这可能是有史以来最大的变革
AI会把人类的工作抢完?
这波AI巨浪是由OpenAI掀起的,ChatGPT就是那个炸起巨浪的炸弹。通过ChatGPT这类对话式应用的使用,我相信大部分朋友都已经知道了这波AI和以前很不一样,这次不开玩笑!

看看红杉资本去年发的一篇AI将逐步取代人类工作的预测,以目前全球AI军备竞赛的状况来看,极有可能会到来的更快。到2030年,以下工作会被取代:
- 文字工作:影响到绝大部分的办公室白领,但是别担心,只要老板还是个人,他会留几个人聊聊天的;
- 编程和计算:影响到程序员、架构师、数据库工程师等等;
- 美术和设计:UI设计师、建筑设计师、非顶级艺术家、摄影师等等;
- 视频、3D制作与游戏开发:电影工作者、3D制作工程师,以及游戏设计和开发人员。
那么问题就来了:我们的孩子们怎么办?
他们现在学的,大差不差还是我们以前学的内容,但是他们面临的工作可不是我们出社会时面对的工作了,虽然长期来看AI可以让人类更少工作、更多获得。两次工业革命、一次信息化革命,至少没有让现有知识体系产生动摇,相反让知识体系变得更加重要,学历就变得尤为重要。但这次(算第四次)革命却一锤一锤地在敲碎人类几千年的知识体系。
这个问题也困扰了我好些时间,最终,我觉得自己就做个AI降临派吧——去融入,去拥抱,去理解LLMs(大语言模型)、在工作中使用AI去提升工作,比如用好Prompt。我觉得自己学习都还不晚,那孩子们就更不用担心了,他们会深度使用好AI,就像我们熟练使用计算机和汽车一样。
不做砸珍妮纺纱机的人
好吧,那就先保持自己不落后。

我觉得目前的AI就像一个从未见过的新机器,从人类以前没有想象过的方式和速度呼啸而来。我们不能等到一年后才后知后觉,那时候已经追不上了…
我们需要现在就开始,从了解底层的技术——大模型开始,再来看看我们需要怎么去拥抱AI。
各类大模型概览
首先我们来看大模型。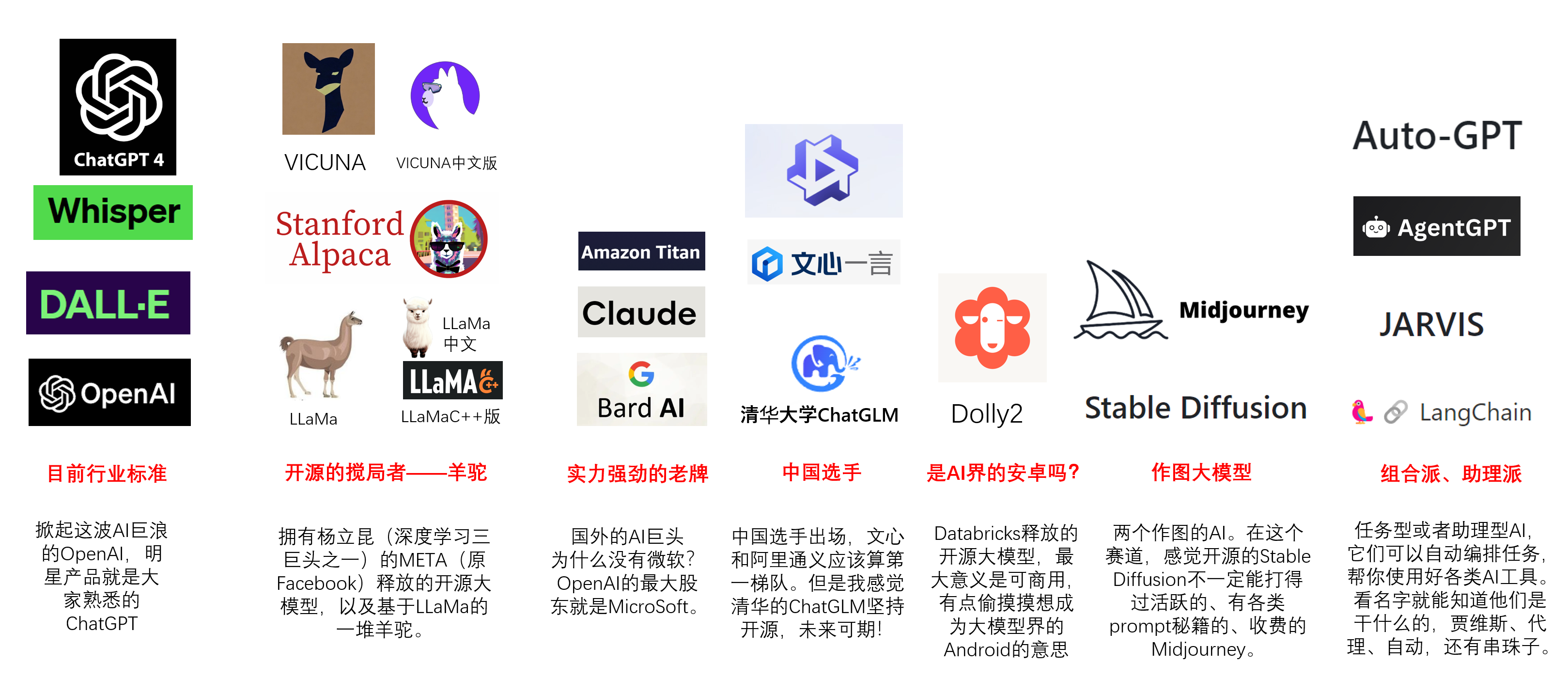
这是我自己整理的目前大模型分类,当然了肯定不止这些,但是这些对我来说相对熟悉,且本身也具备一定代表性。
行业标准OpenAI
这次冲在最前面的大模型是基于GPT(Generative Pre-trained Transformer,基于Transformer的生成式预训练模型)的GPT-3.5、GPT-4。这些模型的基础信息我就不多说了,大家可以参考之前的文章(#链接)。
OpenAI的产品当然不止ChatGPT,他们还有作图的DALL·E、语音转文字的Whisper,以及自动代码工具等。
OpenAI在GPT-2的时候是开源的,但是到GPT-3之后就闭源了,目前外界不知道OpenAI目前的最高能力已经到什么层度了,他们是这一波潮流的引领者。
搅局者LLaMa
目前在OpenAI的开源对手里面,最活跃的是Meta(原Facebook)出品的LLaMa大模型,他们拥有7B(70亿参数,后同)、13B、33B和65B等多个版本,能力也是依次上升,但是硬件要求也会越来越高。作为拥有深度学习三巨头之一杨立昆的Meta,本来应该是想在AI大模型界当一个Android的,那个最大的“在野党”,就像现在Android之于iOS。但是LLaMa目前申请权重文件非常麻烦(虽然其实已经泄露),加上不能直接用于商业,所以在商业公司层面上已经有一丝丝降温。
基于LLaMa的升级很多,先是有斯坦福大学主导的升级版——Alpaca,再是一直在宣传多么厉害多么厉害、几个大学联合制作的Vicuna。因为LLaMa的商用问题,所以我就没有去下载部署,只是在线试用了LLaMa的集大成者Vicuna。就中文来说,Vicuna可不咋滴,当然了,如果是本地部署,不断训练,肯定是会明显好于现在的能力。
另外,LLaMa大模型还有比较多的中文版或LoRA版(可以理解为简配版,为了大家更容易在消费级显卡上炼丹),比如用C++重新做了一遍的LLaMa.cpp,听说效率提升了不少。还有LLaMa的中文版,专门喂了很多中文预料来训练的,就是Chinese-LLaMa-Alpaca,还未亲测。Vicuna也有中文版,大家有兴趣可以下载安装试试,反正我对LLaMa一类的,还是继续观望,等它可以商用再说吧。
老牌劲旅
这次AI大爆发的一个核心技术组件是Transformer,它很好地解决了机器的长期记忆的问题,这个技术的发明者就是Google。但是Google却在后来移情别恋,以至于OpenAI用了大量Google挖过来的人,发布了ChatGPT之后才发觉事情不妙,仓促发布了Bard。虽然我觉得就技术和数据来说,Google都是有希望追上来的,但是他们的现有业务会不会限制他们在AI上发力(毕竟这和搜索肯定是有直接冲突的),这是一个创新者的窘境。
另外一家目前已经很不错的老牌劲旅是Claude,而且现在Claude提供免费API与Slack结合,对OpenAI已经有一些冲击了。
对于亚马逊来说,他们的Titan肯定还是基于云,买买买,我都能服务。
中国选手
下面出场的是中国选手,网络上已经有一张图了,展示了十多家国内的参赛选手。但是仔细来看,目前可申请试用的应该自有百度的文心一言和阿里的通义千问。
百度有丰富的搜索数据,加上有陆奇、吴恩达等多位货真价实的国际顶级大牛,还是有一些积累的,应该是村里面第一个站出来的人。只是前面可能更多的方向是在无人驾驶(更多是在感知智能),而忘了点认知智能的科技树。
阿里这次动作有点迅速,这一块感觉并不是阿里强项,虽然同样拥有足够的数据,拥有TensorFlow和Pytorch1.0的作者之一贾扬清(已离开阿里)。
目前外界最看好的第三家可以站出来是字节跳动,有钱、有数据、有用户,还有人才。
至于其他的公司,感觉都还是比较难的,这件事情,再去找开源模型包个壳其实意义不大,因为这里还要涉及到数据、算力和训练,以及工程化地调优。数据把一大众公司挡在门外了,然后算力又把另一家巨头挡住。最后,很多公司是真的没有技术、没有人才密度的,拿项目也许没问题,但是这种拼硬实力的事情,怎么可能做得成。
这次清华大学无愧国内NO.1的存在,推出的ChatGLM还不错,特别是对于中文的支持。我自己部署了ChatGLM-6B的模型,在我的RTX-4090上跑起来还是很顺畅的,但是也只能先玩着了,因为听到他们7位数的授权费,感觉为了后面不吃官司,还是要提早找一个可商用的大模型练起来。
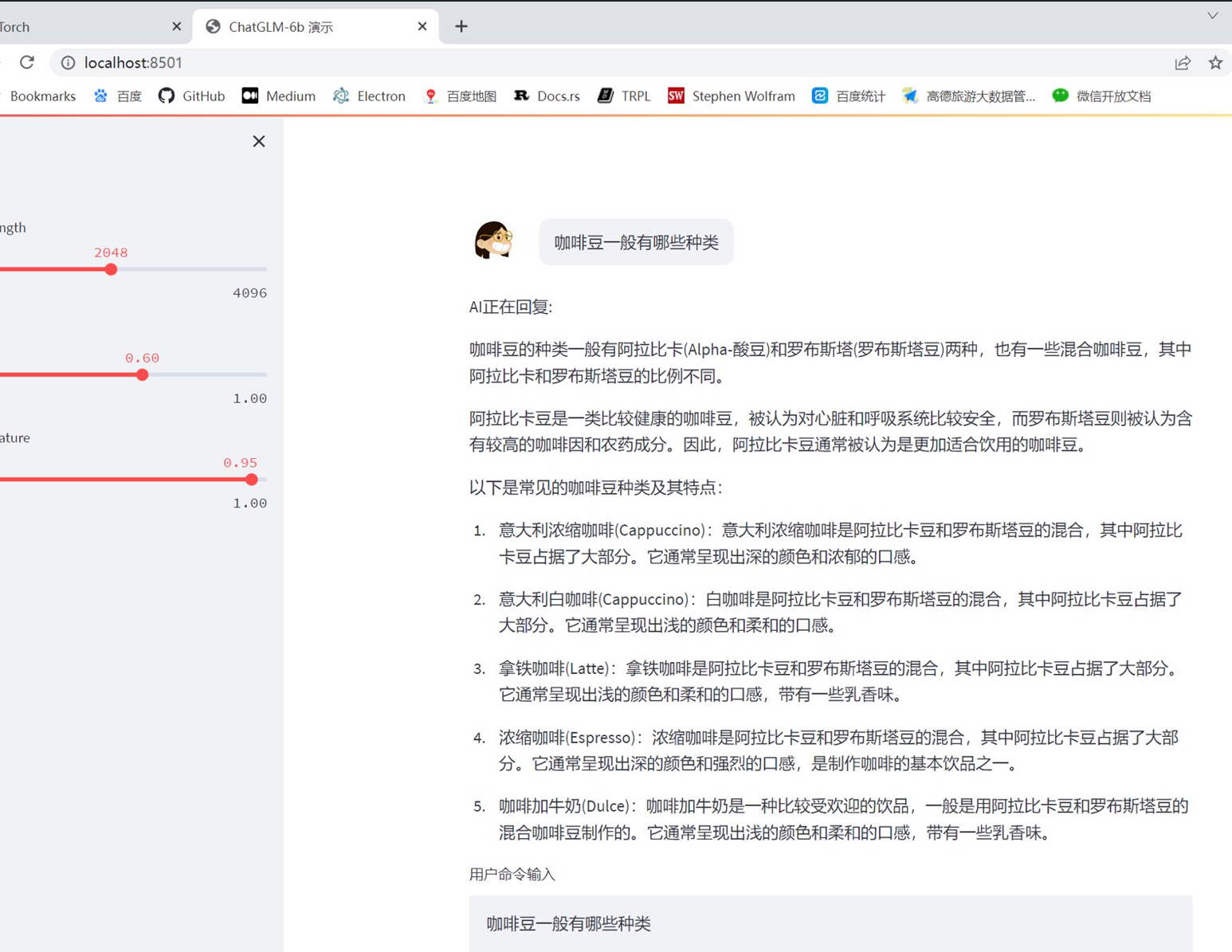
第一个可商用的开源大模型
这周,第一个可商用大模型它就来了,是Databricks发布的Dolly2.0。首先介绍一下Databricks,它最著名的产品就是Spark,对的,就是那个Apacha Spark。

说回Dolly2,为什么它可以商用的?先从LLaMa系列大模型为什么不能商用说起。
大模型的技术开发原理其实对于大部分顶尖公司来说不难,因为前面说了GPT-2是开源的,而且牛逼的公司可以根据Google、OpenAI等发布的论文中描述的技术原理开发出大模型。但是,训练却很难,最大的问题就是训练数据,据说OpenAI里面30%的人是在做数据标准、校验等工作,而且在训练ChatGPT的时候,ChatGPT还采用众包方式,让大量肯尼亚人参与数据处理,花费了不少钱。而LLaMa、Alpaca和Vicuna等都使用了ChatGPT去获得非常有价值的原始数据(问题与配对的答案),等于转载使用,所以存在商业化问题。
而Dolly呢?他们在Dolly1的时候也是使用ChatGPT来获得训练数据的,所以依然无法商业。于是,Databricks做了一个大胆的尝试,让公司的5000员工去想,不能借助ChatGPT,也不能直接去其他网站是抄版权内容,全部要自己想,还要保证质量,为此他们还办了个内部比赛。就这样,Databricks在一周内完成1.5万条数据,平均每人3条,因此,他们的这个模型是可以商业的。这个故事在他们的官方博客上有介绍,可以查看。
关于Dolly2,代码可以去Github:databrickslabs/dolly上查看;可商用的模型在Hugging Face:dolly-v2-12b(23G的基于Pytorch的Model)。
目前看到的个别已经部署过的推友评价,中文的处理能力是够呛的,但是咱们不怕啊,数据就是咱们优势啊(后面会讲到是为什么)。
作图模型
Midjouney目前的知名度应该仅次于ChatGPT,作图最好的平台之一,但是真的要用,最好是付费(我已经交了20美元)。
对了,首图就是Midjouney上制作的,还包括下面这张图(一艘GPU飞船):

目前最大对手是开源的Stable Diffusion,可以直接部署在像我这样的消费级显卡上的,而且处理速度极快。当然,在普遍的自动生成图片质量上还是不如Midjouney的。作图这个服务,对于prompt的收集、意见反馈等感觉比ChatGPT还重要,更加需要人类反馈自学习(RLHF)。
AI管家出现
前面说了这么多大模型,都还没说太多基于这些大模型的应用呢,嗯,我也不太想展开来讲应用,太太太多了。
那么面对这么多的AI应用,怎么简便地去使用呢,怎么样能让我写出更好的Prompt呢?
这时候,LongChain就出来了,一种可以自动帮助我们把一个个应用串起来的应用。
然后,微软出了一个Jarvis(贾维斯),听名字你应该知道是什么了;
这几天最火的,当然是Auto-GPT了,一个月不到,github上的stars已经过了6万。
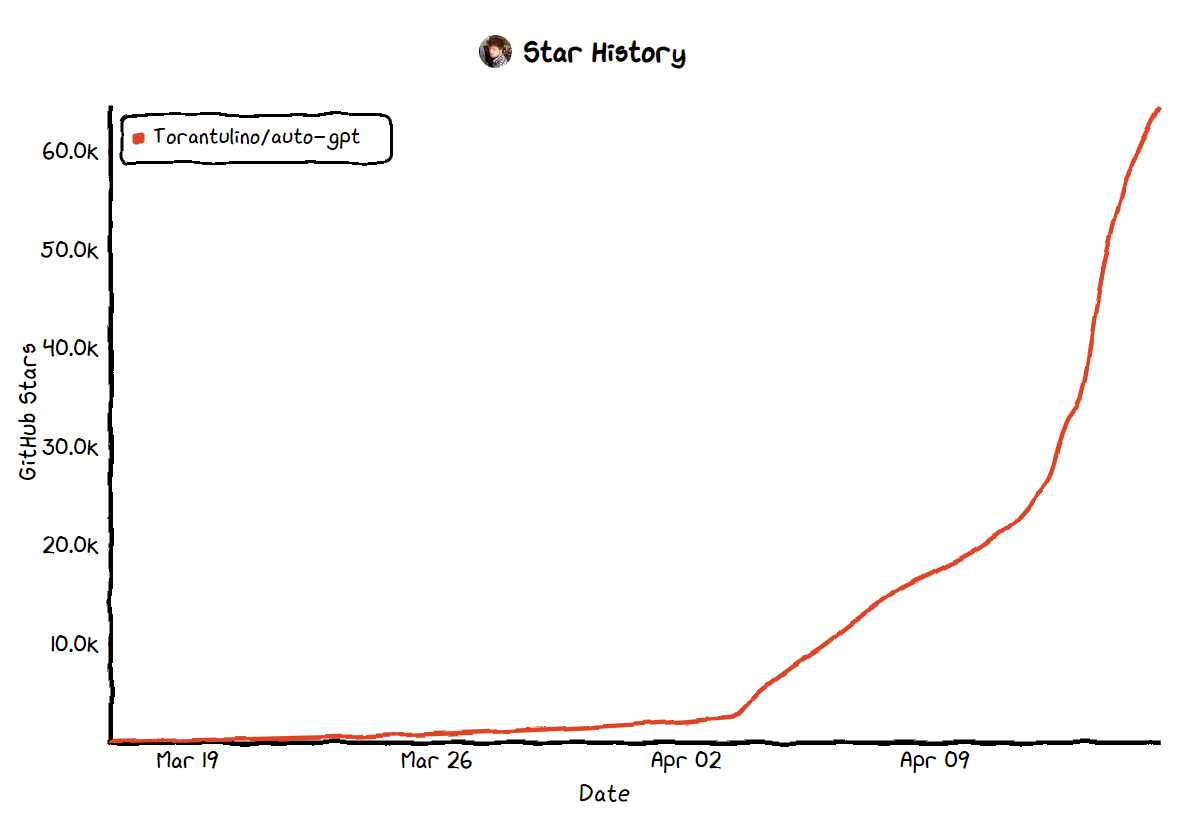
我们有弯道超车的办法
看到上面说了这么多大模型,会不会觉得头麻了。如果你是第一次接触,那就是麻妈给麻子开门,麻到家了!
但是这里面中国企业起步晚,参与少,对于AI这种必然的未来趋势,我们该怎么办呢?有办法像移动互联网一样后发先至吗?
我觉得是有的,这里非常简单的聊一下。
AI这个事情,主要是有三个决定因素:大模型、算力和数据。
大模型今天已经说了,其实开源的肯定也会不断完善,加上相关核心论文是公开的,这方面对我国来说应该不是最大的问题(君不见,国外这一波,华人比例非常之高);
算力应该也不会是长期的问题,芯片这个问题,我就不多谈了,反正这个不会成为长期的问题;
那么剩下的就是数据了。前面也说了,数据非常重要,也是模型“聪明”还是“白痴”最重要的影响因素。国内的弯道超车应该就在这里了。大家应该还有印象,今年的Q1,国家强调了数字化改革,然后由宣布组建国家数据局。我不知道大家怎么看,虽然也看到一些冷嘲热讽,但是我觉得国家数据局最终的目的是要把国内大部分的重要领域的数据都要收集上来。然后(我yy一下),进行大模型的训练。如果有充分详实的数据,以后很多事情就好办了。比如问“怎么让杭州市民用更低的价格,或者更丰富更便宜的菜品?” 如果是数据充分的AI大模型,会给出好几条方案,其中可能有(依然是yy,内容上别当真)“增加安徽、山东到杭州的高速公路建设,增加蔬菜、肉类等食材的供给,中间涉及到XX个县,根据当前土地补贴政策,整个工程造价XXXX”。
然后呢,我觉得可能只有中国在数据量(看看移动互联网我们是怎么用的,各地支付、遍地小哥)、数据汇总组织统筹能力上都是最佳的,所以在数据这个事情上,我们是可以后发先至,弯道超车的。
东市买骏马,西市买鞍鞯
对于个人呢,前面说了,要先扒上这趟车,不能再等等,等等就可能追不上了。
对于有编程基础的朋友,可以恢复Python的学习、Pytorch的学习等,把大模型研究起来,开发个基于大模型的应用玩玩;
对于产品经理,每天你需要花一个小时去看看这个世界在AI领域发生了什么,借助AI,甚至可以将所有应用重做一遍;
对于所有人,如果我今天说的大部分内容你都没有听过,那你已经接近被时代甩远的危险了,找资料好好学。比如书、比如博客,也有类似极客时间这类,大家也可以看看,每天上下班都可以听,真的别落后了。


上周末,花了22400元攒了台主机,主要是为了那块RTX4090。有句话是“要做瓷器活,先要有金刚钻”,所以这台电脑,要买!
AI是一个新时代的战场,个人玩家也可以玩,但是,先准备好你的装备吧。木兰诗:“东市买骏马,西市买鞍鞯”,买好上战场了!
这是微信公众号的文章链接:土猛的员外



