,并且每一个都包含两个主要组件:Attention(注意力)和Feedforward(前馈)组件。
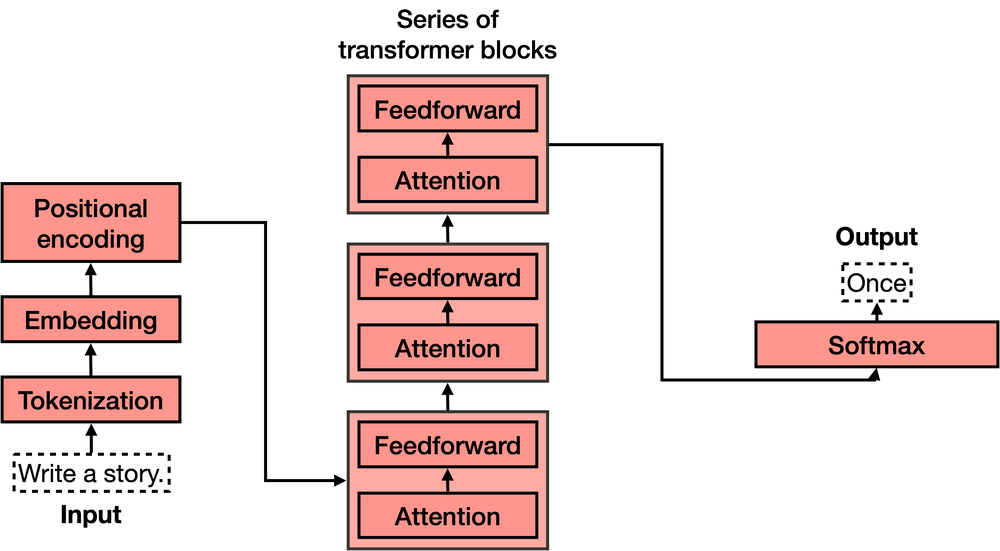
让我们逐个学习这些部分。
Tokenization
Tokenization (分词)是最基本的步骤。它包括一个大型的标记数据集,其中包含所有单词、标点符号等。分词步骤将每个单词、前缀、后缀和标点符号都发送到库中已知的Token。

例如,如果句子是“Write a story.”,那么对应的4个token将是
Embedding
一旦输入内容被tokenized,就该将单词转换成数字了。为此,我们使用embedding(嵌入)。Embedding是任何大型语言模型中最重要的部分之一;它是实现文本与数字转换的桥梁。由于人类善于处理文本而计算机善于处理数字,因此这个桥梁越强大,语言模型就越强大。
简而言之,文本嵌入将每个文本转换为一个向量。如果两个文本片段相似,则其对应向量中的数字也相似(逐位意味着同一位置上的每对数字都相似)。否则,如果两个文本片段不同,则其对应向量中的数字也不同。如果您想了解更多信息,请查看有关文本嵌入的文章和视频。
尽管嵌入是数值化的,但我喜欢从几何角度来想象它们。试想一下存在一个非常简单的嵌入方式,可以将每个单词映射到长度为2(即包含2个数值) 的向量上。如果我们按照这两个数值所表示坐标定位每个单词(比如在街道和大道上),那么所有单词都站在一个巨大平面上。在这张平面上,相似的单词会靠近彼此,而不同的单词则会远离。例如,在下面这个嵌入中,“cherry”的坐标是[6,4],与“strawberry” [5,4] 接近但与“castle” [1,2] 相距较远。
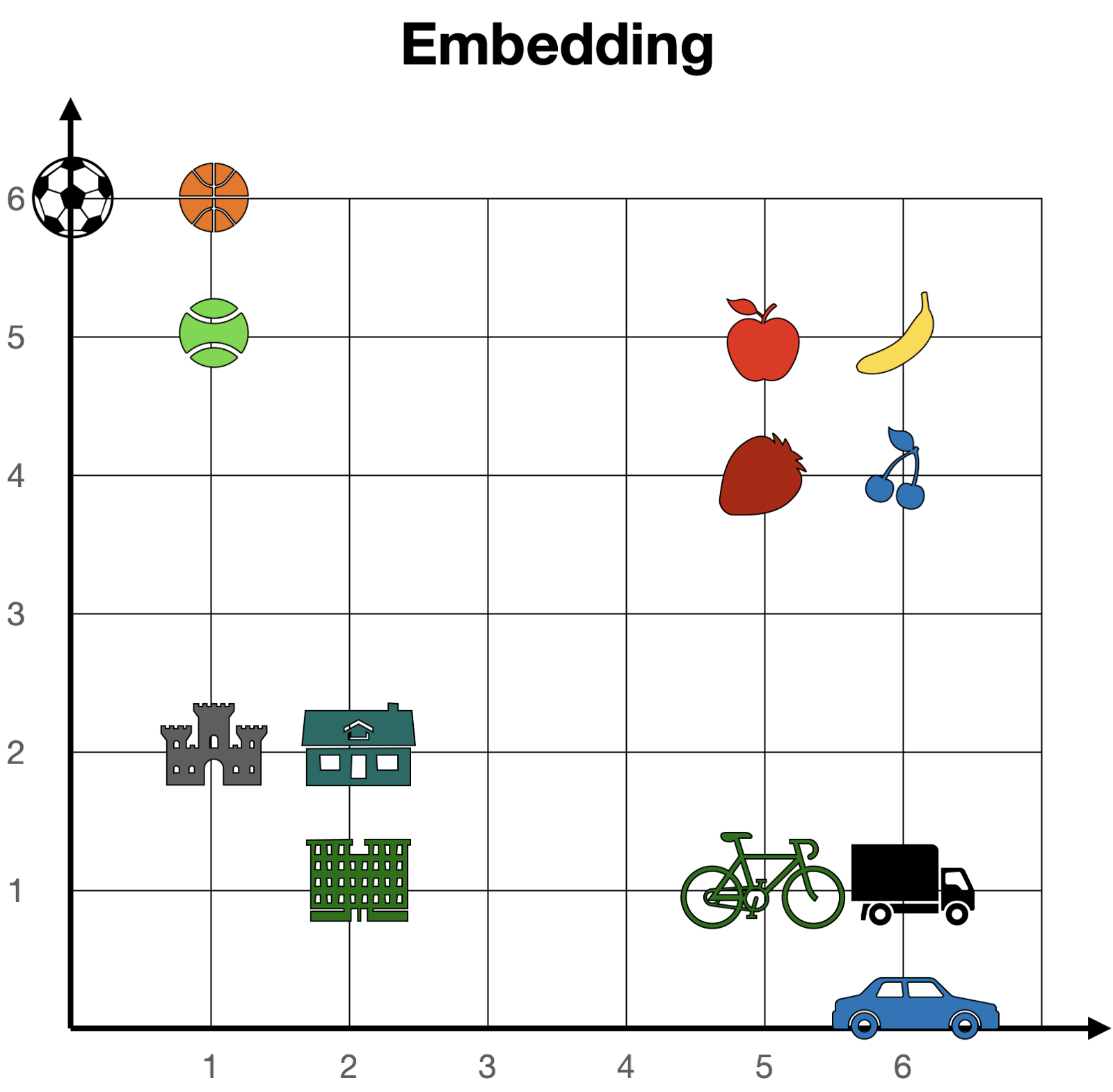
在更大的embedding情况下,每个单词都被赋值到一个更长的向量(比如长度为4096),那么这些单词不再存在于二维平面上,而是存在于一个大的4096维空间中。然而,在这个高维大空间中,我们仍然可以认为单词之间有近有远,因此embedding概念仍然具有意义。
词embedding可以推广到文本embedding,包括整个句子、段落甚至更长的文本都会被赋值到一个向量中。然而,在transformer的情形中,我们将使用词嵌入,这意味着句子中的每个单词都会被赋值到相应的向量中。更具体地说,输入文本中的每个token都将被定位到其对应的embedding向量中。
例如,如果我们正在考虑的句子是“Write a story.”并且标记是

Positional encoding(位置编码)
一旦我们获得了与句子中每个token对应的向量,下一步就是将它们全部转换为一个向量进行处理。将一堆向量转换为一个向量最常见的方法是逐分量相加。也就是说,我们单独添加每个坐标。例如,如果这些(长度为2)向量分别是[1,2]和[3,4],则它们对应的总和为[1+3, 2+4],即[4,6]。这种方法可以工作,但有一个小细节需要注意:加法满足交换律,也就是说如果你以不同顺序添加相同的数字,则会得到相同的结果。在这种情况下,“我不难过我很开心”和“我不开心我很难过”两句话将得到相同的向量结果(假设它们具有相同单词但顺序不同)。这并不好。因此我们必须想出一些方法来给出两个句子不同的向量表示方式。多种方法可行,在本文中我们选择其中之一:位置编码(Positional Encoding) 。位置编码包括将预定义序列中的一系列向量添加到单词嵌入(embedding) 向量上去,并确保我们获得每个句子都有唯一表示形式且具有相似语义结构、仅单词顺序不同的句子将被分配到不同的向量。在下面的示例中,“Write”、“a”、“story”和“.”所对应的向量成为带有位置信息标签“Write(1)”,“a(2)”,“story(3)”和“. (4)”的修改后向量。
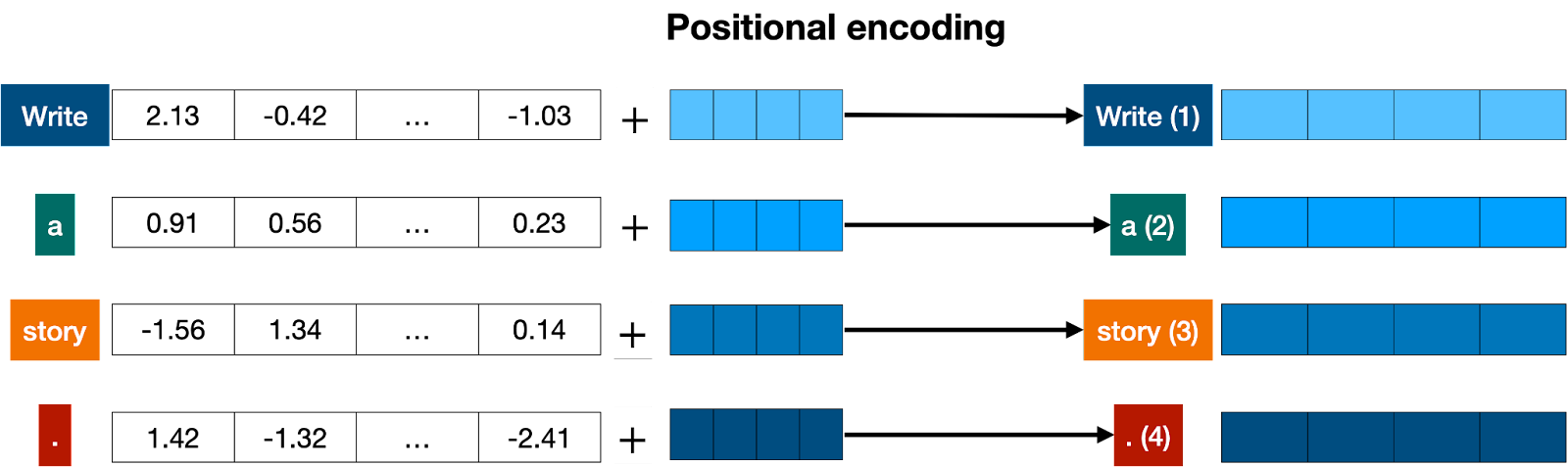
现在我们知道每个句子都有一个独特的向量,这个向量携带了句子中所有单词及其顺序的信息,因此我们可以进入下一步。
Transformer block
让我们回顾一下目前为止的内容。单词被输入并转换成token(分词),然后考虑到它们的顺序(位置编码)。这给了我们每个输入模型的token一个向量。现在,下一步是预测这个句子中的下一个单词。这是通过一个非常大、非常复杂的神经网络来完成的,该网络专门训练用于预测句子中的下一个单词。
我们可以训练这样一个大型网络,但是通过添加关键步骤:Attention(注意力)组件,我们可以极大地改进它。在开创性论文《Attention is All you Need》中引入的注意力机制是Transformer模型的关键成分之一,也是它们如此有效的原因之一。下面将解释注意力机制,但现在先想象它作为一种向文本中每个单词添加上下文的方式。
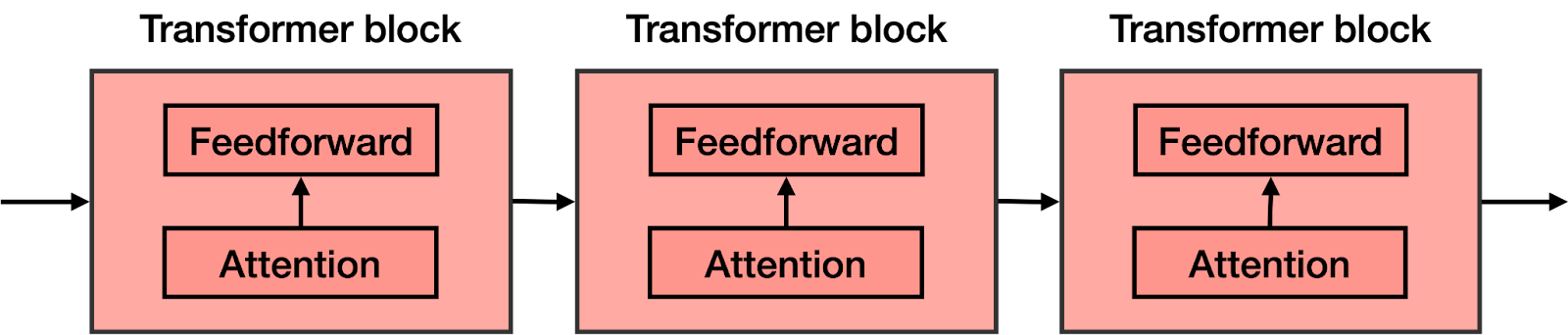
在前馈网络的每个块中都添加了注意力组件。因此,如果您想象一个大型前馈神经网络,其目标是预测下一个单词,并由几个较小的神经网络块组成,则在每个这些块中都添加了注意力组件。然后,Transformer的每个组件(称为transformer 块)由两个主要组件构成:
- 注意力组件
- 前馈组件
Transformer是许多Transformer块的串联。
Attention
Attention步骤涉及一个非常重要的问题:上下文问题。有时,同一个单词可以用不同的意思。这往往会让语言模型感到困惑,因为embedding只是将单词赋值到向量中,而不知道他们使用的单词定义。
Attention是一种非常有用的技术,可以帮助语言模型理解上下文。为了理解Attention的工作原理,请考虑以下两个句子:
句子1: The bank of the river
句子2: Money in the bank.
正如您所看到的,单词“bank”在两个句子中都出现了,但含义不同。在第一个句子中,我们指的是河流旁边的土地,在第二个句子中则指持有货币的机构。计算机对此一无所知,因此我们需要以某种方式将这些知识注入其中。什么能帮助我们呢?好吧,似乎句子中其他单词可以拯救我们。对于第一个句子,“the”和“of”这些单词对我们没有任何作用。但是,“river”这个单词让我们知道正在谈论河流旁边的土地。同样,在第二个句子中,“money”这个单词让我们明白“bank”的意思现在是指持有货币的机构。

简而言之,注意力机制的作用是将句子(或文本片段)中的单词在词嵌入中靠近。这样,在句子“Money in the bank”中,“bank”一词将被移动到“money”的附近。同样,在句子“The bank of the river”中,“bank”一词将被移动到“river”的附近。这样,两个句子中修改后的单词“bank”都会携带周围单词的某些信息,为其添加上下文。
Transformer模型中使用的注意力机制实际上更加强大,它被称为多头注意力。在多头注意力中,使用了几个不同的嵌入来修改向量并为其添加上下文。多头注意力已经帮助语言模型在处理和生成文本时达到了更高的效率水平。如果您想更详细地了解注意力机制,请查看这篇博客文章及其相应视频。
The Softmax Layer
现在你已经知道一个transformer是由许多层transformer块组成的,每个块都包含一个attention和一个feedforward层,你可以将它看作是一个大型神经网络,用于预测句子中的下一个单词。Transformer为所有单词输出分数,其中得分最高的单词被赋予最有可能成为句子中下一个单词的概率。
Transformer的最后一步是softmax层,它将这些分数转换为概率(总和为1),其中得分最高对应着最高的概率。然后我们可以从这些概率中进行采样以获取下一个单词。在下面的例子中,transformer给“Once”赋予了0.5的最高概率,并给“Somewhere”和“There”赋予了0.3和0.2 的概率。一旦我们进行采样,“once”就被选定,并且那就是transformer 的输出结果。
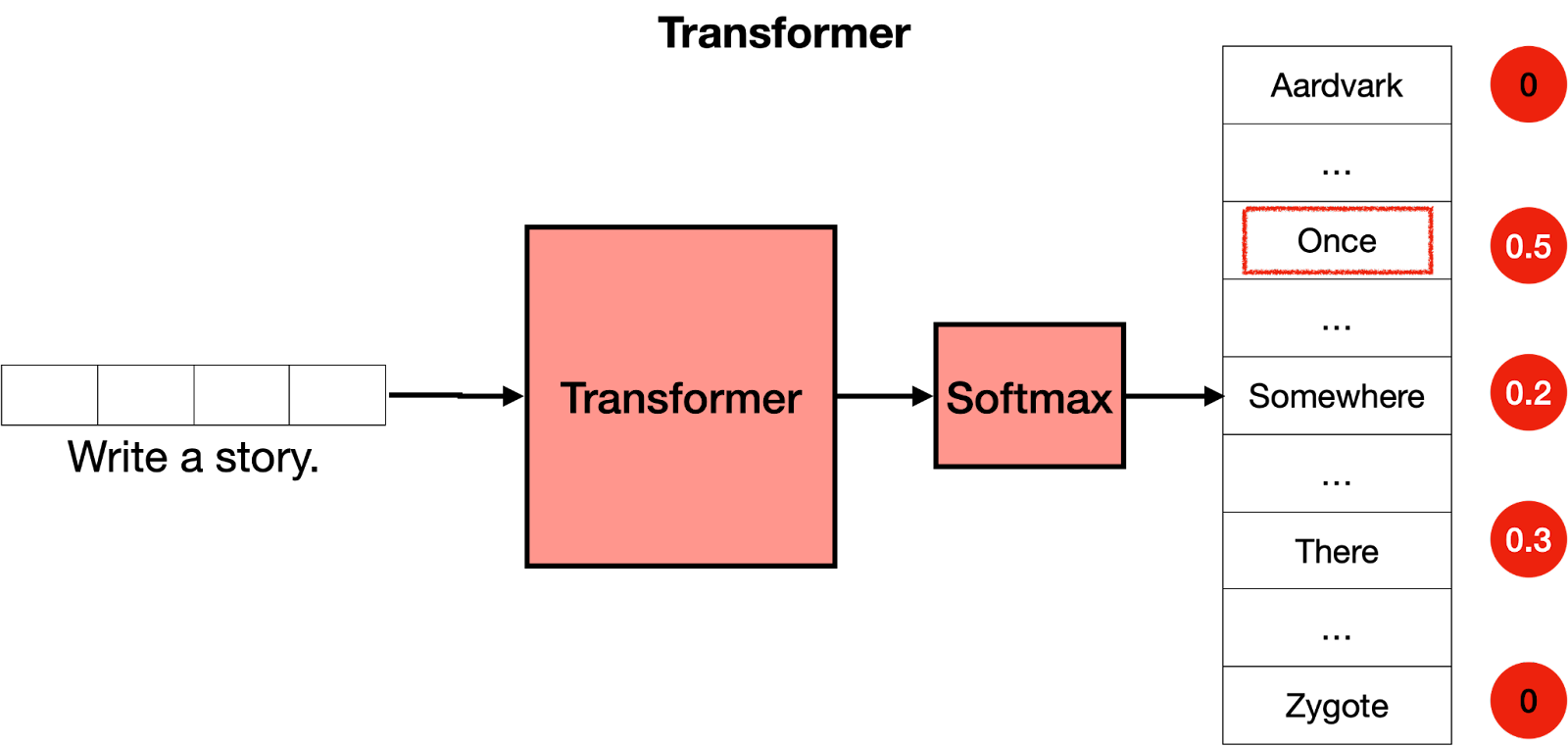
现在怎么办?好的,我们重复这个步骤。现在我们将文本“Write a story. Once”输入模型中,很可能输出结果是“upon”。再次重复此步骤,Transformer最终会写出一个故事,例如:“Once upon a time, there was a …”(“从前有一天,有一个……”)。
Summary总结
在这篇文章中,您已经学习了transformers的工作原理。它们由几个块组成,每个块都有自己的功能,共同工作以理解文本并生成下一个单词。这些块如下:
Tokenizer:将单词转换为token。
Embedding:将token转换为数字(向量)。
Positional encoding:在文本中添加单词顺序。
Transformer block:猜测下一个单词。它由注意力块和前馈块组成。
Attention:为文本添加上下文信息。
Feedforward:是Transformer神经网络中的一个模块,用于猜测下一个单词。
Softmax函数: 将得分转换为概率以便采样出下一个单词。
重复执行这些步骤就可以写出您所看到的transformers创建的惊人文本。
Post Training(后期训练)
现在你已经知道了Transformer是如何工作的,但我们还有一些工作要做。想象一下:你扮演Transformer,“阿尔及利亚的首都是什么?” 我们希望它回答“阿尔及尔”,然后继续进行。然而,这个Transformer是在整个互联网上训练出来的。互联网很大,并不一定是最好的问题/答案库。例如,许多页面会列出长长的问题列表而没有答案。在这种情况下,“阿尔及利亚的首都是什么?”之后的下一个句子可能会是另一个问题,比如“阿尔及利亚人口数量?”,或者“布基纳法索首都在哪里?”。 Transformer不像人类那样思考他们的回应,它只是模仿它看到过(或提供过)数据集中所见到内容。
那么我们该怎样使Transformer回答问题呢?
答案就在于后期训练。就像您教导一个人完成某些任务一样,您可以让Transformer执行任务。 一旦将Transformer训练成整个互联网上使用时,则需要再次对其进行大量数据集培训以涉及各种问题和相应答案。Transformer(就像人类一样)对他们最后学到的事情有偏见,因此后期训练已被证明是帮助Transformer成功完成所要求任务的非常有用的步骤。
后期训练还可以帮助处理许多其他任务。例如,可以使用大量对话数据集来进行Transformer的后期培训,以使其作为聊天机器人表现良好,或者帮助我们编写故事、诗歌甚至代码。
了解更多
如上所述,这是一个概念性的介绍,让您了解transformers如何生成文本。如果您想要深入了解transformer背后的数学原理,请观看以下视频(YouTube)。
写在最后
正如你所看到的,Transformer的架构并不复杂。它们是由几个块连接而成,每个块都有自己的功能。它们之所以能够工作得如此出色,主要原因在于它们具有大量参数,可以捕捉上下文中许多方面的信息。我们很期待看到您使用Transformer模型构建什么!



